This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
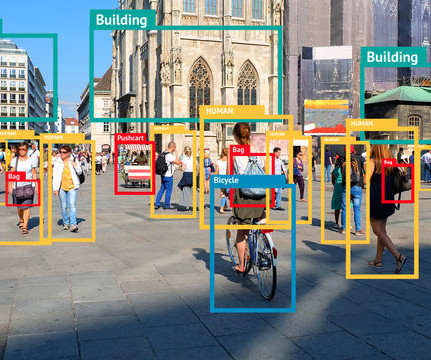
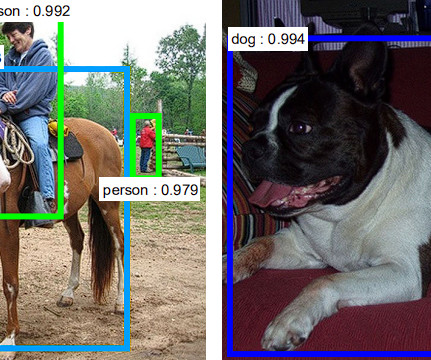
You’ll typically find IoU and mAP used to evaluate the performance of HOG + Linear SVM detectors ( Dalal and Triggs, 2005 ), ConvolutionalNeuralNetwork methods, such as Faster R-CNN ( Girshick et al., 2015 ; Redmon and Farhad, 2016 ), and others. 2015 ), SSD ( Fei-Fei et al., 2015 ; He et al., MobileNets ).
Multiple machine-learning algorithms are used for object detection, one of which is convolutionalneuralnetworks (CNNs). YOLOv1 The Original Before introducing YOLO object detection, researchers used convolutionalneuralnetwork (CNN) based approaches like R-CNN and Fast R-CNN.
However, GoogLeNet demonstrated by using the inception module that depth and width in a neuralnetwork could be increased without exploding computations. GooLeNet – source Historical Context The concept of ConvolutionalNeuralNetworks ( CNNs ) isn’t new.
YOLO in 2015 became the first significant model capable of object detection with a single pass of the network. The previous approaches relied on Region-based ConvolutionalNeuralNetwork (RCNN) and sliding window techniques. The post YOLOX Explained: Features, Architecture and Applications appeared first on viso.ai.
Over the last six months, a powerful new neuralnetwork playbook has come together for Natural Language Processing. This post explains the components of this new approach, and shows how they’re put together in two recent systems. 2016) introduce an attention mechanism that takes a single matrix and outputs a single vector.
These ideas also move in step with the explainability of results. If language grounding is achieved, then the network tells me how a decision was reached. In image captioning a network is not only required to classify objects, but instead to describe objects (including people and things) and their relations in a given image.
Output from Neural Style Transfer – source Neural Style Transfer ExplainedNeural Style Transfer follows a simple process that involves: Three images, the image from which the style is copied, the content image, and a starting image that is just random noise. Johnson et al. What is Perceptual Loss?
This can make it challenging for businesses to explain or justify their decisions to customers or regulators. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks Radford et al. Microsoft Microsoft launched its Language Understanding Intelligent Service in 2016.
We also explained the building blocks of Stable Diffusion and highlighted why its release last year was such a groundbreaking achievement. Source: [ 2 ] In the previous post, we explained the importance of Stable Diffusion [ 3 ]. 2022 [link] Going deeper with convolutions , Szegedy et al. But don’t worry!
VQA frameworks combine two Deep Learning architectures to deliver the final answer: ConvolutionalNeuralNetworks (CNN) for image recognition and Recurrent NeuralNetwork (RNN) (and its special variant Long Short Term Memory networks or LSTM) for NLP processing.
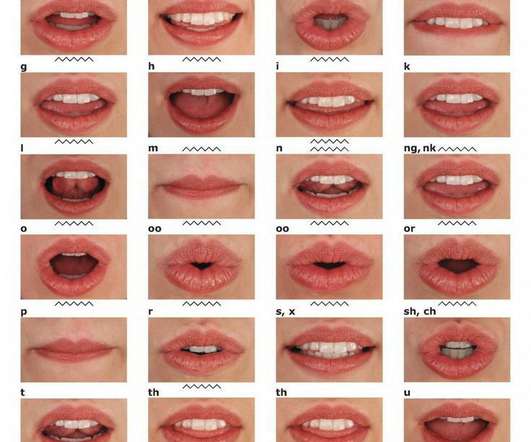
2016) — “ LipNet: End-to-End Sentence-level Lipreading.” [17] 22] On a high level in the architecture, the frames extracted from a video sequence are processed in small sets within a ConvolutionalNeuralNetwork (CNN), [23] while an LSTM-variant runs on the CNN output sequentially to generate output characters.
They have shown impressive performance in various computer vision tasks, often outperforming traditional convolutionalneuralnetworks (CNNs). 2020) EBM : Explainable Boosting Machine (Nori, et al. Positional embeddings : Added to the patch embeddings to retain positional information. 2019; Lou, et al.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content