
ACL 2021 Highlights
Sebastian Ruder
AUGUST 15, 2021
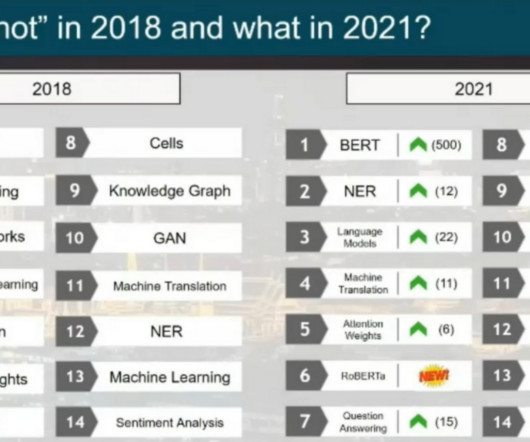
ACL 2021 took place virtually from 1–6 August 2021. These models are essentially all variants of the same Transformer architecture.
Sebastian Ruder
AUGUST 15, 2021
ACL 2021 took place virtually from 1–6 August 2021. These models are essentially all variants of the same Transformer architecture.
Marktechpost
FEBRUARY 17, 2024
2021), Izacard et al. Initially, a Masked Language Modeling Pretraining phase utilized resources like BooksCorpus and a Wikipedia dump from 2023, employing the bert-base-uncased tokenizer to create data chunks suited for long-context training. Recent advancements, as highlighted by Lewis et al. 2022), and Ram et al.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

AWS Machine Learning Blog
FEBRUARY 6, 2024
In 2021, the pharmaceutical industry generated $550 billion in US revenue. Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. The other data challenge for healthcare customers are HIPAA compliance requirements.
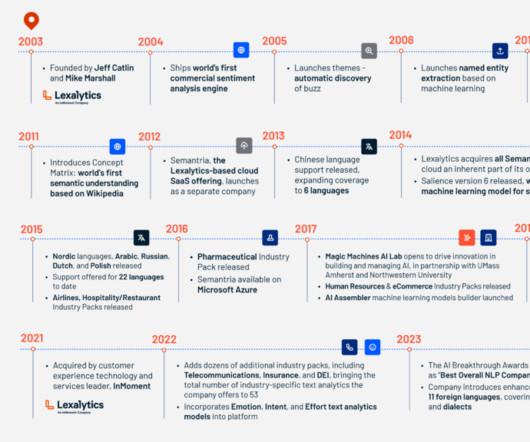
Lexalytics
JULY 12, 2023
And in 2021, we were acquired by leading CX provider InMoment, signaling an acknowledgement in the industry of the growing importance of AI and NLP in understanding and combining all forms of feedback and data.
Mlearning.ai
JUNE 14, 2023
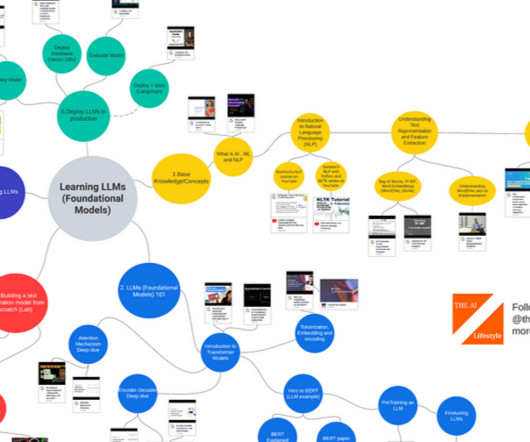
— YouTube Introduction to Sequence Learning and Attention Mechanisms Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 8 — Translation, Seq2Seq, Attention — YouTube Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 7 — Translation, Seq2Seq, Attention — YouTube 2. YouTube BERT Research — Ep.

Topbots
APRIL 11, 2023
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.

Unite.AI
DECEMBER 1, 2023
Flawed Decision Making The opaqueness in the decision-making process of LLMs like GPT-3 or BERT can lead to undetected biases and errors. This presents an inherent tradeoff between scale, capability, and interpretability. Impact of the LLM Black Box Problem 1.

Expert insights. Personalized for you.


































Let's personalize your content