

NLP Rise with Transformer Models | A Comprehensive Analysis of T5, BERT, and GPT
Unite.AI
NOVEMBER 8, 2023
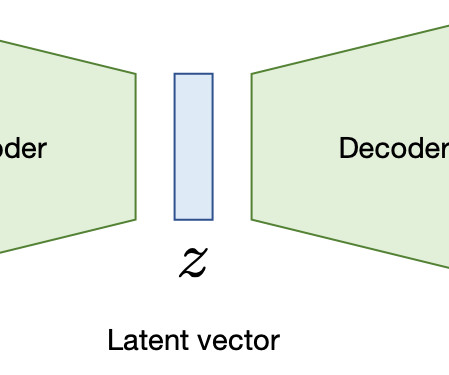
By pre-training on a large corpus of text with a masked language model and next-sentence prediction, BERT captures rich bidirectional contexts and has achieved state-of-the-art results on a wide array of NLP tasks. GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.
























Let's personalize your content