

Exploring the Use of LLMs and BERT for Language Tasks
Analytics Vidhya
JANUARY 4, 2024
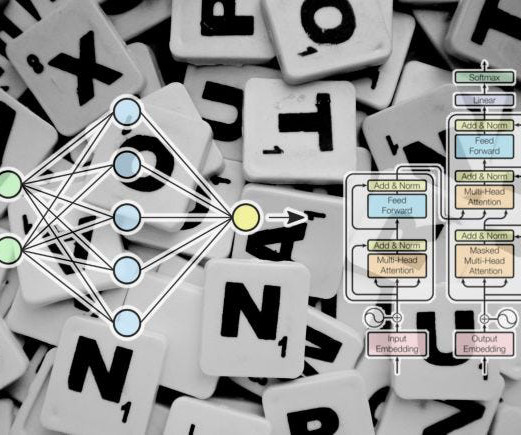
Since the groundbreaking ‘Attention is all you need’ paper in 2017, the Transformer architecture, notably exemplified by ChatGPT, has become pivotal. This article explores […] The post Exploring the Use of LLMs and BERT for Language Tasks appeared first on Analytics Vidhya.











































Let's personalize your content