This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recurrent NeuralNetworks (RNNs) became the cornerstone for these applications due to their ability to handle sequential data by maintaining a form of memory. Functionality : Each encoder layer has self-attention mechanisms and feed-forward neuralnetworks. However, RNNs were not without limitations.
Summary: Recurrent NeuralNetworks (RNNs) are specialised neuralnetworks designed for processing sequential data by maintaining memory of previous inputs. Introduction Neuralnetworks have revolutionised data processing by mimicking the human brain’s ability to recognise patterns.
Each stage leverages a deep neuralnetwork that operates as a sequence labeling problem but at different granularities: the first network operates at the token level and the second at the character level. We’ve used the DistilBertTokenizer , which inherits from the BERT WordPiece tokenization scheme.
Over the years, we evolved that to solving NLP use cases by adopting NeuralNetwork-based algorithms loosely based on the structure and function of a human brain. The birth of Neuralnetworks was initiated with an approach akin to structuring solving problems with algorithms modeled after the human brain.
2020 ), Turing-NLG , BST ( Roller et al., 2020 ), and GPT-3 ( Brown et al., 2020 ; Fan et al., 2020 ), quantization ( Fan et al., 2020 ), and compression ( Xu et al., 2020 ; Fan et al., 2020 ), quantization ( Fan et al., 2020 ), and compression ( Xu et al., 2020 ) and Big Bird ( Zaheer et al.,
M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. For this demonstration, we use a public Amazon product dataset called Amazon Product Dataset 2020 from a kaggle competition. str.replace(' ', '_') data['main_category'] = data['category'].str.split("|").str[0]
They said transformer models , large language models (LLMs), vision language models (VLMs) and other neuralnetworks still being built are part of an important new category they dubbed foundation models. Earlier neuralnetworks were narrowly tuned for specific tasks.
At their core, LLMs are built upon deep neuralnetworks, enabling them to process vast amounts of text and learn complex patterns. In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna.
BioBERT and similar BERT-based NER models are trained and fine-tuned using a biomedical corpus (or dataset) such as NCBI Disease, BC5CDR, or Species-800. Data formats for inputting data into NER models typically include Pandas DataFrame or text files in CoNLL format (ie. a text file with one word per line).
Model architectures that qualify as “supervised learning”—from traditional regression models to random forests to most neuralnetworks—require labeled data for training. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., A whole range of BERT variants have been applied to multimodal settings, mostly involving images and videos together with text (for an example see the figure below). 3) The Neural Tangent Kernel What happened?
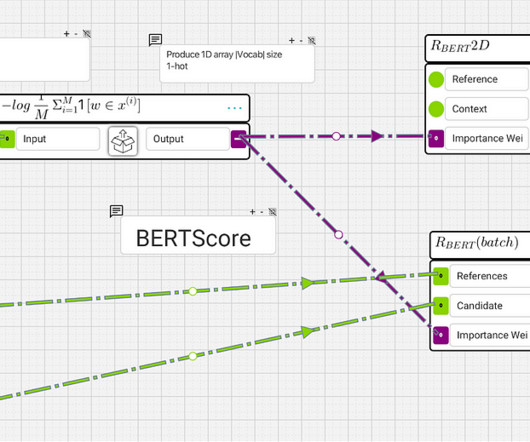
The main idea of BERTScore is to use a language model that is good at understanding text, like BERT, and use it to evaluate the similarity between two sentences, a Y in your test set and a Y’ representing the model-generated text. I use a BERT WordPiece tokenizer to generate IDs for each token of each sentence, generating a [40, 30523] array.
The 1970s introduced bell bottoms, case grammars, semantic networks, and conceptual dependency theory. In the 90’s we got grunge, statistical models, recurrent neuralnetworks and long short-term memory models (LSTM). It uses a neuralnetwork to learn the vector representations of words from a large corpus of text.
This book effectively killed off interest in neuralnetworks at that time, and Rosenblatt, who died shortly thereafter in a boating accident, was unable to defend his ideas. (I Around this time a new graduate student, Geoffrey Hinton, decided that he would study the now discredited field of neuralnetworks.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
Photo by GuerrillaBuzz on Unsplash Graph Convolutional Networks (GCNs) are a type of neuralnetwork that operates on graphs, which are mathematical structures consisting of nodes and edges. GCNs have been successfully applied to many domains, including computer vision and social network analysis. Richong, Z.,
GPT models are based on transformer-based deep learning neuralnetwork architecture. In July 2020, they introduced the GPT-3 model as the most advanced language model with 175 billion parameters. GPT-2 is not just a language model like BERT, it can also generate text. without supervised pre-training. billion parameters.
Vision Transformer (ViT) have recently emerged as a competitive alternative to Convolutional NeuralNetworks (CNNs) that are currently state-of-the-art in different image recognition computer vision tasks. No 2018 Oct BERT Pre-trained transformer models started dominating the NLP field.
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many natural language processing (NLP) tasks. To achieve this, we first chunk each document into segments of roughly 256 tokens, which is half of the maximum BERT LM input length.
Despite 80% of surveyed businesses wanting to use chatbots in 2020 , how many do you think will implement them well? The solution is based on a Transformer-type neuralnetwork, used in the BERT model as well, that has recently triumphed in the field of machine learning and natural language understanding.
In our review of 2019 we talked a lot about reinforcement learning and Generative Adversarial Networks (GANs), in 2020 we focused on Natural Language Processing (NLP) and algorithmic bias, in 202 1 Transformers stole the spotlight. Just wait until you hear what happened in 2022. Who should I follow? What happened?
6] such as W2v-BERT [7] as well as more powerful multilingual models such as XLS-R [8]. For each input chunk, nearest neighbor chunks are retrieved using approximate nearest neighbor search based on BERT embedding similarity. Advances in Neural Information Processing Systems, 2020. What happened? wav2vec 2.0:
This long-overdue blog post is based on the Commonsense Tutorial taught by Maarten Sap, Antoine Bosselut, Yejin Choi, Dan Roth, and myself at ACL 2020. With that said, the path to machine commonsense is unlikely to be brute force training larger neuralnetworks with deeper layers. Using the AllenNLP demo. Is it still useful?
Source: Chami et al Chami et al present Hyperbolic Graph Convolutional NeuralNetworks (HGCN) and Liu et al propose Hyperbolic Graph NeuralNetworks (HGNN). The authors also outline that brute-force BERT decoding without semantic parsing works much worse, so use language models wisely ? Thank you for reading!
In contrast to classification, a supervised learning paradigm, generation is most often done in an unsupervised manner: for example an autoencoder , in the form of a neuralnetwork, can capture the statistical properties of a dataset. Notice the plural: GANs are not one but two neuralnetworks that are playing a game.
They annotate a new test set of news data from 2020 and find that performance of certain models holds up very well and the field luckily hasn’t overfitted to the CoNLL 2003 test set. Analysis shows that the final layers of ELECTRA and BERT capture subject-verb agreement errors best. Imperial, Google Research.
Major milestones in the last few years comprised BERT (Google, 2018), GPT-3 (OpenAI, 2020), Dall-E (OpenAI, 2021), Stable Diffusion (Stability AI, LMU Munich, 2022), ChatGPT (OpenAI, 2022). Complex ML problems can only be solved in neuralnetworks with many layers. Deep learning neuralnetwork.
In this example figure, features are extracted from raw historical data, which are then are fed into a neuralnetwork (NN). In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN. PBAs, such as GPUs, can be used for both these steps.
Neuron Activations The Feed Forward NeuralNetwork (FFNN) sublayer is one of the two major components inside a transformer block (in addition to self-attention). Previous work has examined neuron firings inside deep neuralnetworks in both the NLP and computer vision domains.
The Technologies Behind Generative Models Generative models owe their existence to deep neuralnetworks, sophisticated structures designed to mimic the human brain's functionality. By capturing and processing multifaceted variations in data, these networks serve as the backbone of numerous generative models.
It all started in 2012 with AlexNet, a deep learning model that showed the true potential of neuralnetworks. The momentum continued in 2017 with the introduction of transformer models like BERT and GPT, which revolutionized natural language processing. This was a game-changer.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content