

Alexandr Yarats, Head of Search at Perplexity – Interview Series
Unite.AI
MAY 8, 2024
He began his career at Yandex in 2017, concurrently studying at the Yandex School of Data Analysis. During my school years, I spent a lot of time studying math, probability theory, and statistics, and got an opportunity to play with classical machine learning algorithms such as linear regression and KNN.





















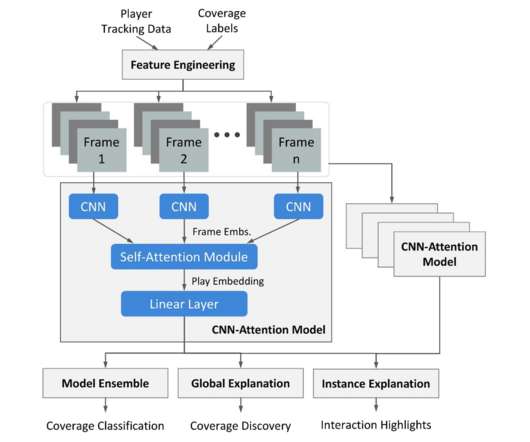







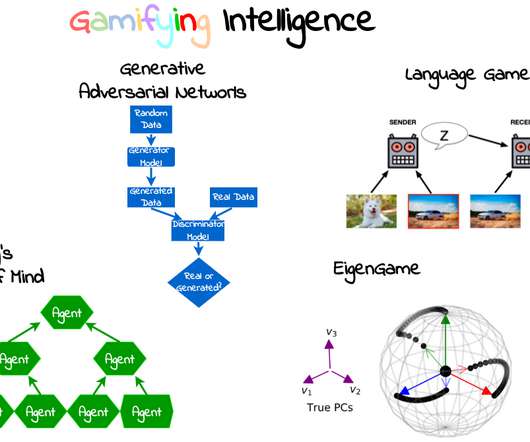




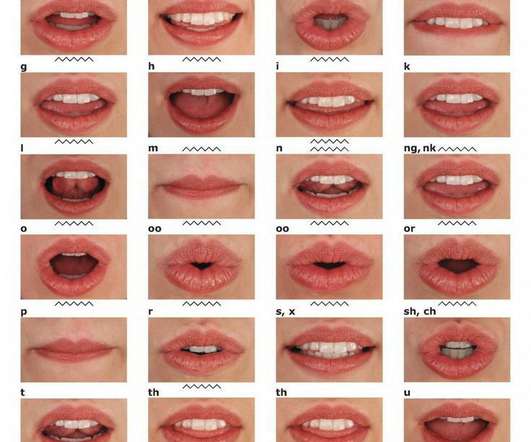






Let's personalize your content