This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. The introduction of word embeddings, most notably Word2Vec, was a pivotal moment in NLP. One-hot encoding is a prime example of this limitation.
Photo by Kunal Shinde on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.09.20 What is the state of NLP? For an overview of some tasks, see NLP Progress or our XTREME benchmark. In the next post, I will outline interesting research directions and opportunities in multilingual NLP.”
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). 2020 ), Turing-NLG , BST ( Roller et al., 2020 ), and GPT-3 ( Brown et al., 2020 ; Fan et al., 2020 ; Fan et al.,
It’s also an area that stands to benefit most from automated or semi-automated machine learning (ML) and natural language processing (NLP) techniques. Semi) automated data extraction for SLRs through NLP Researchers can deploy a variety of ML and NLP techniques to help mitigate these challenges. This study by Bui et al.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT?
Many people in NLP seem to think that you need to work with the latest and trendiest technology in order to be relevant, both in research and in applications. At the time, the latest and trendiest NLP technology was LSTM (and variants such as biLSTM). LSTMs worked very well in lots of areas of NLP, including machine translation.
These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. str.split("|").str[0]
This post gathers ten ML and NLP research directions that I found exciting and impactful in 2019. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., 2019 ) and other variants. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al.,
In recent years, researchers have also explored using GCNs for natural language processing (NLP) tasks, such as text classification , sentiment analysis , and entity recognition. This article provides a brief overview of GCNs for NLP tasks and how to implement them using PyTorch and Comet.
Are you curious about the groundbreaking advancements in Natural Language Processing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. Ever wondered how machines can understand and generate human-like text?
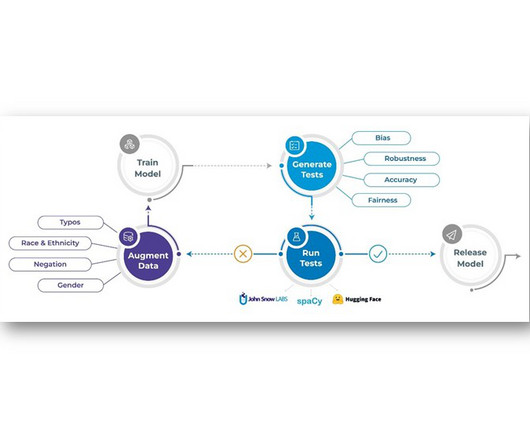
The underlying principles behind the NLP Test library: Enabling data scientists to deliver reliable, safe and effective language models. However, today there is a gap between these principles and current state-of-the-art NLP models. These findings suggest that the current NLP systems are unreliable and flawed.
2021) 2021 saw many exciting advances in machine learning (ML) and natural language processing (NLP). 6] such as W2v-BERT [7] as well as more powerful multilingual models such as XLS-R [8]. If CNNs are pre-trained the same way as transformer models, they achieve competitive performance on many NLP tasks [28]. What happened?
They annotate a new test set of news data from 2020 and find that performance of certain models holds up very well and the field luckily hasn’t overfitted to the CoNLL 2003 test set. Analysis shows that the final layers of ELECTRA and BERT capture subject-verb agreement errors best. Imperial, Google Research.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Photo by Eugene Zhyvchik on Unsplash I wanted to share a short perspective of the radical evolution we have seen in NLP. I’ve been working on NLP problems since word2vec was released, and it has been remarkable to see how quickly the models, problems, and applications have evolved. GPT-2 released with 1.5 GPT-2 released with 1.5
But if you’re working on the same sort of Natural Language Processing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them? However, LLMs are not a direct solution to most of the NLP use-cases companies have been working on. That’s definitely new.
We’ve used the DistilBertTokenizer , which inherits from the BERT WordPiece tokenization scheme. 2020 (AAAI2020) perform Truecasing as an auxiliary task supporting the main NER one. Training Data : We trained this neural network on a total of 3.7 billion words). Susanto et al., This accounts for mixed-case words. Mayhew et al.,
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. At the same time, a wave of NLP startups has started to put this technology to practical use. Data is based on: ml_nlp_paper_data by Marek Rei.
The last 12 years though, is where some of the big magic has happened in NLP. Word vectorization is an NLP methodology used to map words or phrases from a vocabulary to a corresponding vector of real numbers used to find word predictions and word similarities or semantics. BERT was designed to understand the meanings of sentences.
Jan 15: The year started out with us as guests on the NLP Highlights podcast , hosted by Matt Gardner and Waleed Ammar of Allen AI. In the interview, Matt and Ines talked about Prodigy , where training corpora come from and the challenges of annotating data for an NLP system – with some ideas about how to make it easier. ?
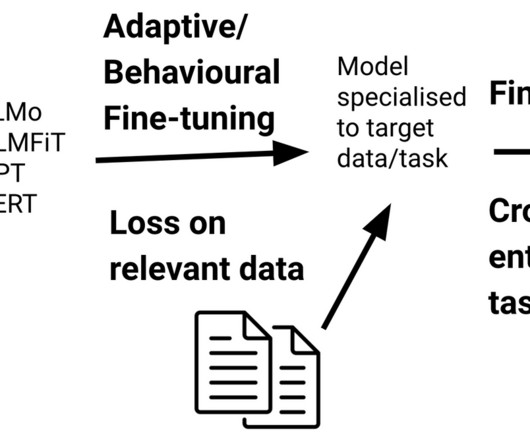
2020 ), they are still poorly equipped to deal with data that is substantially different from the one they have been pre-trained on. 2020) show that adapting to data of the target domain and target task are complementary. 2020) proposed language-adaptive fine-tuning to adapt a model to new languages. 2020 ; Phang et al.,
Reading Comprehension assumes a gold paragraph is provided Standard approaches for reading comprehension build on pre-trained models such as BERT. Using BERT for reading comprehension involves fine-tuning it to predict a) whether a question is answerable and b) whether each token is the start and end of an answer span.
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many natural language processing (NLP) tasks. They are now the foundation of today’s NLP systems. LinkBERT improves previous BERT models on many applications.
It’s much easier to configure and train your pipeline, and there are lots of new and improved integrations with the rest of the NLP ecosystem. And since modern NLP workflows often consist of multiple steps, there’s a new workflow system to help you keep your work organized. See NLP-progress for more results. Flair 2 89.7
That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for natural language processing, a report on AI said at the end of that year. Google released BERT as open-source software , spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs.
Transformer models have become the de-facto status quo in Natural Language Processing (NLP). Vision Transformer (ViT) in Image Recognition While the Transformer architecture has become the highest standard for tasks involving Natural Language Processing (NLP) , its use cases relating to Computer Vision (CV) remain only a few.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. Next, OpenAI released GPT-3 in June of 2020.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. Next, OpenAI released GPT-3 in June of 2020.
The authors described how to improve language understanding performances in NLP by using GPT. Their applications include various Natural Language Processing ( NLP ) tasks, including question answering, text summarization, sentiment analysis , etc. GPT-2 is not just a language model like BERT, it can also generate text.
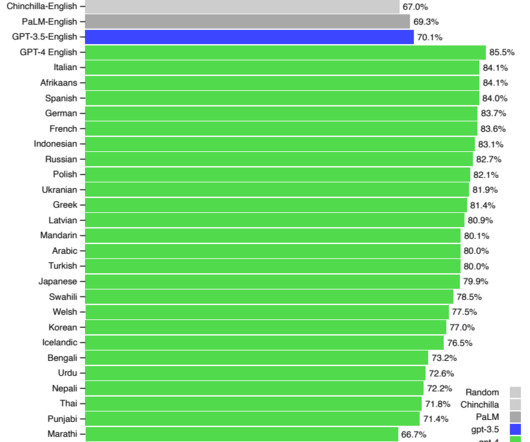
Language Disparity in Natural Language Processing This digital divide in natural language processing (NLP) is an active area of research. 2 ] Multilingual models perform worse on several NLP tasks on low resource languages than on high resource languages such as English.[ Are All Languages Created Equal in Multilingual BERT?
This long-overdue blog post is based on the Commonsense Tutorial taught by Maarten Sap, Antoine Bosselut, Yejin Choi, Dan Roth, and myself at ACL 2020. In NLP, dialogue systems generate highly generic responses such as “I don’t know” even for simple questions. In the last 3 years, language models have been ubiquitous in NLP.
Despite 80% of surveyed businesses wanting to use chatbots in 2020 , how many do you think will implement them well? On principle, all chatbots work by utilising some form of natural language processing (NLP). It also topped the Intent Recognition Leaderboard , with an accuracy result of 0.9889. But what does it all mean?
This post was first published in NLP News. EMNLP 2023 , one of the biggest NLP conferences takes place this week from Dec 6–10 in Singapore. Similar to earlier years where BERT was ubiquitous, instruction-tuned language models (LMs) and large language models (LLMs) are used in almost every paper.
It’s crazy how the AI and NLP landscape has evolved over the last five years. 5 years ago, around the time I finished my PhD, if you wanted to work on cutting-edge natural language processing (NLP), your choice was relatively limited. It is written from my perspective as a Europe-based researcher focused on NLP.
Fast-forward a couple of decades: I was (and still am) working at Lexalytics, a text-analytics company that has a comprehensive NLP stack developed over many years. The base model of BERT [ 103 ] had 12 (!) As with ULMFiT and ELMo, these contextual word vectors could be incorporated into any NLP application.
self-supervised or cheaply supervised learning) has been the backbone of the many recent successes of foundation models 3 in NLP 4 5 6 7 8 9 and vision 10 11 12. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. RoBERTa: A Robustly Optimized BERT Pretraining Approach. Toutanova, K. Goyal, N.,
billion in 2020 to an expected $152.61 Applications include NLP, speech recognition, and forecasting. Natural Language Processing (NLP) RNNs excel in NLP tasks due to their ability to process text sequences. In parallel, transformers have emerged as a dominant architecture in many NLP tasks.
Conversational AI & Graphs Let’s have a short break from hardcore ML algorithms and talk about NLP applications a bit. The authors also outline that brute-force BERT decoding without semantic parsing works much worse, so use language models wisely ? And works in different domains, i.e., from CV to NLP and Reinforcement Learning.
For machine learning researchers there are many reasons why this is more than a philosophical question: Natural Language Processing (NLP) is an area containing some of the most important machine learning applications, like translation and text summarisation. The topic is in red. The agents won this one!
In our review of 2019 we talked a lot about reinforcement learning and Generative Adversarial Networks (GANs), in 2020 we focused on Natural Language Processing (NLP) and algorithmic bias, in 202 1 Transformers stole the spotlight. Just wait until you hear what happened in 2022. What happened?
The paper states*: ‘Gender biases present in train data are known to bleed into natural language processing (NLP) systems, resulting in dissemination and potential amplification of those biases. For this approach, the authors made use of a lattice rescoring method from an earlier 2020 work.
This disruptive tendency manifests every few months and shows no sign of slowing down, with the recent releases of Llama 2 [25] and Mistral [26] (the great hopes of open source NLP [27, 28]) and two proprietary game-changers seemingly just around the corner: Gemini [29] and GPT-5 [30]. Garrido-Merchán E.C., Hertzmann A., Kishore V.,
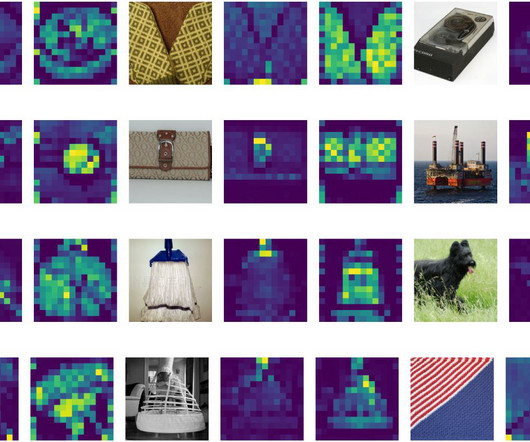
Multiple methods exist for assigning importance scores to the inputs of an NLP model. Previous work has examined neuron firings inside deep neural networks in both the NLP and computer vision domains. A breakdown of this architecture is provided here. Figure: Input saliency map attributing a model's prediction to input pixels.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content