This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
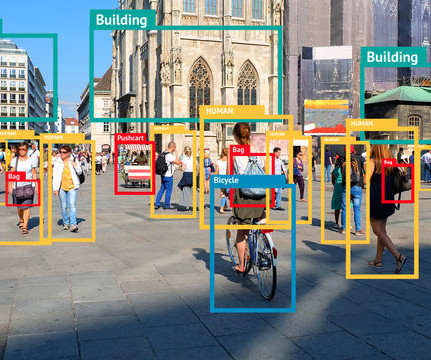
You’ll typically find IoU and mAP used to evaluate the performance of HOG + Linear SVM detectors ( Dalal and Triggs, 2005 ), ConvolutionalNeuralNetwork methods, such as Faster R-CNN ( Girshick et al., 2015 ; Redmon and Farhad, 2016 ), and others. 2015 ), SSD ( Fei-Fei et al., 2015 ; He et al., MobileNets ).
YOLO’s architecture was a significant revolution in the real-time object detection space, surpassing its predecessor – the Region-based ConvolutionalNeuralNetwork (R-CNN). The backbone is a pre-trained ConvolutionalNeuralNetwork (CNN) that extracts low, medium, and high-level feature maps from an input image.
Multiple machine-learning algorithms are used for object detection, one of which is convolutionalneuralnetworks (CNNs). YOLOv1 The Original Before introducing YOLO object detection, researchers used convolutionalneuralnetwork (CNN) based approaches like R-CNN and Fast R-CNN.
In the field of real-time object identification, YOLOv11 architecture is an advancement over its predecessor, the Region-based ConvolutionalNeuralNetwork (R-CNN). Using an entire image as input, this single-pass approach with a single neuralnetwork predicts bounding boxes and class probabilities. Redmon, et al.
Farhadi, signifying a step forward in the real-time object detection space, outperforming its predecessor – the Region-based ConvolutionalNeuralNetwork (R-CNN). It is a single-pass algorithm having only one neuralnetwork to predict bounding boxes and class probabilities using a full image as input. Divvala, R.
Around this time (early 2016), our management team realized that to maintain relevance as a company, we would need to be able to incorporate even more ML into our product. The CNN was a 6-layer neural net with 132 convolution kernels and (don’t laugh!) 90,575 trainable parameters, placing it in the small-feature regime.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. sense2vec reloaded: the updated library sense2vec is a Python package to load and query vectors of words and multi-word phrases based on part-of-speech tags and entity labels.
They have shown impressive performance in various computer vision tasks, often outperforming traditional convolutionalneuralnetworks (CNNs). DataChain is a modern Pythonic data-frame library designed for artificial intelligence. 🐍 Python-friendly data pipelines. 🧠 Data Enrichment and Processing.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content