This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
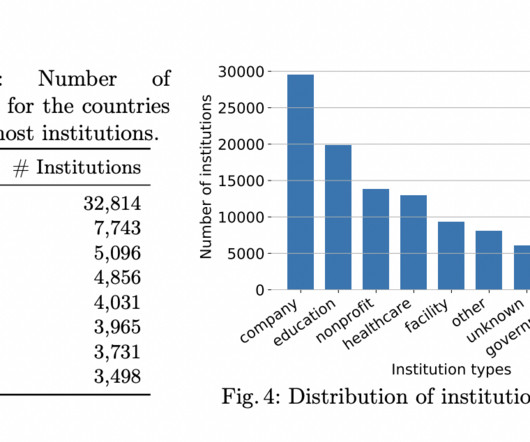
Modeling the underlying academic data as an RDF knowledge graph (KG) is one efficient method. This makes standardization, visualization, and interlinking with LinkedData resources easier. As a result, scholarly KGs are essential for converting document-centric academic material into linked and automatable knowledge structures.
2021), a recently proposed commonsense moral reasoning model, generates moral judgments for simple actions described in text. PDF: [link] Data + Code: [link] References Awad, Edmond, Sydney Levine, Andrea Loreggia, Nicholas Mattei, Iyad Rahwan, Francesca Rossi, Kartik Talamadupula, Joshua Tenenbaum, and Max Kleiman-Weiner.
In 2021 I and some colleagues published a research article on how to employ sentiment analysis on a applied scenario. ALLDATA, The Second Inter-national Conference on Big Data, Small Data, LinkedData and Open Data (2016). Vasiliu, L., Koumpis, A., Mcdermott, R., and Handschuh, S.
For models and datasets , checkout out HuggingFace (HF) page: [link]. NannyML is an open-source python library that allows you to estimate post-deployment model performance (without access to targets), detect data drift, and intelligently linkdata drift alerts back to changes in model performance.
Please refer to this documentation link. Let's pull data from the table historical_prices [link] We can convert the Snowpark DataFrame to Pandas DataFrame [link] View Pricing data [link] Data Preprocessing After data extraction, we will check some basic information & statistics of the dataset.
If your start_date is 2021, then Airflow will start running from this time. link] The next step is to define the variables used and write a Python function for downloading the CSV file, reading it with pandas, and saving it to the Airflow home directory. By default, Airflow will start running a DAG from the start_date.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









Let's personalize your content