

NLP Rise with Transformer Models | A Comprehensive Analysis of T5, BERT, and GPT
Unite.AI
NOVEMBER 8, 2023
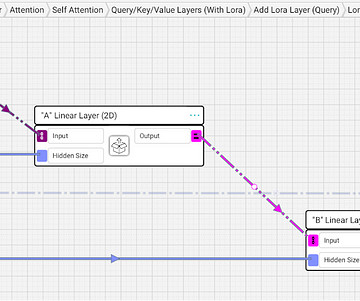
One-hot encoding is a process by which categorical variables are converted into a binary vector representation where only one bit is “hot” (set to 1) while all others are “cold” (set to 0). GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.



















Let's personalize your content