This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By pre-training on a large corpus of text with a masked language model and next-sentence prediction, BERT captures rich bidirectional contexts and has achieved state-of-the-art results on a wide array of NLP tasks. GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.
This synthetic data was then used to train a BERT-based model called GatorTron-S. The GatorTronGPT effort is the latest result of an ambitious collaboration announced in 2020, when the University of Florida and NVIDIA unveiled plans to erect the world’s fastest AI supercomputer in academia.
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
2020 ), Turing-NLG , BST ( Roller et al., 2020 ), and GPT-3 ( Brown et al., 2020 ; Fan et al., 2020 ), quantization ( Fan et al., 2020 ), and compression ( Xu et al., 2020 ; Fan et al., 2020 ), quantization ( Fan et al., 2020 ), and compression ( Xu et al., 2020 ) and Big Bird ( Zaheer et al.,
M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. For this demonstration, we use a public Amazon product dataset called Amazon Product Dataset 2020 from a kaggle competition. str.replace(' ', '_') data['main_category'] = data['category'].str.split("|").str[0]
” BERT/BART/etc can be used in data-to-text, but may not be best approach Around 2020 LSTMs got replaced by fine-tuned transformer language models such as BERT and BART. This is a much better way to build data-to-text and other NLG systems, and I know of several production-quality NLG systems built using BART (etc).
In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna. BERT excels in understanding context and generating contextually relevant representations for a given text.
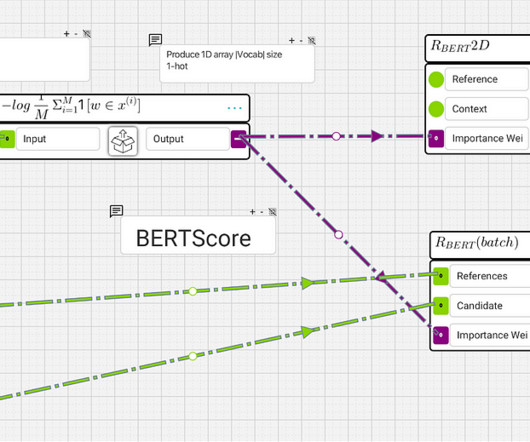
The main idea of BERTScore is to use a language model that is good at understanding text, like BERT, and use it to evaluate the similarity between two sentences, a Y in your test set and a Y’ representing the model-generated text. I use a BERT WordPiece tokenizer to generate IDs for each token of each sentence, generating a [40, 30523] array.
The burden from growing event volumes is reflected in budgets that are expected to grow from an estimated USD 4 billion in 2017 to over 6 billion by 2020. Regardless of volumes, companies must report these events rapidly to regulators and act quickly on safety signals.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Popular Examples include the Bidirectional Encoder Representations from Transformers (BERT) model and the Generative Pre-trained Transformer 3 (GPT-3) model. 2017) “ BERT: Pre-training of deep bidirectional transformers for language understanding ” by Devlin et al. 2020) “GPT-4 Technical report ” by Open AI.
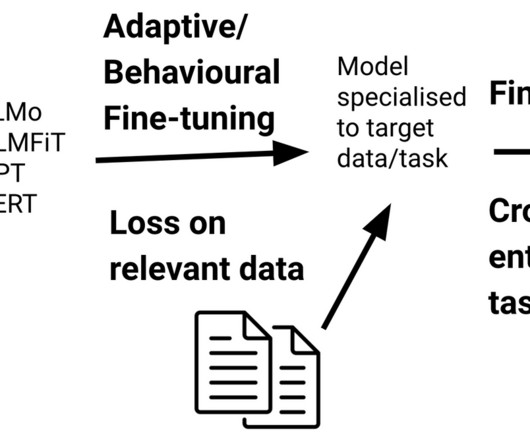
2020 ), they are still poorly equipped to deal with data that is substantially different from the one they have been pre-trained on. 2020) show that adapting to data of the target domain and target task are complementary. 2020) proposed language-adaptive fine-tuning to adapt a model to new languages. 2020 ; Phang et al.,
Consider which are specific to the language you are studying and which might be more general. Language diversity Estimate the language diversity of the sample of languages you are studying (Ponti et al., Research Work on methods that address the challenges of low-resource languages.
BioBERT and similar BERT-based NER models are trained and fine-tuned using a biomedical corpus (or dataset) such as NCBI Disease, BC5CDR, or Species-800. Data formats for inputting data into NER models typically include Pandas DataFrame or text files in CoNLL format (ie. a text file with one word per line).
We’ve used the DistilBertTokenizer , which inherits from the BERT WordPiece tokenization scheme. 2020 (AAAI2020) perform Truecasing as an auxiliary task supporting the main NER one. Training Data : We trained this neural network on a total of 3.7 billion words). Susanto et al., This accounts for mixed-case words. Mayhew et al.,
In 2018 when BERT was introduced by Google, I cannot emphasize how much it changed the game within the NLP community. Photo by Kapa64 on PixelBay Following BERT, several models began to appear with their roots in BERT’s fundamental architecture. In retrospect, we were slightly ahead of our time because of what came next.
Transformer models like BERT , which are pre-trained on large quantities of text, are the go-to approach these days for embedding text in a semantic space. SPECTER, released in 2020, supplies embeddings for a variety of our offerings at Semantic Scholar — user research feeds , author name disambiguation , paper clustering , and many more!
Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., A whole range of BERT variants have been applied to multimodal settings, mostly involving images and videos together with text (for an example see the figure below). 2019 ; Tran, 2020 ), which can be seen below. 2019 ; Wu et al.,
Reading Comprehension assumes a gold paragraph is provided Standard approaches for reading comprehension build on pre-trained models such as BERT. Using BERT for reading comprehension involves fine-tuning it to predict a) whether a question is answerable and b) whether each token is the start and end of an answer span.
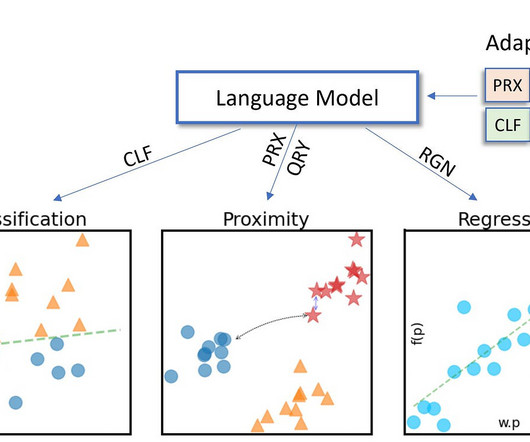
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. 2020) (Ahia et al., Models that allow interaction via natural language have become ubiquitious. The development cycle of a language model.
They published the original Transformer paper (not quite coincidentally called “Attention is All You Need”) in 2017, and released BERT , an open source implementation, in late 2018, but they never went so far as to build and release anything like OpenAI’s GPT line of services. Will History Repeat Itself?
BERTBERT uses a transformer-based architecture, which allows it to effectively handle longer input sequences and capture context from both the left and right sides of a token or word (the B in BERT stands for bi-directional). This allows BERT to learn a deeper sense of the context in which words appear.
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many natural language processing (NLP) tasks. To achieve this, we first chunk each document into segments of roughly 256 tokens, which is half of the maximum BERT LM input length.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. Next, OpenAI released GPT-3 in June of 2020.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. Next, OpenAI released GPT-3 in June of 2020.
The update fixed outstanding bugs on the tracker, gave the docs a huge makeover, improved both speed and accuracy, made installation significantly easier and faster, and added some exciting new features, like ULMFit/BERT/ELMo-style language model pretraining. Dec 9: Ines’ key thoughts on trends in AI from 2019 and looking into 2020.
That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for natural language processing, a report on AI said at the end of that year. Google released BERT as open-source software , spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs.
6] such as W2v-BERT [7] as well as more powerful multilingual models such as XLS-R [8]. For each input chunk, nearest neighbor chunks are retrieved using approximate nearest neighbor search based on BERT embedding similarity. Advances in Neural Information Processing Systems, 2020. What happened? Why is it important?
In July 2020, they introduced the GPT-3 model as the most advanced language model with 175 billion parameters. GPT-2 is not just a language model like BERT, it can also generate text. GPT-3 GPT-3 release took place in May 2020 and beta testing began in July 2020. Today, it is the golden approach for generating text.
This long-overdue blog post is based on the Commonsense Tutorial taught by Maarten Sap, Antoine Bosselut, Yejin Choi, Dan Roth, and myself at ACL 2020. Here, BERT has seen in its training corpus enough sentences of the type "The color of something is [color]" to know to suggest different colors as substitutes for the masked word.
No 2018 Oct BERT Pre-trained transformer models started dominating the NLP field. No 2020 May DETR DETR is a simple yet effective framework for high-level vision that views object detection as a direct set prediction problem. No 2020 Jul iGPT The transformer model, originally developed for NLP, can also be used for image pre-training.
References Paperwithcode | Graph Convolutional Network Kai, S., Richong, Z., Yongyi, M., & Xudong L. Aspect-Level Sentiment Analysis Via Convolution over Dependency Tree Lu, Z., & Nie, JY.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. RoBERTa: A Robustly Optimized BERT Pretraining Approach. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. . ↩ Devlin, J., Toutanova, K. arXiv preprint arXiv:1810.04805. ↩ Liu, Y., Goyal, N., Stoyanov, V.
In their experiments, OpenAI prompted GPT3 with 32 examples of each task, and found that they were able to achieve similar accuracy to the BERT baselines. OpenAI evaluated GPT-3’s in-context learning capabilities against supervised learning in a variety of configurations (Brown et al., The results in Section 3.7,
The base model of BERT [ 103 ] had 12 (!) If you gave BERT a chunk of input text, it produced word vectors that encoded each word’s context, so that now it was finally possible to disambiguate “bank” (the financial institution) from “bank” (the edge of a river). BERT is just too good not to use. Howard and S.
According to [ Ribeiro 2020 ], the sentiment analysis services of the top three cloud providers fail 9-16% of the time when replacing neutral words, and 7-20% of the time when changing neutral named entities. However, today there is a gap between these principles and current state-of-the-art NLP models.
Despite 80% of surveyed businesses wanting to use chatbots in 2020 , how many do you think will implement them well? The solution is based on a Transformer-type neural network, used in the BERT model as well, that has recently triumphed in the field of machine learning and natural language understanding.
Are All Languages Created Equal in Multilingual BERT? Advances in neural information processing systems 33 (2020): 1877–1901. In Findings of the Association for Computational Linguistics: ACL 2022 , pages 2340–2354, Dublin, Ireland. Association for Computational Linguistics. Shijie Wu and Mark Dredze. Brown, Tom, et al.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this.
First, “Selection via Proxy,” which appeared in ICLR 2020. And please see our work, our paper “Selection via Proxy” from ICLR 2020 for more details on core-set selection, as well as all of the other datasets and methods that we tried there. I was super fortunate to work with amazing researchers from Stanford on this.
Hwang et a l present SQLova, a semantic parsing model that uses BERT to encode questions and table headers, and attention-based decoder that produces SQL constructs (for instance, SELECTs, WHERE clauses, aggregation functions, etc) that are later ranked and evaluated. Thank you for reading!
Language is an abundant resource: petabytes of human-produced data on the internet have been put to use to train huge language models such as GPT-3 and Google BERT. Techniques developed in NLP, such as the Transformer architecture, are useful in very diverse fields such as computer vision and reinforcement learning. The topic is in red.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content