
Train self-supervised vision transformers on overhead imagery with Amazon SageMaker
AWS Machine Learning Blog
AUGUST 16, 2023
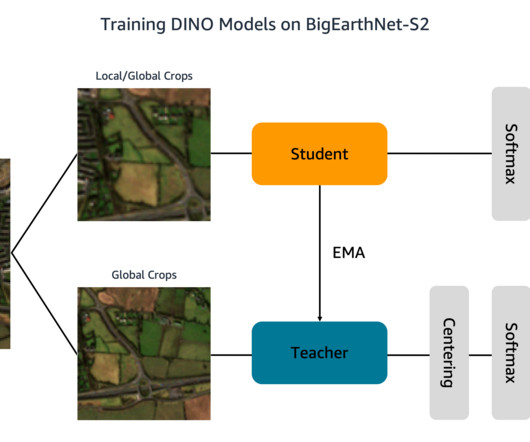
Our solution is based on the DINO algorithm and uses the SageMaker distributed data parallel library (SMDDP) to split the data over multiple GPU instances. The images document the land cover, or physical surface features, of ten European countries between June 2017 and May 2018. tif" --include "_B03.tif" tif" --include "_B04.tif"





















Let's personalize your content