This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon Introduction In 2018, a powerful Transformer-based machine learning model, namely, BERT was developed by Jacob Devlin and his colleagues from Google for NLP applications. The post Text Classification using BERT and TensorFlow appeared first on Analytics Vidhya.
Source: Canva|Arxiv Introduction In 2018 GoogleAI researchers developed Bidirectional Encoder Representations from Transformers (BERT) for various NLP tasks. However, one of the key limitations of this technique was the quadratic dependency, due to which the BERT-like model can handle sequences of 512 tokens […].
Source: Canva Introduction In 2018, GoogleAI researchers released the BERT model. However, the BERT model did have some drawbacks i.e. it was bulky and hence a little slow. This article was published as a part of the Data Science Blogathon. It was a fantastic work that brought a revolution in the NLP domain.
Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT.
By pre-training on a large corpus of text with a masked language model and next-sentence prediction, BERT captures rich bidirectional contexts and has achieved state-of-the-art results on a wide array of NLP tasks. GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.
Since its introduction in 2018, BERT has transformed Natural Language Processing. Using bidirectional training and transformer-based self-attention, BERT introduced a new way to understand relationships between words in text. However, despite its success, BERT has limitations.
BERT is a language model which was released by Google in 2018. However, in the past half a decade, many significant advancements have been made with other types of architectures and training configurations that have yet to be incorporated into BERT. BERT-Base reached an average GLUE score of 83.2% hours compared to 23.35
This article was published as a part of the Data Science Blogathon. Source: Canva Introduction In 2018 Google AI released a self-supervised learning model […]. The post A Gentle Introduction to RoBERTa appeared first on Analytics Vidhya.
There is very little contention that large language models have evolved very rapidly since 2018. Both BERT and GPT are based on the Transformer architecture. It all started with Word2Vec and N-Grams in 2013 as the most recent in language modelling. RNNs and LSTMs came later in 2014.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. One of the more popular and useful of the transformer architectures, Bidirectional Encoder Representations from Transformers (BERT), is a language representation model that was introduced in 2018.
In this article, we will talk about another and one of the most impactful works published by Google, BERT (Bi-directional Encoder Representation from Transformers) BERT undoubtedly brought some major improvements in the NLP domain. Deep contextualized word representations This paper was released by Allen-AI in the year 2018.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks.
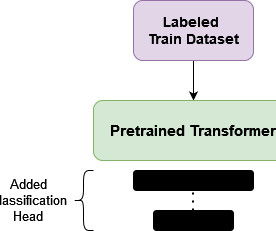
In the case of BERT (Bidirectional Encoder Representations from Transformers), learning involves predicting randomly masked words (bidirectional) and sentence-order prediction. For concreteness, we will use BERT as the base model and set the number of classification labels to 4.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
This week we are diving into some interesting discussions on transformers, BERT, and RAG, along with some interesting collaboration opportunities for building a bot, a productivity app, and more. Introduced in 2018, BERT has been a topic of interest for many, with many articles and YouTube videos attempting to break it down.
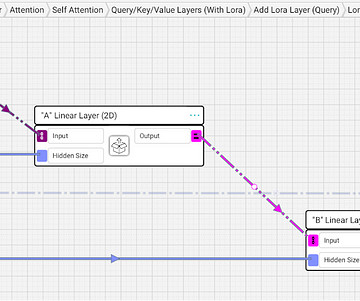
Back when BERT and GPT2 were first revolutionizing natural language processing (NLP), there was really only one playbook for fine-tuning. BERT LoRA First, I’ll show LoRA in the BERT implementation, and then I’ll do the same for GPT. You had to be very careful with fine-tuning because of catastrophic forgetting.
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. In a recent talk at Google Berlin, Jacob Devlin described how Google are using his BERT architectures internally. In this post we introduce our new wrapping library, spacy-transformers.
2018 ; Akbik et al., 2018 ; Baevski et al., In contrast, current models like BERT-Large and GPT-2 consist of 24 Transformer blocks and recent models are even deeper. 2018 ; Wang et al., 2017 ) and pretrained language models ( Peters et al., 2019 ) of recent years. 2017 ; Peters et al.,
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Overall, the results continue NVIDIA’s record of demonstrating performance leadership in AI training and inference in every round since the launch of the MLPerf benchmarks in 2018. performance boost running the BERT LLM on an L4 GPU. The result was in MLPerf’s so-called “open division,” a category for showcasing new capabilities.
The paper is a case study of syntax acquisition in BERT (Bidirectional Encoder Representations from Transformers). An MLM, BERT gained significant attention around 2018–2019 and is now often used as a base model fine-tuned for various tasks, such as classification.
In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna. BERT excels in understanding context and generating contextually relevant representations for a given text.
Later, Python gained momentum and surpassed all programming languages, including Java, in popularity around 2018–19. Major language models like GPT-3 and BERT often come with Python APIs, making it easy to integrate them into various applications.
Paper Title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" Key Takeaway: Introduced BERT, showcasing the efficacy of pre-training deep bidirectional models, thereby achieving state-of-the-art results on various NLP tasks. This demonstrates a classic case of ‘knowledge conflict'.
The events that brought all of them together were: EMNLP 2018 , one of the biggest conferences on Natural Language Processing in the world, and WMT 2018 , which for many years has been one of the most reputable conferences in the field of machine translation (MT). BERT is a new milestone in NLP.
I worked on an early conversational AI called Marcel in 2018 when I was at Microsoft. In 2018 when BERT was introduced by Google, I cannot emphasize how much it changed the game within the NLP community. As I write this, the bert-base-uncasedmodel on HuggingFace has been downloaded over 53 million times in the last month alone!
Popular Examples include the Bidirectional Encoder Representations from Transformers (BERT) model and the Generative Pre-trained Transformer 3 (GPT-3) model. 2017) “ BERT: Pre-training of deep bidirectional transformers for language understanding ” by Devlin et al. 2018) “ Language models are few-shot learners ” by Brown et al.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. ArXiv 2018. EMNLP 2018. NAACL 2018. NAACL 2018. At the end, I also include the summaries for my own published papers since the last iteration (papers 61-74). Here we go.
An additional 2018 study found that each SLR takes nearly 1,200 total hours per project. BioBERT and similar BERT-based NER models are trained and fine-tuned using a biomedical corpus (or dataset) such as NCBI Disease, BC5CDR, or Species-800. dollars apiece. a text file with one word per line).
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
In particular, I cover unsupervised deep multilingual models such as multilingual BERT. 2017 ; Nicolai & Yarowsky, 2019 ), distant supervision ( Plank & Agić, 2018 ) or machine translation (MT; Zhou et al., 2018 ; Artetxe et al., 2018 ; Artetxe et al., 2018 ) that can be seen in the Figure below.
Over the last three years ( Ruder, 2018 ), fine-tuning ( Howard & Ruder, 2018 ) has superseded the use of feature extraction of pre-trained embeddings ( Peters et al., 2018 ) while pre-trained language models are favoured over models trained on translation ( McCann et al., 2018 ), natural language inference ( Conneau et al.,
They published the original Transformer paper (not quite coincidentally called “Attention is All You Need”) in 2017, and released BERT , an open source implementation, in late 2018, but they never went so far as to build and release anything like OpenAI’s GPT line of services. Will History Repeat Itself?
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. What are Vector Embeddings? Pinecone Used a picture of phrase vector to explain vector embedding. All we need is the vectors for the words.
In 2018, BERT-large made its debut with its 340 million parameters and innovative transformer architecture, setting the benchmark for performance on NLP tasks. For text tasks such as sentence classification, text classification, and question answering, you can use models such as BERT, RoBERTa, and DistilBERT.
BERTBERT uses a transformer-based architecture, which allows it to effectively handle longer input sequences and capture context from both the left and right sides of a token or word (the B in BERT stands for bi-directional). This allows BERT to learn a deeper sense of the context in which words appear.
RoBERTa: A Modified BERT Model for NLP — by Khushboo Kumari An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019.
Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., A whole range of BERT variants have been applied to multimodal settings, mostly involving images and videos together with text (for an example see the figure below). 2019 ) and other variants. VideoBERT ( Sun et al., 2019 ; Wu et al.,
That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for natural language processing, a report on AI said at the end of that year. Google released BERT as open-source software , spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content