This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In 2022, we continued this journey, and advanced the state-of-the-art in several related areas. We also had a number of interesting results on graph neural networks (GNN) in 2022. Top Market algorithms and causal inference We also continued our research in improving online marketplaces in 2022.
In 2022, we focused on new techniques for infusing external knowledge by augmenting models via retrieved context; mixture of experts; and making transformers (which lie at the heart of most large ML models) more efficient. Google Research, 2022 & beyond This was the fourth blog post in the “Google Research, 2022 & Beyond” series.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
2022), and Ram et al. 2022), GTE by Li et al. 2022), remain behind closed doors. Initially, a Masked Language Modeling Pretraining phase utilized resources like BooksCorpus and a Wikipedia dump from 2023, employing the bert-base-uncased tokenizer to create data chunks suited for long-context training.
A 2022 CDP study found that for companies that report to CDP, emissions occurring in their supply chain represent an average of 11.4x In simpler terms, these emissions arise from external sources, such as emissions associated with suppliers and customers and are beyond the company’s core operations.
In 2022, we expanded our research interactions and programs to faculty and students across Latin America , which included grants to women in computer science in Ecuador. See some of the datasets and tools we released in 2022 listed below. We work towards inclusive goals and work across the globe to achieve them.
AllenNLP Embeddings Strengths: NLP Specialization: AllenNLP provides embeddings like BERT and ELMo that are specifically designed for NLP tasks. MultiLingual BERT is a versatile model designed to handle multilingual datasets effectively. It provides an embedding dimension of 768 and a substantial model size of 1.04
Almost thirty years later, upon Wirths passing in January 2024, lifelong technologist Bert Hubert revisited Wirths plea and despaired at how catastrophically worse the state of software bloat has become. The company, which started in 2022 with 4 employees, stumbled upon the idea of AI-powered search in a Slack channel.
of nodes with text-features MAG 484,511,504 7,520,311,838 4/4 28,679,392 1,313,781,772 240,955,156 We benchmark two main LM-GNN methods in GraphStorm: pre-trained BERT+GNN, a baseline method that is widely adopted, and fine-tuned BERT+GNN, introduced by GraphStorm developers in 2022. Dataset Num. of nodes Num. of edges Num.
AllenNLP Embeddings Strengths: NLP Specialization: AllenNLP provides embeddings like BERT and ELMo that are specifically designed for NLP tasks. MultiLingual BERT is a versatile model designed to handle multilingual datasets effectively. It provides an embedding dimension of 768 and a substantial model size of 1.04
Additionally, the models themselves are created from limited architectures: “Almost all state-of-the-art NLP models are now adapted from one of a few foundation models, such as BERT, RoBERTa, BART, T5, etc.
Overall, $384 billion is projected as the cost of pharmacovigilance activities to the overall healthcare industry by 2022. Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks.
Posted by Malaya Jules, Program Manager, Google This week, the premier conference on Empirical Methods in Natural Language Processing (EMNLP 2022) is being held in Abu Dhabi, United Arab Emirates. We are proud to be a Diamond Sponsor of EMNLP 2022, with Google researchers contributing at all levels.
” BERT/BART/etc can be used in data-to-text, but may not be best approach Around 2020 LSTMs got replaced by fine-tuned transformer language models such as BERT and BART. This is a much better way to build data-to-text and other NLG systems, and I know of several production-quality NLG systems built using BART (etc).
For a BERT model on an Edge TPU-based multi-chip mesh, this approach discovers a better distribution of the model across devices using a much smaller time budget compared to non-learned search strategies. Google Research, 2022 & beyond This was the second blog post in the “Google Research, 2022 & Beyond” series.
Technical Insights The MusicLM leverages the principles of AudioLM , a framework introduced in 2022 for audio generation. An illustration of the pretraining process of MusicLM: SoundStream, w2v-BERT, and Mulan | Image source: here Moreover, MusicLM expands its capabilities by allowing melody conditioning.
We are heavy Google Research posts this week, enjoy specifically the 2022 & Beyond series! Bert paper has demos from HF spaces and Replicate. Libraries MLCommons Algorithmic Efficiency is a benchmark and competition measuring neural network training speedups due to algorithmic improvements in both training algorithms and models.
Since November 2022, LLMs have been used in clinical investigations, pharmacy, radiography, Alzheimer’s illness, agriculture, and brain science research, inspired by the diverse qualities and widespread acclaim of ChatGPT. .
At re:Invent 2022, IBM Consulting was awarded the Global Innovation Partner of the Year and the GSI Partner of the Year for Latin America , cementing client and AWS trust in IBM Consulting as a partner of choice when it comes to AWS. in 10 years, from 2012 to 2022. More than half of algorithms on the U.S.
Natural language processing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. BERT is still very popular over the past few years and even though the last update from Google was in late 2019 it is still widely deployed.
An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages. Fine-tuning multilingual BERT models with AWS Batch GPU jobs We sought a solution to support multiple languages for our diverse user base.
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently. Training a well-performing BERT Large model from scratch typically requires 450 million sequences to be processed. The first uses traditional accelerated EC2 instances.
Just wait until you hear what happened in 2022. Dall-e , and pre-2022 tools in general, attributed their success either to the use of the Transformer or Generative Adversarial Networks. In 2022 we got diffusion models ( NeurIPS paper ). This was one of the first appearances of an AI model used for Text-to-Image generation.
Data were gathered from 911,637 English tweets from November 2022 to January 2023, focusing on various terms related to ChatGPT. Utilizing BERT for sentiment analysis (BERTSentiment) and topic modeling (BERTopic), the study identifies emotional responses and thematic discussions related to ChatGPT.
2022), innovatively adds the phrase “Let's think step by step” to the original prompt. Consider an instance where a Large Language Model (LLM), primed with data before the 2022 World Cup, is given a context indicating that France won the tournament. This approach, introduced by Kojima et al.
The 60th Annual Meeting of the Association for Computational Linguistics (ACL) 2022 is taking place May 22nd - May 27th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below.
In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. run_dp_bert_large_hf_pretrain_bf16_s128.sh"
This is heavily due to the popularization (and commercialization) of a new generation of general purpose conversational chatbots that took off at the end of 2022, with the release of ChatGPT to the public. Thanks to the widespread adoption of ChatGPT, millions of people are now using Conversational AI tools in their daily lives.
In this post he will share some of our ideas about interpretability, introduce the idea of atomic inference, and give an overview of the work in our 2022 and 2024 EMNLP papers [1,2]. Let me walk through our EMNLP 2022 paper to give you a flavour of what atomic inference methods can look like in practice. This sounds intriguing!
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
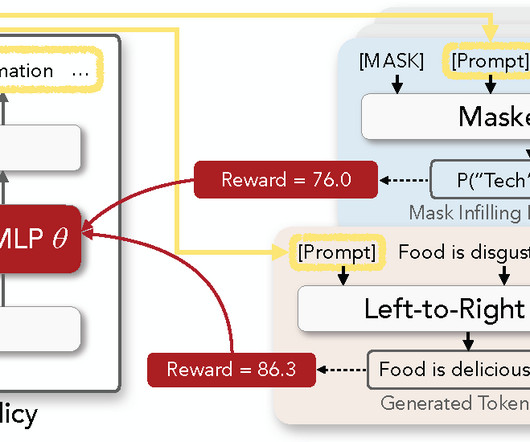
Prompting has emerged as a promising approach to solving a wide range of NLP problems using large pre-trained language models (LMs), including left-to-right models such as GPT s and masked LMs such as BERT , RoBERTa , etc. BERT and GPTs) for both classification and generation tasks. table below), echoing recent research (e.g.,
We’ve used the DistilBertTokenizer , which inherits from the BERT WordPiece tokenization scheme. 2022 (Google Research) propose Canine, a tokenization-free Transformer architecture operating directly on character sequences. Training Data : We trained this neural network on a total of 3.7 billion words). Clark et al.,
EMNLP 2022. EMNLP 2022. NeurIPS 2022. EMNLP 2022. EMNLP 2022. They show performance improvements in some settings and speed improvements in all evaluated settings, showing particular usefulness in settings where the LLM needs to retrieve information about multiple entities (e.g. UC Berkeley, CMU. Google Research.
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. This post is partially based on a keynote I gave at the Deep Learning Indaba 2022. The Deep Learning Indaba 2022 in Tunesia.
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many natural language processing (NLP) tasks. To achieve this, we first chunk each document into segments of roughly 256 tokens, which is half of the maximum BERT LM input length.
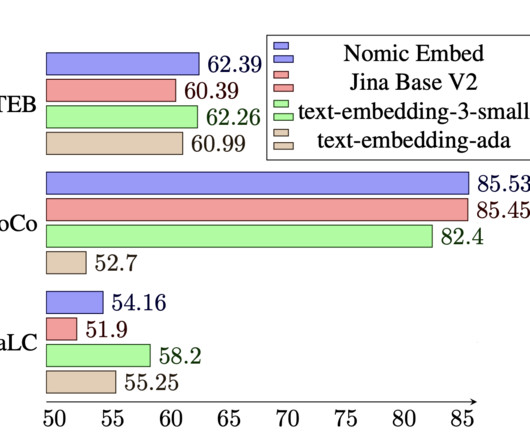
In 2022, Semantic Search dominated the global semantic knowledge graphing market, achieving the highest revenue share. billion in 2022 , highlighting its increasing adoption for improving organisational knowledge discovery and productivity. Start by retraining pre-trained models like BERT or Sentence Transformers with custom datasets.
BERTBERT uses a transformer-based architecture, which allows it to effectively handle longer input sequences and capture context from both the left and right sides of a token or word (the B in BERT stands for bi-directional). This allows BERT to learn a deeper sense of the context in which words appear.
Specifically, it involves using pre-trained transformer models, such as BERT or RoBERTa, to encode text into dense vectors that capture the semantic meaning of the sentences. There is also a short section about generating sentence embeddings from Bert word embeddings, focusing specifically on the average-based transformation technique.
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. What are Vector Embeddings? Pinecone Used a picture of phrase vector to explain vector embedding. All we need is the vectors for the words.
Our integration of ONNX Runtime has already led to substantial improvements when serving our LLM models, including BERT. Models like BERT, DistilBERT, and DeBERTa have revolutionized natural language processing tasks by capturing intricate semantic relationships between words.
With the arrival of pre-trained models such as BERT, fine-tuning pre-trained models for downstream tasks became the norm. 2022 ) : 193k instruction-output examples sourced from 61 existing English NLP tasks. 2022 ) : A crowd-sourced collection of instruction data based on existing NLP tasks and simple synthetic tasks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content