This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NaturalLanguageProcessing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. BERT T5 (Text-to-Text Transfer Transformer) : Introduced by Google in 2020 , T5 reframes all NLP tasks as a text-to-text problem, using a unified text-based format.
In 2018 when BERT was introduced by Google, I cannot emphasize how much it changed the game within the NLP community. This ability to understand long-range dependencies helps transformers better understand the context of words and achieve superior performance in naturallanguageprocessing tasks. GPT-2 released with 1.5
Once a set of word vectors has been learned, they can be used in various naturallanguageprocessing (NLP) tasks such as text classification, language translation, and question answering. This allows BERT to learn a deeper sense of the context in which words appear.
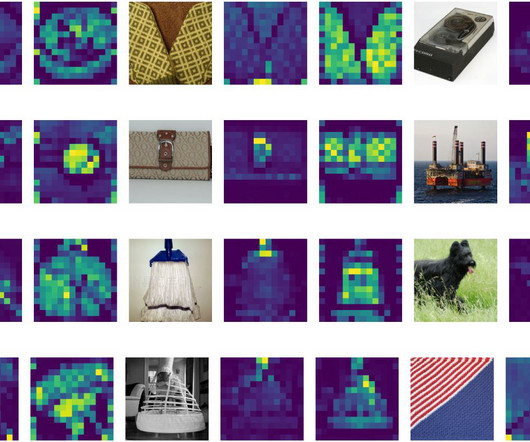
This long-overdue blog post is based on the Commonsense Tutorial taught by Maarten Sap, Antoine Bosselut, Yejin Choi, Dan Roth, and myself at ACL 2020. Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right). Using the AllenNLP demo. Is it still useful?
” BERT/BART/etc can be used in data-to-text, but may not be best approach Around 2020 LSTMs got replaced by fine-tuned transformer language models such as BERT and BART. seemed to think that ACL was about neural language models, not about naturallanguageprocessing in the wider sense.
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards naturallanguageprocessing (NLP). 2020 saw the development of ever larger language and dialogue models such as Meena ( Adiwardana et al.,
These embeddings are useful for various naturallanguageprocessing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. str.split("|").str[0]
NaturalLanguageProcessing Getting desirable data out of published reports and clinical trials and into systematic literature reviews (SLRs) — a process known as data extraction — is just one of a series of incredibly time-consuming, repetitive, and potentially error-prone steps involved in creating SLRs and meta-analyses.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
Are you curious about the groundbreaking advancements in NaturalLanguageProcessing (NLP)? Prepare to be amazed as we delve into the world of Large Language Models (LLMs) – the driving force behind NLP’s remarkable progress. and GPT-4, marked a significant advancement in the field of large language models.
Photo by Kunal Shinde on Unsplash NATURALLANGUAGEPROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.09.20 Language diversity Estimate the language diversity of the sample of languages you are studying (Ponti et al., Research Work on methods that address the challenges of low-resource languages.
This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
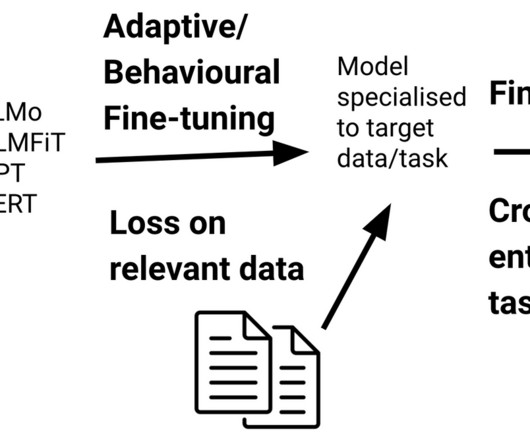
Fine-tuning a pre-trained language model (LM) has become the de facto standard for doing transfer learning in naturallanguageprocessing. 2018 ) while pre-trained language models are favoured over models trained on translation ( McCann et al., 2018 ), naturallanguage inference ( Conneau et al.,
Models that allow interaction via naturallanguage have become ubiquitious. Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. The development cycle of a language model.
Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., A whole range of BERT variants have been applied to multimodal settings, mostly involving images and videos together with text (for an example see the figure below). 2019 ; Tran, 2020 ), which can be seen below. 2019 ; Wu et al.,
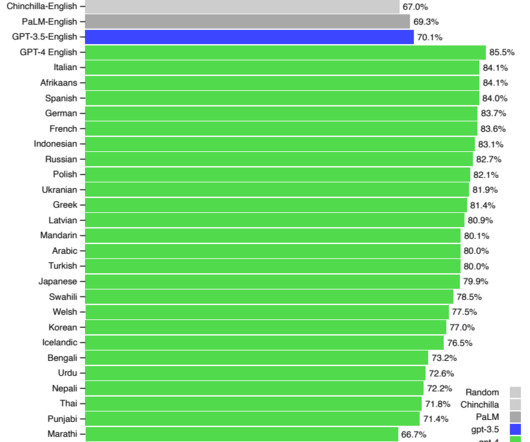
Language Disparity in NaturalLanguageProcessing This digital divide in naturallanguageprocessing (NLP) is an active area of research. 2 ] Multilingual models perform worse on several NLP tasks on low resource languages than on high resource languages such as English.[
That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for naturallanguageprocessing, a report on AI said at the end of that year. In 2020, researchers at OpenAI announced another landmark transformer, GPT-3.
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many naturallanguageprocessing (NLP) tasks. To achieve this, we first chunk each document into segments of roughly 256 tokens, which is half of the maximum BERT LM input length.
Reading Comprehension assumes a gold paragraph is provided Standard approaches for reading comprehension build on pre-trained models such as BERT. Using BERT for reading comprehension involves fine-tuning it to predict a) whether a question is answerable and b) whether each token is the start and end of an answer span.
In recent years, researchers have also explored using GCNs for naturallanguageprocessing (NLP) tasks, such as text classification , sentiment analysis , and entity recognition. Once the GCN is trained, it is easier to process new graphs and make predictions about them. Richong, Z., Yongyi, M., & Xudong L.
Transformer models have become the de-facto status quo in NaturalLanguageProcessing (NLP). For example, the popular ChatGPT AI chatbot is a transformer-based language model. They are based on the transformer architecture, which was originally proposed for naturallanguageprocessing (NLP) in 2017.
Despite 80% of surveyed businesses wanting to use chatbots in 2020 , how many do you think will implement them well? On principle, all chatbots work by utilising some form of naturallanguageprocessing (NLP). That in itself is a vast field requiring expertise and cooperation between computer science and linguistics.
A brief history of large language models Large language models grew out of research and experiments with neural networks to allow computers to processnaturallanguage. In the 2010s, this research intersected with the then-bustling field of neural networks, setting the ground for the first large language model.
A brief history of large language models Large language models grew out of research and experiments with neural networks to allow computers to processnaturallanguage. In the 2010s, this research intersected with the then-bustling field of neural networks, setting the ground for the first large language model.
This is the sort of representation that is useful for naturallanguageprocessing. ELMo would also be the first of the Muppet-themed language models that would come to include ERNIE [ 120 ], Grover [ 121 ]….and The base model of BERT [ 103 ] had 12 (!) layers of bidirectional Transformers.
The update fixed outstanding bugs on the tracker, gave the docs a huge makeover, improved both speed and accuracy, made installation significantly easier and faster, and added some exciting new features, like ULMFit/BERT/ELMo-style language model pretraining. Dec 9: Ines’ key thoughts on trends in AI from 2019 and looking into 2020.
2021) 2021 saw many exciting advances in machine learning (ML) and naturallanguageprocessing (NLP). 6] such as W2v-BERT [7] as well as more powerful multilingual models such as XLS-R [8]. We have also seen new ways to integrate retrieval into pre-trained language models [94] [95]. What happened?
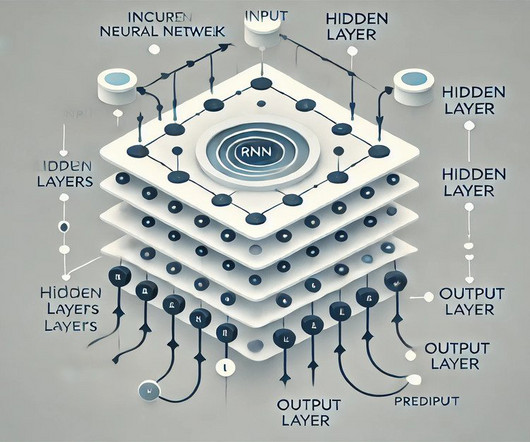
Summary: Recurrent Neural Networks (RNNs) are specialised neural networks designed for processing sequential data by maintaining memory of previous inputs. They excel in naturallanguageprocessing, speech recognition, and time series forecasting applications. billion in 2020 to an expected $152.61
Their applications include various NaturalLanguageProcessing ( NLP ) tasks, including question answering, text summarization, sentiment analysis , etc. Previous ChatGPT models The GPT-1 version was introduced in June 2018 as a method for language understanding by using generative pre-training.
A lot of people are building truly new things with Large Language Models (LLMs), like wild interactive fiction experiences that weren’t possible before. But if you’re working on the same sort of NaturalLanguageProcessing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them?
For machine learning researchers there are many reasons why this is more than a philosophical question: NaturalLanguageProcessing (NLP) is an area containing some of the most important machine learning applications, like translation and text summarisation. The topic is in red. The agents won this one!
In our review of 2019 we talked a lot about reinforcement learning and Generative Adversarial Networks (GANs), in 2020 we focused on NaturalLanguageProcessing (NLP) and algorithmic bias, in 202 1 Transformers stole the spotlight. The debate was on again: maybe language generation is really just a prediction task?
5 years ago, around the time I finished my PhD, if you wanted to work on cutting-edge naturallanguageprocessing (NLP), your choice was relatively limited. It’s crazy how the AI and NLP landscape has evolved over the last five years. Recently, I decided to go on the job market again, which has become much more diverse.
I have written short summaries of 68 different research papers published in the areas of Machine Learning and NaturalLanguageProcessing. They annotate a new test set of news data from 2020 and find that performance of certain models holds up very well and the field luckily hasn’t overfitted to the CoNLL 2003 test set.
The paper states*: ‘Gender biases present in train data are known to bleed into naturallanguageprocessing (NLP) systems, resulting in dissemination and potential amplification of those biases. For this approach, the authors made use of a lattice rescoring method from an earlier 2020 work.
Within NaturalLanguageProcessing (NLP), ‘pseudo-evaluation’ approaches that we call ‘Superficial Utility Comparison Kriterion’ ( SUCK ) methods, like BLEU [32], METEOR [33], ROUGE [34], or BLEURT [35], attempt to salvage the situation. 2023 [link] [link] [link] BERTScore: Evaluating text generation with BERT , Zhang T.,
The recent history of PBAs begins in 1999, when NVIDIA released its first product expressly marketed as a GPU, designed to accelerate computer graphics and image processing. In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN.
These advanced AI deep learning models have seamlessly integrated into various applications, from Google's search engine enhancements with BERT to GitHub’s Copilot, which harnesses the capability of Large Language Models (LLMs) to convert simple code snippets into fully functional source codes.
The momentum continued in 2017 with the introduction of transformer models like BERT and GPT, which revolutionized naturallanguageprocessing. By 2020, OpenAI's GPT-3 set new standards for AI capabilities, highlighting the high costs of training such large models.
4] In the open-source camp, initial attempts at solving the Text2SQL puzzle were focussed on auto-encoding models such as BERT, which excel at NLU tasks.[5, Content Enhanced BERT-based Text-to-SQL Generation [8] Torsten Scholak et al. Speak to your Parser: Interactive Text-to-SQL with NaturalLanguage Feedback [16] Janna Lipenkova.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content