This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In 2018, ISTE and General Motors launched a professional development course to train educators on how to use AI for teaching and learning. In five years, we will have something that has been built without any input from teachers and without any shaping around the needs of education,” Culatta said.
With the 2018 launch of RTX technologies and the first consumer GPU built for AI — GeForce RTX — NVIDIA accelerated the shift to AI computing. And it can stay centered on the screen with eyes looking at the camera no matter where the user moves, using Auto Frame and Eye Contact. Magic Mask has completely changed that workflow.
SageMaker AI makes sure that sensitive data stays completely within each customer’s SageMaker environment and will never be shared with a third party. Their validation capabilities include automatic scoring, version comparison, and auto-calculated metrics for properties such as relevance, coverage, and grounded-in-context.
While AI systems can automate many tasks, they should not completely replace human judgment and intuition. The International Data Corporation predicts that the global datasphere will swell from 33 zettabytes in 2018 to a staggering 175 zettabytes by 2025.
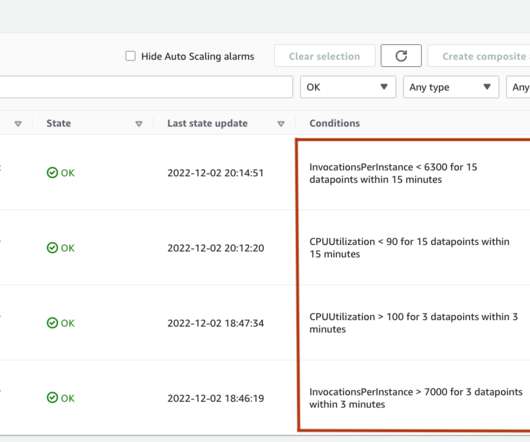
SageMaker supports automatic scaling (auto scaling) for your hosted models. Auto scaling dynamically adjusts the number of instances provisioned for a model in response to changes in your inference workload. When the workload increases, auto scaling brings more instances online. SageMaker supports three auto scaling options.
In zero-shot learning, no examples of task completion are provided in the model. Chain-of-thought Prompting Chain-of-thought prompting leverages the inherent auto-regressive properties of large language models (LLMs), which excel at predicting the next word in a given sequence.
Since 2018, using state-of-the-art proprietary and open source large language models (LLMs), our flagship product— Rad AI Impressions — has significantly reduced the time radiologists spend dictating reports, by generating Impression sections. This post is co-written with Ken Kao and Hasan Ali Demirci from Rad AI.
The auto-complete feature on your smartphone is based on this principle. When you type “how”, the auto-complete will suggest words like “to” or “are”. GPT-3 is a successor to the earlier GPT-2 (released in Feb 2019) and GPT-1 (released in June 2018) models .
Instead they had a row of kiosks, each with a monitor and camera and old school phone that I kid you not looked like: Complete with curly cord. You go up to the device, and it auto-dials a real person. I can't remember what company it was, but they didn't have "live people" at the booth. So how does this work?
We have also seen significant success in using large language models (LLMs) trained on source code (instead of natural language text data) that can assist our internal developers, as described in ML-Enhanced Code Completion Improves Developer Productivity. The pixels in the same colors are attended together.
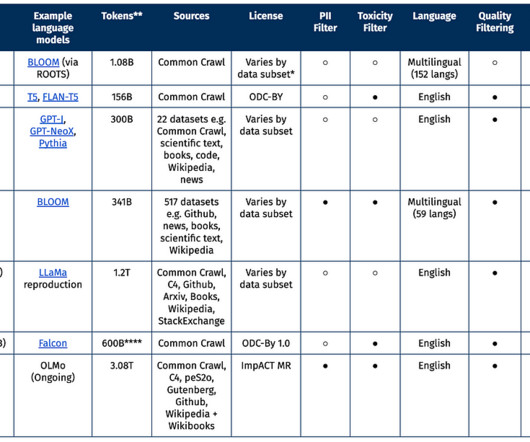
For more details, we also release a data sheet (Gebru et al, 2018) as initial documentation. We recognize that our decision reinforces the assumption of English as the “default” language; we hope to expand OLMo to other languages after initial milestones are completed. ill-formed text, auto-generated website text).
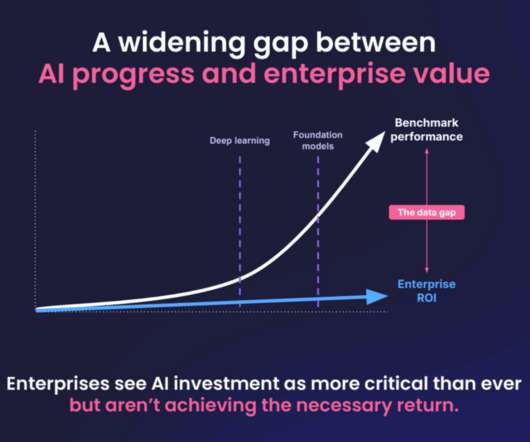
A 2018 study from McKinsey estimated the total global unclaimed value potential from AI/ML at $10-15 trillion, and Foundation Models will enable valuable applications that the firm couldn’t conceive of four years ago.
In 2018, we did a piece of research where we tried to estimate the value of AI and machine learning across geographies, across use cases, and across sectors. One is compared to our first survey conducted in 2018, we see more enterprises investing in AI capability. Firstly, what is the state of the industry?
For example, supporting equitable student persistence in computing research through our Computer Science Research Mentorship Program , where Googlers have mentored over one thousand students since 2018 — 86% of whom identify as part of a historically marginalized group. See some of the datasets and tools we released in 2022 listed below.
The quickstart widget auto-generates a starter config for your specific use case and setup You can use the quickstart widget or the init config command to get started. When you load a config, spaCy checks if the settings are complete and if all values have the correct types. Stanza (StanfordNLP) 1 88.8 Flair 2 89.7 Akbik et al.
It is well known that grading is critical to student learning 2 , in part because it motivates students to complete their assignments. For example, variational auto-encoder started only with 32% precision, but it increased to 74.8% A challenge faced by these platforms is that of grading assignments.
It’s just as important for the model to learn what’s not an entity.We’re ignoring auto-replies and bot messages (e.g. We ran spacy pretrain for one epoch on about 1 billion words of Reddit comments, which completed in roughly 8 hours on a single GTX 2080 Ti. notice about a deleted comment) to exclude those texts from the data.
But ideally, we strive for complete independence of the models in our system so that we can update them without then having to go update every other model in the pipeline – that’s a danger that you can run into. But it’s absolutely critical for most people in our space that you do some type of auto-scaling.
Overview of BERT (Bidirectional Encoder Representations from Transformers) BERT, short for Bidirectional Encoder Representations from Transformers, is a revolutionary LLM introduced by Google in 2018. It is an auto-regressive language model based on the transformer architecture that comes in different sizes: 7B, 13B, 33B and 65B parameters.
Numerous AI tools, including Magic Cut, AI Translate, Auto Subtitles, Text to Speech, AI Voice Cloning, and Eye Contact Correction. It started as a humble startup back in 2018. Its user-friendly interface and features like auto subtitles and text-to-speech make it easy to produce high-quality content quickly.
CapCut , originally launched by a startup called Shenzhen Lianmeng Technology and then acquired by ByteDance in 2018 (the people behind TikTok), is an AI video editor and graphic design tool for multiple platforms. Everyone from complete beginners to seasoned content creators are using it.
The company’s AI can learn from internal documents, email, chat and even old support tickets to automatically resolve auto-route tickets correctly, and quickly surface the most relevant institutional knowledge. But for example, GPT two was launched, I believe in 2018, 2019, and open source, and there were other models like T5.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. Using AWS Trainium and Inferentia based instances, through SageMaker, can help users lower fine-tuning costs by up to 50%, and lower deployment costs by 4.7x, while lowering per token latency. We discuss both methods in this section.
For instance, a financial firm that needs to auto-generate a daily activity report for internal circulation using all the relevant transactions can customize the model with proprietary data, which will include past reports, so that the FM learns how these reports should read and what data was used to generate them.
On a more advanced stance, everyone who has done SQL query optimisation will know that many roads lead to the same result, and semantically equivalent queries might have completely different syntax. 3] provides a more complete survey of Text2SQL data augmentation techniques.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content