This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
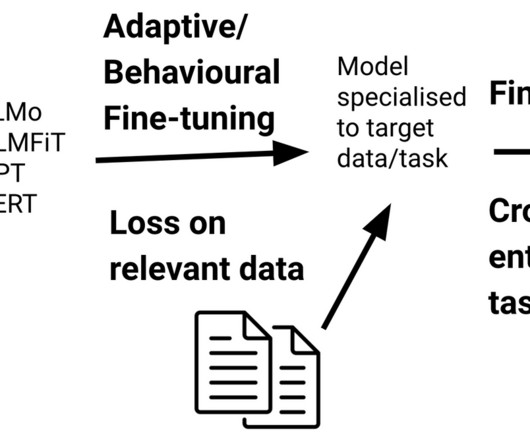
Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT.
The post 7 Amazing NLP Hack Sessions to Watch out for at DataHack Summit 2019 appeared first on Analytics Vidhya. Picture a world where: Machines are able to have human-level conversations with us Computers understand the context of the conversation without having to be.
Much before generative AI came into existence, Moveworks began its tryst with it, starting with Google’s language model BERT in 2019, in an attempt to make conversational AI better.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
This post gathers ten ML and NLP research directions that I found exciting and impactful in 2019. Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., 2019 ) and other variants. 2019 ), MoCo ( He et al., 2019 ), MoCo ( He et al., 2019 ) and domains ( Desai et al.,
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
In this article, we will talk about another and one of the most impactful works published by Google, BERT (Bi-directional Encoder Representation from Transformers) BERT undoubtedly brought some major improvements in the NLP domain. Then, Finally, we come to BERT.
As 2019 draws to a close and we step into the 2020s, we thought we’d take a look back at the year and all we’ve accomplished. was released – our first major upgrade to Prodigy for 2019. Sep 15: Adriane Boyd makes up the second spaCy developer team hire in 2019. Got a question? ✨ Feb 18: Finally in February, Prodigy v1.7.0
So, what’s new in the world of machine translation and what can we expect in 2019? 6-Deep Words Representation Not linked to any particular paper disclosed at the conference, but the BERT configuration was widely discussed and often mentioned during presentations and coffee breaks. BERT is a new milestone in NLP.
The BERT (Bidirectional Encoder Representation from Transformers) model was proposed in the paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin, et al, 2019). The BERT model is pre-trained on two tasks
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. In a recent talk at Google Berlin, Jacob Devlin described how Google are using his BERT architectures internally. In this post we introduce our new wrapping library, spacy-transformers.
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. 2019 ) of recent years. A taxonomy that highlights the variations can be seen below: A taxonomy for transfer learning in NLP ( Ruder, 2019 ). Update 16.10.2020: Added Chinese and Spanish translations. 2017 ) and pretrained language models ( Peters et al.,
Let’s check out the goodies brought by NeurIPS 2019 and co-located events! Balažević et al (creators of TuckER model from EMNLP 2019 ) apply hyperbolic geometry to knowledge graph embeddings in their Multi-Relational Poincaré model ( MuRP ). Graphs were well represented at the conference. Thank you for reading!
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages. Fine-tuning multilingual BERT models with AWS Batch GPU jobs We sought a solution to support multiple languages for our diverse user base.
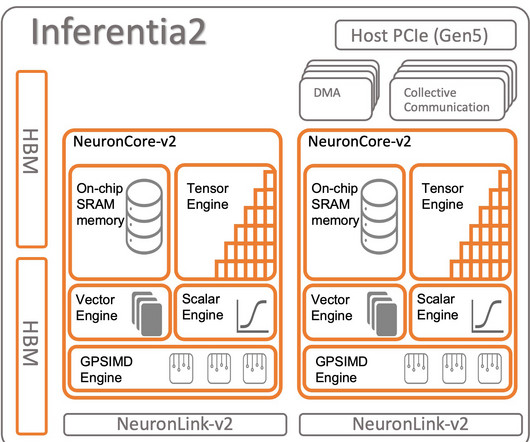
Inferentia1: The first-generation AWS Inferentia accelerator powers Amazon EC2 Inf1 instances launched in 2019. Goal In this end-to-end post, we will learn how to speed up BERT inference for text classification with Hugging Face Transformers, Amazon SageMaker, and AWS Inferentia2. Inf1 accelerators can deliver up to 2.3x
BERT is still very popular over the past few years and even though the last update from Google was in late 2019 it is still widely deployed. BERT stands out thanks to its strong affinity for question-answering and context-based similarity searches, making it reliable for chatbots and other related applications.
The paper is a case study of syntax acquisition in BERT (Bidirectional Encoder Representations from Transformers). An MLM, BERT gained significant attention around 2018–2019 and is now often used as a base model fine-tuned for various tasks, such as classification.
Conclusion It is worth mentioning that MQA was proposed in 2019, and its application was not as extensive at that time. Later on, the representative model BERT, which is also based on the transformer encoder structure, […]
market were cleared between 2019 to 2022, with more than 300 apps in just four years. Foundation Model Hackathon: A 2-day hackathon to ideate and prototype innovative AI solutions for specific use case domains—leveraging standard cloud APIs or open-source foundation models (GPT, BERT and others).
This post expands on the ACL 2019 tutorial on Unsupervised Cross-lingual Representation Learning. In particular, I cover unsupervised deep multilingual models such as multilingual BERT. In particular, I cover unsupervised deep multilingual models such as multilingual BERT. The domains in this case are different languages.
Google also has open-source models like BERT, T5, ViT, and EfficientNet for easy deployment on GCP. Back in 2019, before most grasped the astounding potential of LLMs, Microsoft invested a cool $1 billion into OpenAI — the maker of GPT-3. But Google isn’t limiting Model Garden exclusively to its own AI.
Transformer models like BERT , which are pre-trained on large quantities of text, are the go-to approach these days for embedding text in a semantic space. These vectors are then used either to find similar documents or as features in a computationally cheap model. A variety of such embedding models are available for users to choose from.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
2019 ; Raffel et al., 2019) ) While pre-training is compute-intensive, fine-tuning can be done comparatively inexpensively. 2019 ; Han and Eisenstein, 2019 ; Mehri et al., 2020) fine-tune BERT for quality evaluation with a range of sentence similarity signals. 2018 ), natural language inference ( Conneau et al.,
Below you will find short summaries of a number of different research papers published in the areas of Machine Learning and Natural Language Processing in the past couple of years (2017-2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
RoBERTa RoBERTa (Robustly Optimized BERT Approach) is a natural language processing (NLP) model based on the BERT (Bidirectional Encoder Representations from Transformers) architecture. It was developed by Facebook AI Research and released in 2019. It is a state-of-the-art model for a variety of NLP tasks.
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many natural language processing (NLP) tasks. To achieve this, we first chunk each document into segments of roughly 256 tokens, which is half of the maximum BERT LM input length.
BERTBERT uses a transformer-based architecture, which allows it to effectively handle longer input sequences and capture context from both the left and right sides of a token or word (the B in BERT stands for bi-directional). This allows BERT to learn a deeper sense of the context in which words appear.
RoBERTa: A Modified BERT Model for NLP — by Khushboo Kumari An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account.
Reading Comprehension assumes a gold paragraph is provided Standard approaches for reading comprehension build on pre-trained models such as BERT. Using BERT for reading comprehension involves fine-tuning it to predict a) whether a question is answerable and b) whether each token is the start and end of an answer span.
The first generation of AWS Inferentia, a purpose-built accelerator launched in 2019, is optimized to accelerate deep learning inference. Two models were used in this process––both large language models: ELECTRA large discriminator and BERT large uncased. With AWS Inferentia1, customers saw up to 2.3x PyTorch (1.13.1)
Traditionally, language models are trained to predict the next word in a sentence (top part of Figure 2, in blue), but they can also predict hidden (masked) words in the middle of the sentence, as in Google's BERT model (top part of Figure 2, in orange). 2019) used BERT as the neural component to represent the instance (statement vector).
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. Proceedings of NAACL 2019, Tutorial Abstracts. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Kolesnikov, A.,
2019 ) and work that focuses on making them smaller has gained momentum: Recent approaches rely on pruning ( Sajjad et al., 2019 ; Sun et al., 2019 ; Pfeiffer et al., 2019 ; Bender and Koller, 2020 ), we know that current models are not close to this elusive goal. 2020 ; Fan et al., 2020a ; Sanh et al.,
The base model of BERT [ 103 ] had 12 (!) If you gave BERT a chunk of input text, it produced word vectors that encoded each word’s context, so that now it was finally possible to disambiguate “bank” (the financial institution) from “bank” (the edge of a river). BERT is just too good not to use. Howard and S.
References Paperwithcode | Graph Convolutional Network Kai, S., Richong, Z., Yongyi, M., & Xudong L. Aspect-Level Sentiment Analysis Via Convolution over Dependency Tree Lu, Z., & Nie, JY.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. RoBERTa: A Robustly Optimized BERT Pretraining Approach. RoBERTa: A Robustly Optimized BERT Pretraining Approach. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. . ↩ Devlin, J., Toutanova, K. Goyal, N.,
To demonstrate the success of this model, OpenAI refined it and released GPT-2 in February 2019. GPT-2 is not just a language model like BERT, it can also generate text. GPT-2 Model Features To improve the performance, in February 2019, OpenAI increased its GPT by 10 times. Today, it is the golden approach for generating text.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content