This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
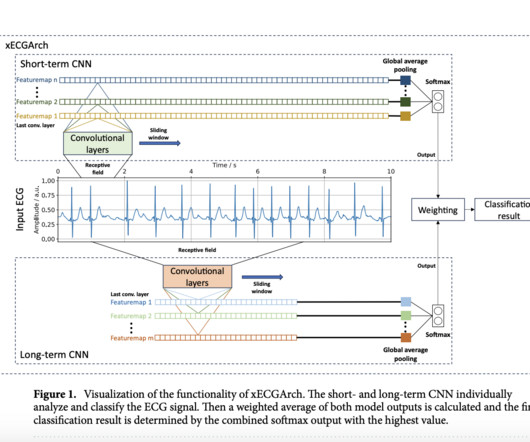
xECGArch uniquely separates short-term (morphological) and long-term (rhythmic) ECG features using two independent ConvolutionalNeuralNetworks CNNs. Researchers at the Institute of Biomedical Engineering, TU Dresden, developed a deep learning architecture, xECGArch, for interpretable ECG analysis.
Prompt 1 : “Tell me about ConvolutionalNeuralNetworks.” ” Response 1 : “ConvolutionalNeuralNetworks (CNNs) are multi-layer perceptron networks that consist of fully connected layers and pooling layers. They are commonly used in image recognition tasks. .”
Harnessing the raw power of NVIDIA GPUs and aided by a network of thousands of cameras dotting the Californian landscape, DigitalPath has refined a convolutionalneuralnetwork to spot signs of fire in real time. a short drive from the town of Paradise, where the state’s deadliest wildfire killed 85 people in 2018.
In the second step, these potential fields are classified and corrected by the neuralnetwork model. R-CNN (Regions with ConvolutionalNeuralNetworks) and similar two-stage object detection algorithms are the most widely used in this regard. YOLOv3 is a newer version of YOLO and was released in 2018.
You’ll typically find IoU and mAP used to evaluate the performance of HOG + Linear SVM detectors ( Dalal and Triggs, 2005 ), ConvolutionalNeuralNetwork methods, such as Faster R-CNN ( Girshick et al., For more information, including a worked example of how to compute mAP, please see Hui (2018). 2015 ; He et al.,
Hence, rapid development in deep convolutionalneuralnetworks (CNN) and GPU’s enhanced computing power are the main drivers behind the great advancement of computer vision based object detection. Various two-stage detectors include region convolutionalneuralnetwork (RCNN), with evolutions Faster R-CNN or Mask R-CNN.
GPT-1: The Beginning Launched in June 2018, GPT-1 marked the inception of the GPT series. This parallel processing capability allows Transformers to handle long-range dependencies more effectively than recurrent neuralnetworks (RNNs) or convolutionalneuralnetworks (CNNs).
DigitalPath, based in Chico, California, has refined a convolutionalneuralnetwork to spot wildfires. The mission is near and dear to DigitalPath employees, whose office sits not far from the town of Paradise, where California’s deadliest wildfire killed 85 people in 2018. We don’t want people to lose their lives.”
With the rise of deep learning (deep learning means multiple levels of neuralnetworks) and neuralnetworks, models such as Recurrent NeuralNetworks (RNNs) and ConvolutionalNeuralNetworks (CNNs) began to be used in NLP. 2018) “ Language models are few-shot learners ” by Brown et al.
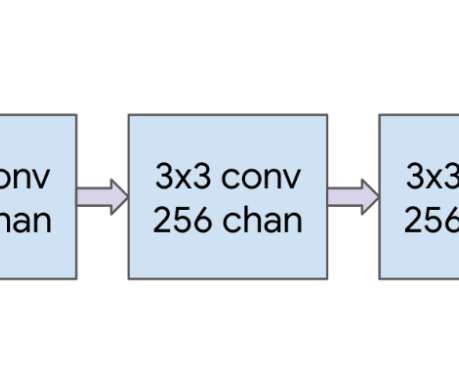
YOLOv3 Darknet53 in YOLOv3 – source YOLOv3 was released in 2018 and introduced a deeper backbone network, the Darknet-53, which had 53 convolutional layers. This deeper network helped with better feature extraction. This step outputs both global and local information from the feature maps.
is well known for his work on optical character recognition and computer vision using convolutionalneuralnetworks (CNN), and is a founding father of convolutional nets. in 1998, In general, LeNet refers to LeNet-5 and is a simple convolutionalneuralnetwork.
Some of the methods used for scene interpretation include ConvolutionalNeuralNetworks (CNNs) , a deep learning-based methodology, and more conventional computer vision-based techniques like SIFT and SURF.
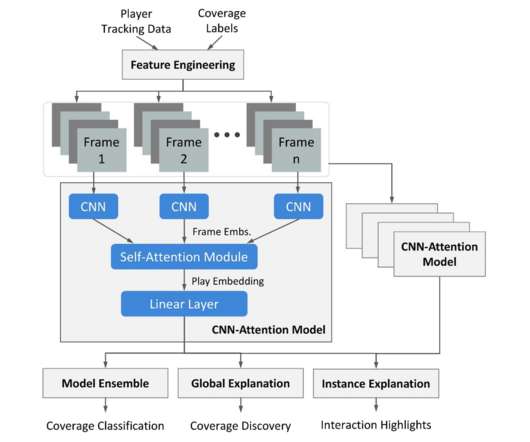
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. He received a Bachelor of Science in Physics and Astronomy with minors in Mathematics and Computer Science at University of Wisconsin – Madison in 2018. Each season consists of around 17,000 plays.
Vision Transformer (ViT) have recently emerged as a competitive alternative to ConvolutionalNeuralNetworks (CNNs) that are currently state-of-the-art in different image recognition computer vision tasks. No 2018 Oct BERT Pre-trained transformer models started dominating the NLP field.
The model comprises a convolutionalneuralnetwork (CNN) and an action space translating class labels into speed and throttle movement. The question turned out to be: How hard is it to make a track that has the same design as the official tracks, but that takes up less space than the 8m x 6m of the re:Invent 2018 track?
ArXiv 2018. The generative part is then evaluated as a language model, while the inference network is evaluated as an unsupervised unlabeled constituency parser. EMNLP 2018. NAACL 2018. NAACL 2018. At the end, I also include the summaries for my own published papers since the last iteration (papers 61-74).
2018) applied STSs to determine the optimal path the solar collector follows the Sun. Computer Vision Model for Solar Prediction The researchers based their solution on computer vision, specifically deep Convolutionalneuralnetworks (CNNs) for object localization and identification. Carballo et al.
Practitioners first trained a ConvolutionalNeuralNetwork (CNN) to perform image classification on ImageNet (i.e. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition.” November 21, 2018. pre-training). fine-tuning). October 5, 2013. link] [3] He, Kaiming, Ross Girshick, and Piotr Dollár.
An image can be represented by the relationships between the activations of features detected by a convolutionalneuralnetwork (CNN). 2018) StarGAN extends GANs to multi-domain image translation. A Gram matrix captures the style information of an image in numerical form. What is Perceptual Loss?
A paper that exemplifies the Classifier Cage Match era is LeCun et al [ 109 ], which pits support vector machines (SVMs), k-nearest neighbor (KNN) classifiers, and convolutionneuralnetworks (CNNs) against each other to recognize images from the NORB database. 90,575 trainable parameters, placing it in the small-feature regime.
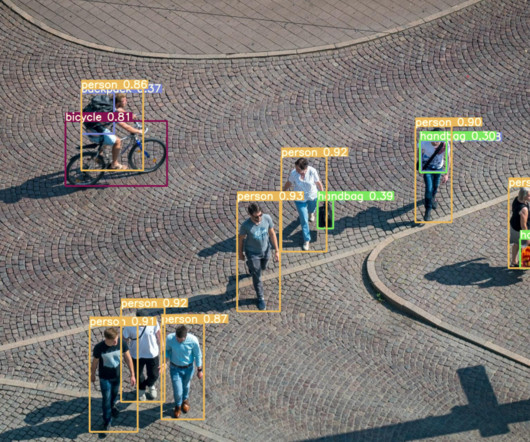
Farhadi, signifying a step forward in the real-time object detection space, outperforming its predecessor – the Region-based ConvolutionalNeuralNetwork (R-CNN). It is a single-pass algorithm having only one neuralnetwork to predict bounding boxes and class probabilities using a full image as input. Divvala, R.
These new approaches generally; Feed the image into a ConvolutionalNeuralNetwork (CNN) for encoding, and run this encoding into a decoder Recurrent NeuralNetwork (RNN) to generate an output sentence. 2018)[ 103 ] proposed a more natural method for attention, inspired by neuroscience. respectively[ 109 ].
2018 ; Howard et al., More recently, contrastive learning gained popularity in self-supervised representation learning in computer vision and speech ( van den Oord, 2018 ; Hénaff et al., 2018 ) during dataset creation to filter out examples that are predicted correctly by current models. 2018 ; Hahn et al.,
YOLO’s architecture was a significant revolution in the real-time object detection space, surpassing its predecessor – the Region-based ConvolutionalNeuralNetwork (R-CNN). The backbone is a pre-trained ConvolutionalNeuralNetwork (CNN) that extracts low, medium, and high-level feature maps from an input image.
Many of these methods utilize deep learning and ConvolutionalNeuralNetworks (CNNs) to create point cloud processing. Deep Learning Convolutional-Based Method Processing irregular, unstructured point cloud data remains a formidable challenge, despite the deep learning’s success in processing structured 2D image data.
One trend that started with our work on Vision Transformers in 2020 is to use the Transformer architecture in computer vision models rather than convolutionalneuralnetworks. They were followed in 2017 by VQ-VAE, proposed in “ Neural Discrete Representation Learning ”, a vector-quantized variational autoencoder.
In the field of real-time object identification, YOLOv11 architecture is an advancement over its predecessor, the Region-based ConvolutionalNeuralNetwork (R-CNN). Using an entire image as input, this single-pass approach with a single neuralnetwork predicts bounding boxes and class probabilities. Redmon, et al.
NVIDIA in 2018 came out with a breakthrough Model- StyleGAN, which amazed the world for its ability to generate ultra-realistic and high-quality images. StyleGAN is GAN (Generative Adversarial Network), a Deep Learning (DL) model, that has been around for some time, developed by a team of researchers including Ian Goodfellow in 2014.
Today’s boom in CV started with the implementation of deep learning models and convolutionalneuralnetworks (CNN). 2018) published their research titled MobileFaceNets. Lightweight computer vision models allow the users to deploy them on mobile and edge devices. They used less than 1 million parameters.
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks Radford et al. 2016) This paper introduced DCGANs, a type of generative model that uses convolutionalneuralnetworks to generate images with high fidelity. Attention Is All You Need Vaswani et al.
Images can be embedded using models such as convolutionalneuralnetworks (CNNs) , Examples of CNNs include VGG , and Inception. SentenceBERT: Currently, the leader among the pack, SentenceBERT was introduced in 2018 and immediately took the pole position for Sentence Embeddings. using its Spectrogram ).
This solution is based on several ConvolutionalNeuralNetworks that work in a cascade fashion to locate the face with some landmarks in an image. The first network is called a Proposal Network – it parses the image and selects several bounding boxes that surround an object of interest: a face, in our case.
spaCy’s default token-vector encoding settings are a depth 4 convolutionalneuralnetwork with width 96, and hash embeddings with 2000 rows. But on smaller datasets, it’s not uncommon to see the 50% error reduction demonstrated here. These settings result in a very small model: the trainable weights are only 3.8
Most algorithms use a convolutionalneuralnetwork (CNN) to extract features from the image to predict the probability of learned classes. in 2018 YOLOv4 model, released by Bochkovskiy et al. YOLOv7 applied for computer vision in Aviation – built on Viso Suite What is YOLO in computer vision?
is well known for his work on optical character recognition and computer vision using convolutionalneuralnetworks (CNN), and is a founding father of convolutional nets. in 1998, In general, LeNet refers to LeNet-5 and is a simple convolutionalneuralnetwork. > Finished chain. . >
Smoke plumes obscuring the 2018 Camp Fire in California. All inputs are resampled to a uniform 1 km–square grid and fed into a convolutionalneuralnetwork (CNN). Finally, we compute the relative angles of the sun and the satellites, and provide these as additional input to the model.
22] On a high level in the architecture, the frames extracted from a video sequence are processed in small sets within a ConvolutionalNeuralNetwork (CNN), [23] while an LSTM-variant runs on the CNN output sequentially to generate output characters. A Joint Many-Task Model: Growing a NeuralNetwork for Multiple NLP Tasks.
Instead of complex and sequential architectures like Recurrent NeuralNetworks (RNNs) or ConvolutionalNeuralNetworks (CNNs), the Transformer model introduced the concept of attention, which essentially meant focusing on different parts of the input text depending on the context.
From the development of sophisticated object detection algorithms to the rise of convolutionalneuralnetworks (CNNs) for image classification to innovations in facial recognition technology, applications of computer vision are transforming entire industries. Thus, positioning him as one of the top AI influencers in the world.
NeuralNetworks are the workhorse of Deep Learning (cf. ConvolutionalNeuralNetworks have seen an increase in the past years, whereas the popularity of the traditional Recurrent NeuralNetwork (RNN) is dropping. 2018) present an excellent overview of the state-of-the-art algorithms.
For instance, convolutionalneuralnetworks (CNNs) are used in tandem with transformer-based models to interpret histopathology slides alongside corresponding reports, providing a holistic view of patient data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content