
Text Classification using BERT and TensorFlow
Analytics Vidhya
DECEMBER 30, 2021
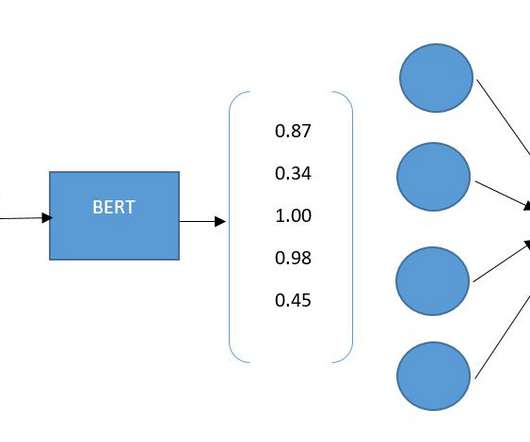
This article was published as a part of the Data Science Blogathon Introduction In 2018, a powerful Transformer-based machine learning model, namely, BERT was developed by Jacob Devlin and his colleagues from Google for NLP applications. The post Text Classification using BERT and TensorFlow appeared first on Analytics Vidhya.










































Let's personalize your content