This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However I think journals such as ComputationalLinguistics and TACL could adjust reviewing procedures to check some of above. We only looked at human evaluations, but I suspect the problem may be just as bad with metric evaluations (eg see Arvan et al (2022) ). ComputationalLinguistics. Unfortunately.
ACL 2022 took place in Dublin from 22nd–27th May 2022. Language diversity and multimodality Panelists and their spoken languages at the ACL 2022 keynote panel on supporting linguistic diversity. This was my first in-person conference since ACL 2019. This is also my first conference highlights post since NAACL 2019.
In Proceedings of the 2022 Conference of the North American Chapter of the Association for ComputationalLinguistics: Human Language Technologies, pages 1115–1127, Seattle, United States. Association for ComputationalLinguistics. Association for ComputationalLinguistics.
Just wait until you hear what happened in 2022. Dall-e , and pre-2022 tools in general, attributed their success either to the use of the Transformer or Generative Adversarial Networks. In 2022 we got diffusion models ( NeurIPS paper ). This was one of the first appearances of an AI model used for Text-to-Image generation.
The 60th Annual Meeting of the Association for ComputationalLinguistics (ACL) 2022 is taking place May 22nd - May 27th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below.
She is currently the president of the Association of ComputationalLinguistics. In 2022, she received an ERC Advanced Grant to support her vision for the next big step in NLP, “InterText — Modeling Text as a Living Object in a Cross-Document Context.”
EMNLP 2022. EMNLP 2022. NeurIPS 2022. EMNLP 2022. EMNLP 2022. They show performance improvements in some settings and speed improvements in all evaluated settings, showing particular usefulness in settings where the LLM needs to retrieve information about multiple entities (e.g. UC Berkeley, CMU. Google Research.
This post is partially based on a keynote I gave at the Deep Learning Indaba 2022. Linguistic and demographic global utility metrics for a number of language technology tasks. Overall, however, we observe very low linguistic utility numbers, showing an unequal performance distribution across the world's languages.
For instance, in April 2022, DeepMind introduced Flamingo, a visual language model that can seamlessly ingest text, images and video. [5] In Proceedings of the 58th Annual Meeting of the Association for ComputationalLinguistics , pages 5185–5198, Online. Association for ComputationalLinguistics. [2] 2212.08120.
We’re kind of at the point where we can make fire but do not even have the rudiments of what we’d need to understand it,” my friend Luke Gessler , a computationallinguist, told me. We have no reason to believe any current AIs are sentient, but we also have no way of knowing whether or how that could change.
70% of research papers published in a computationallinguistics conference only evaluated English.[ In Findings of the Association for ComputationalLinguistics: ACL 2022 , pages 2340–2354, Dublin, Ireland. Association for ComputationalLinguistics. Association for ComputationalLinguistics.
2022; Levine et al., arXiv preprint arXiv:2201.07763 (2022). In Findings of the Association for ComputationalLinguistics: EMNLP 2020 , pp. 2020; Awad et al., Learning to ask the right questions We use Reinforcement Learning (PPO) to train our question generation system. When is it acceptable to break the rules?
For modular fine-tuning for NLP, check out our EMNLP 2022 tutorial. We cover such methods for NLP in our EMNLP 2022 tutorial. This post gives a brief overview of modularity in deep learning. For a more in-depth review, refer to our survey. For more resources, check out modulardeeplearning.com. These models are monoliths.
arXiv preprint arXiv:2210.11416 (2022). [2] Proceedings of the 56th Annual Meeting of the Association for ComputationalLinguistics (Volume 2: Short Papers). “Scaling instruction-fine tuned language models.” 2] Rajpurkar, Pranav, Robin Jia, and Percy Liang. Know What You Don’t Know: Unanswerable Questions for SQuAD.”
It also requires developing models for which the input does not exist in a vacuum but is grounded to extra-linguistic context and the real world. For more work on this topic, check out the EvoNLP workshop at EMNLP 2022. Transactions of the Association for ComputationalLinguistics, 9, 978–994. Schneider, R.,
He presented “Toward Superhuman Communication Assistance” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That ranges all the way from analytical and computationallinguists to applied research scientists, machine learning engineers, data scientists, product managers, designers, UX researchers, and so on.
He presented “Toward Superhuman Communication Assistance” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That ranges all the way from analytical and computationallinguists to applied research scientists, machine learning engineers, data scientists, product managers, designers, UX researchers, and so on.
2019 Annual Conference of the North American Chapter of the Association for ComputationalLinguistics. [7] 57th Annual Meeting of the Association for ComputationalLinguistics [9] C. 2022) Shtetl-Optimized: The Blog of Scott Aaronson. [11] Resources and References [1] A. OpenAI [4] E. Mitchell, Y. Weigreffe, Y.
2018 saw the launch of the Asia-Pacific Chapter of the Association for ComputationalLinguistics (AACL), which is organising its first conference next year (co-located with IJCNLP) in Suzhou, China. One good reason to take our major conferences to new countries is to equalise the barrier of obtaining visas to attend.
Trends Human Computer Interaction. [2] In Proceedings of the 60th Annual Meeting of the Association for ComputationalLinguistics (Volume 1: Long Papers). [3] In CHI Conference on Human Factors in Computing Systems. [5] In Proceedings of the 58th Annual Meeting of the Association for ComputationalLinguistics.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



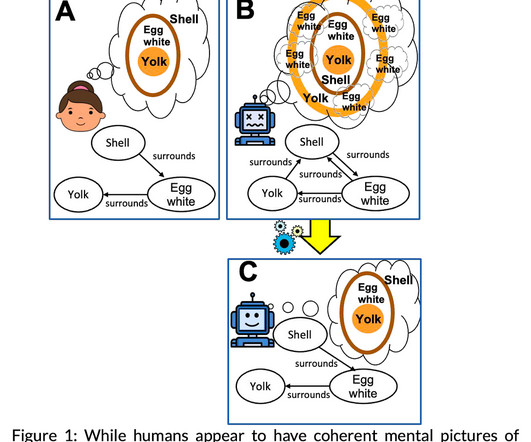


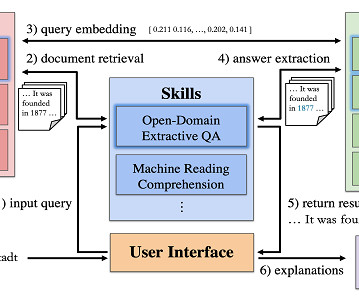


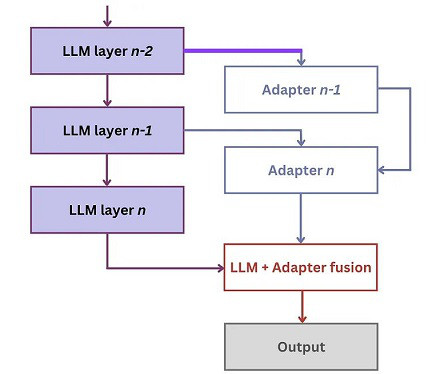


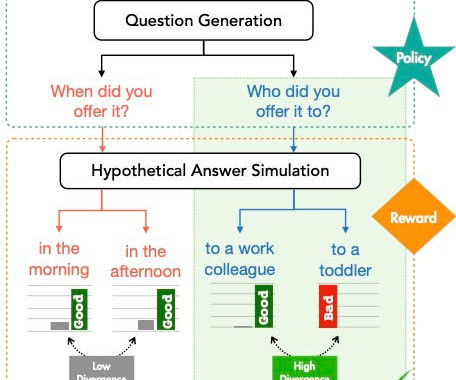

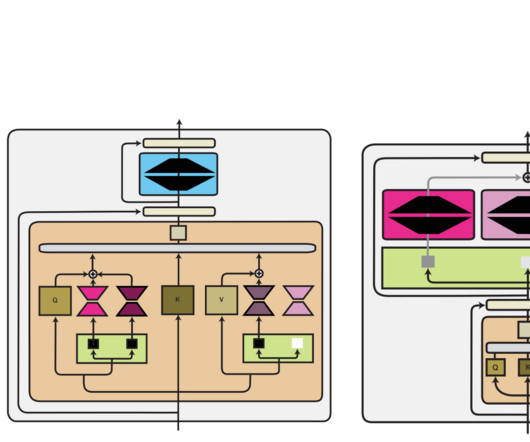
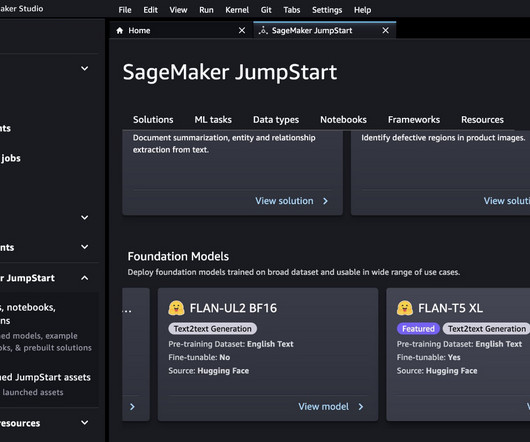

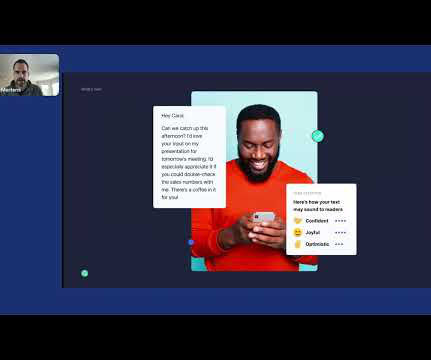






Let's personalize your content