This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Since the groundbreaking ‘Attention is all you need’ paper in 2017, the Transformer architecture, notably exemplified by ChatGPT, has become pivotal. This article explores […] The post Exploring the Use of LLMs and BERT for Language Tasks appeared first on Analytics Vidhya.
By pre-training on a large corpus of text with a masked language model and next-sentence prediction, BERT captures rich bidirectional contexts and has achieved state-of-the-art results on a wide array of NLP tasks. GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.
Introduction Welcome into the world of Transformers, the deep learning model that has transformed Natural Language Processing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines understand language, from translating texts to analyzing sentiments.
Rewind to 2017, a pivotal moment marked by […] The post Beginners’ Guide to Finetuning Large Language Models (LLMs) appeared first on Analytics Vidhya. In a mere blink, AI has surged, shaping our world.
Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction. LLMs like GPT, BERT, and OPT have harnessed transformers technology. These LLMs can perform various NLP operations, including data extraction.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
Large Language Models (LLMs) like ChatGPT, Google’s Bert, Gemini, Claude Models, and others have emerged as central figures, redefining our interaction with digital interfaces. LLMs like ChatGPT, Google’s BERT, and others exemplify the advancements in this field.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. One of the more popular and useful of the transformer architectures, Bidirectional Encoder Representations from Transformers (BERT), is a language representation model that was introduced in 2018.
As an early adopter of the BERT models in 2017, I hadn’t exactly been convinced computers could interpret human language with similar granularity and contextuality as people do. You can do the same without asking strangers to rank statements.
The BERT (Bidirectional Encoder Representation from Transformers) model was proposed in the paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin, et al, 2019). The BERT model is pre-trained on two tasks
BERT Transformer Source: Image created by the author + Stable Diffusion (All Rights Reserved) In the context of machine learning and NLP, a transformer is a deep learning model introduced in a paper titled “Attention is All You Need” by Vaswani et al. The model was proposed as a way to improve the performance of translation systems.
in 2017, and has since become a popular choice for NLP tasks due to its ability to capture long-range dependencies and context in sequential data. Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. in 2017, marking a departure from the previous reliance on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) for processing sequential data.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. In a recent talk at Google Berlin, Jacob Devlin described how Google are using his BERT architectures internally. In this post we introduce our new wrapping library, spacy-transformers.
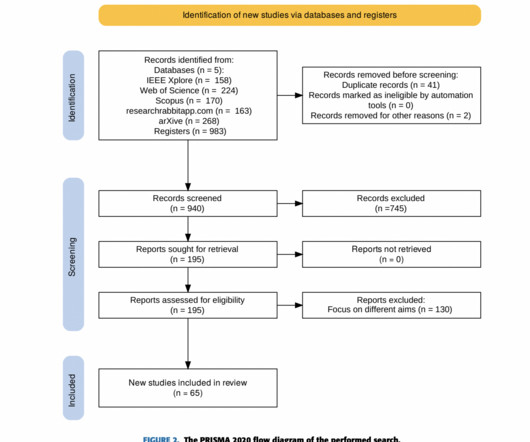
Selye University, Komarno, Slovakia; and the Institute for Computer Science and Control (SZTAKI), Hungarian Research Network (HUN-REN), Budapest, Hungary have presented a systematic literature review (SLR) that analyzes 65 publications from 2017 to December 2023.
Some of the highlights since 2017 include: The original Transformer breaks previous performance records for machine translation. BERT popularizes the pre-training then finetuning process, as well as Transformer-based contextualized word embeddings. The key is a standard BERT sentence embedding. This is now the input to RETRO.
Virtually all current LMs are based on a particularly successful choice of architecture: the so-called Transformer model , invented in 2017. The quintessential examples for this distinction are: The BERT model, which stands for Bidirectional Encoder Representations from Transformers.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
2017 ) and pretrained language models ( Peters et al., 2017 ; Peters et al., In contrast, current models like BERT-Large and GPT-2 consist of 24 Transformer blocks and recent models are even deeper. Multilingual BERT in particular has been the subject of much recent attention ( Pires et al., 2018 ; Akbik et al.,
The burden from growing event volumes is reflected in budgets that are expected to grow from an estimated USD 4 billion in 2017 to over 6 billion by 2020. Regardless of volumes, companies must report these events rapidly to regulators and act quickly on safety signals.
Popular Examples include the Bidirectional Encoder Representations from Transformers (BERT) model and the Generative Pre-trained Transformer 3 (GPT-3) model. 2017) “ BERT: Pre-training of deep bidirectional transformers for language understanding ” by Devlin et al. 2018) “ Language models are few-shot learners ” by Brown et al.
That’s great news for researchers who often work on SLRs because the traditional process is mind-numbingly slow: An analysis from 2017 found that SLRs take, on average, 67 weeks to produce. BioBERT and similar BERT-based NER models are trained and fine-tuned using a biomedical corpus (or dataset) such as NCBI Disease, BC5CDR, or Species-800.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
2017 Transformer models Transformer models were introduced in a 2017 paper by Google researchers called, “Attention Is All You Need” and really revolutionized how we use machine learning to analyze unstructured data. This allows BERT to learn a deeper sense of the context in which words appear.
Famous models like BERT and others, begin their journey with initial training on massive datasets encompassing vast swaths of internet text. ArXiv , 2017, /abs/1706.03762. So, fine-tuning is a way that helps improve model performance by training on specific examples of prompts and desired responses. Vaswani, Ashish, et al.
They published the original Transformer paper (not quite coincidentally called “Attention is All You Need”) in 2017, and released BERT , an open source implementation, in late 2018, but they never went so far as to build and release anything like OpenAI’s GPT line of services. Will History Repeat Itself?
Specifically, it involves using pre-trained transformer models, such as BERT or RoBERTa, to encode text into dense vectors that capture the semantic meaning of the sentences. There is also a short section about generating sentence embeddings from Bert word embeddings, focusing specifically on the average-based transformation technique.
6-Deep Words Representation Not linked to any particular paper disclosed at the conference, but the BERT configuration was widely discussed and often mentioned during presentations and coffee breaks. BERT is a new milestone in NLP. If you’re curious, here’s an overview of the main findings of the evaluation campaign.
Below you will find short summaries of a number of different research papers published in the areas of Machine Learning and Natural Language Processing in the past couple of years (2017-2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova.
Almost all current LMs are based on a highly successful architecture, the Transformer model , introduced in 2017. This trend started with models like the original GPT and ELMo, which had millions of parameters, and progressed to models like BERT and GPT-2, with hundreds of millions of parameters. months on average.
Bert Labs Pvt. Ltd Bert Labs Pvt Ltd is one of the Top AI Startups in India, established in 2017 by Rohit Kochar. Accordingly, Beatoven.ai provides efficient solutions for using creative tools to access royalty-free music and create viral content.
A Brief History of Foundation Models We are in a time where simple methods like neural networks are giving us an explosion of new capabilities, said Ashish Vaswani, an entrepreneur and former senior staff research scientist at Google Brain who led work on the seminal 2017 paper on transformers.
Traditionally, language models are trained to predict the next word in a sentence (top part of Figure 2, in blue), but they can also predict hidden (masked) words in the middle of the sentence, as in Google's BERT model (top part of Figure 2, in orange). Using the AllenNLP demo. Is it still useful?
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many natural language processing (NLP) tasks. To achieve this, we first chunk each document into segments of roughly 256 tokens, which is half of the maximum BERT LM input length.
To learn more about Seq2Seq with Attention, please read: Neural machine translation with attention | Text | TensorFlow Transformers Transformers were introduced in 2017 by Vaswani et al. We then run the input text through the pre-trained BERT model and get the predicted class. as an alternative to RNN-based models.
2017 ), and other tasks due to their increased sample efficiency and performance ( Zhang and Bowman, 2018 ). 2020) fine-tune BERT for quality evaluation with a range of sentence similarity signals. 2017 ), small bottleneck layers that are inserted between the layers of a pre-trained model ( Houlsby et al., 2019 ; Raffel et al.,
The concept of a transformer, an attention-layer-based, sequence-to-sequence (“Seq2Seq”) encoder-decoder architecture, was conceived in a 2017 paper authored by pioneer in deep learning models Ashish Vaswani et al called “Attention Is All You Need”.
This subjective impression is objectively backed up by the heat map below, constructed from a dump of the Microsoft Academic Graph (MAG) circa 2017 [ 21 ]. Since the MAG database petered out around 2017, I filled out the rest of the timeline with topics I knew were important. The base model of BERT [ 103 ] had 12 (!)
In particular, I cover unsupervised deep multilingual models such as multilingual BERT. 2017 ; Nicolai & Yarowsky, 2019 ), distant supervision ( Plank & Agić, 2018 ) or machine translation (MT; Zhou et al., 2017 ) have been shown to achieve reasonable performance using dictionaries of only 25-40 translation pairs.
Unsupervised pretraining was prevalent in NLP this year, mainly driven by BERT ( Devlin et al., A whole range of BERT variants have been applied to multimodal settings, mostly involving images and videos together with text (for an example see the figure below). 2017 ) architecture. 2019 ) and other variants.
For a BERT model on an Edge TPU-based multi-chip mesh, this approach discovers a better distribution of the model across devices using a much smaller time budget compared to non-learned search strategies. For example, when the Transformer model was first published in 2017, a popular GPU was the Nvidia P100. Mechanization.
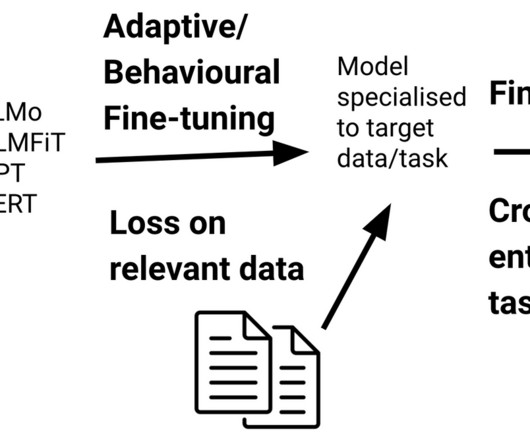
The update fixed outstanding bugs on the tracker, gave the docs a huge makeover, improved both speed and accuracy, made installation significantly easier and faster, and added some exciting new features, like ULMFit/BERT/ELMo-style language model pretraining. ✨ Mar 20: A few days later, we upgraded Prodigy to v1.8 to support spaCy v2.1.
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. In Proceedings of NIPS 2017. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. When is BERT Multilingual?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content