This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The YOLO Family of Models The first YOLO model was introduced back in 2016 by a team of researchers, marking a significant advancement in object detection technology. Convolution Layer: The concatenated feature descriptor is then passed through a ConvolutionNeuralNetwork.
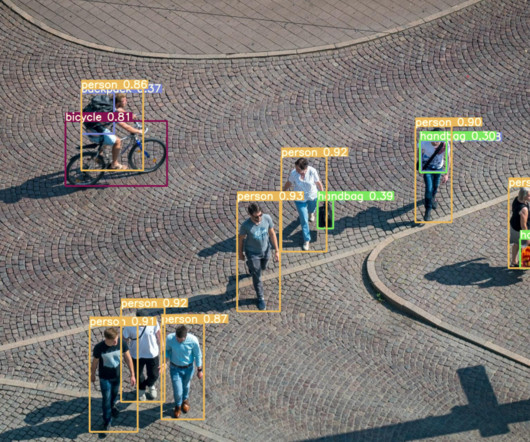
The recent deeplearning algorithms provide robust person detection results. However, deeplearning models such as YOLO that are trained for person detection on a frontal view data set still provide good results when applied for overhead view person counting ( TPR of 95%, FPR up to 0.2% ).
Home Table of Contents Faster R-CNNs Object Detection and DeepLearning Measuring Object Detector Performance From Where Do the Ground-Truth Examples Come? One of the most popular deeplearning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al.
now features deeplearning models for named entity recognition, dependency parsing, text classification and similarity prediction based on the architectures described in this post. You can now also create training and evaluation data for these models with Prodigy , our new active learning-powered annotation tool. Bowman et al.
However, in recent years, human pose estimation accuracy achieved great breakthroughs with ConvolutionalNeuralNetworks (CNNs). The method won the COCO 2016 Keypoints Challenge and is popular for quality and robustness in multi-person settings. Pose Estimation is still a pretty new computer vision technology.
Many studies have been motivated to explore hidden hierarchical patterns in the large volume of weather datasets for weather forecasting due to the recent development of deeplearning techniques, the widespread availability of massive weather observation data, and the advent of information and computer technology.
Today’s boom in computer vision (CV) started at the beginning of the 21 st century with the breakthrough of deeplearning models and convolutionalneuralnetworks (CNN). We split them into two categories – classical CV approaches, and papers based on deep-learning. Find the SURF paper here.
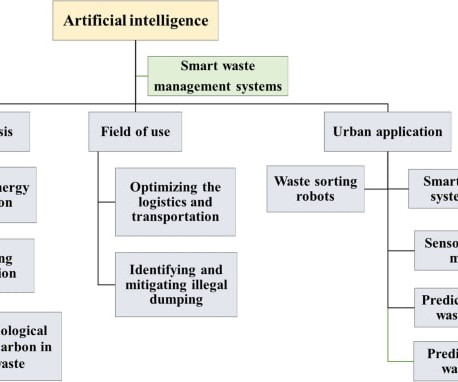
billion tons of municipal solid waste was generated globally in 2016 with experts predicting a steep rise to 3.40 Object Detection : Computer vision algorithms, such as convolutionalneuralnetworks (CNNs), analyze the images to identify and classify waste types (i.e., As per the World Bank, 2.01 billion tons in 2050.
Visual question answering (VQA), an area that intersects the fields of DeepLearning, Natural Language Processing (NLP) and Computer Vision (CV) is garnering a lot of interest in research circles. For visual question answering in DeepLearning using NLP, public datasets play a crucial role. Is aqua the maximum?
Object Detection with DeepLearning for traffic analytics with a video stream Vehicles can recognize the appearance of the cyclist, pedestrian, or car in front of them thanks to class-specific object detection. 2016) introduced a unified framework to detect both cyclists and pedestrians from images.
GoogLeNet’s deeplearning model was deeper than all the previous models released, with 22 layers in total. Increasing the depth of the Machine Learning model is intuitive, as deeper models tend to have more learning capacity and as a result, this increases the performance of a model.
Image analogies patch-based texture in-filling for artistic rendering – source The field of Neural style transfer took a completely new turn with DeepLearning. With deeplearning, the results were impressively good. Here is the journey of NST. Gatys et al. 2015) The research paper by Leon A. Johnson et al.
However, in 2014 a number of high-profile AI labs began to release new approaches leveraging deeplearning to improve performance. The first paper, to the best of our knowledge, to apply neuralnetworks to the image captioning problem was Kiros et al. Attention can enable our inspection and debugging of networks.
They were not wrong: the results they found about the limitations of perceptrons still apply even to the more sophisticated deep-learningnetworks of today. This book effectively killed off interest in neuralnetworks at that time, and Rosenblatt, who died shortly thereafter in a boating accident, was unable to defend his ideas.
The common practice for developing deeplearning models for image-related tasks leveraged the “transfer learning” approach with ImageNet. Practitioners first trained a ConvolutionalNeuralNetwork (CNN) to perform image classification on ImageNet (i.e. What Makes ImageNet Good for Transfer Learning?”
Multiple machine-learning algorithms are used for object detection, one of which is convolutionalneuralnetworks (CNNs). To learn more, book a demo with our team. The YOLO approach is to apply a single convolutionalneuralnetwork (CNN) to the full image.
Deeplearning and ConvolutionalNeuralNetworks (CNNs) have enabled speech understanding and computer vision on our phones, cars, and homes. Thus, the researchers can collect data in multiple homes, which will, in turn, employ SaaS machine learning, and will control the deployed robots. Stone and R.
Viso Suite is the end-to-end, No-Code Computer Vision Platform for Businesses – Learn more What is YOLO You Only Look Once (YOLO) is an object-detection algorithm introduced in 2015 in a research paper by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. The essential mechanics of an object detection model – source.
Most algorithms use a convolutionalneuralnetwork (CNN) to extract features from the image to predict the probability of learned classes. The original YOLO object detector was first released in 2016. As a result, YOLOv7 requires several times cheaper computing hardware than other deeplearning models.
We talked about diffusion in deeplearning, models that utilize it to generate images, and several ways of fine-tuning it to customize your generative model. All of that can leave even the toughest deep-learning practitioner confused. 2022 [link] Going deeper with convolutions , Szegedy et al. But don’t worry!
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. spaCy’s default token-vector encoding settings are a depth 4 convolutionalneuralnetwork with width 96, and hash embeddings with 2000 rows. s2v_freq vector = doc[3:6]._.s2v_vec
In the News Next DeepMind's Algorithm To Eclipse ChatGPT IN 2016, an AI program called AlphaGo from Google’s DeepMind AI lab made history by defeating a champion player of the board game Go. Powered by pluto.fi techxplore.com Sponsor Your AI investing Co-Pilot With Pluto you can: ?
Much the same way we iterate, link and update concepts through whatever modality of input our brain takes — multi-modal approaches in deeplearning are coming to the fore. While an oversimplification, the generalisability of current deeplearning approaches is impressive.
The only filter that I applied was to exclude papers older than 2016, as the goal is to give an overview of the more recent work. On-line Active Reward Learning for Policy Optimisation in Spoken Dialogue Systems Pei-Hao Su, Milica Gasic, Nikola Mrksic, Lina Rojas-Barahona, Stefan Ultes, David Vandyke, Tsung-Hsien Wen, Steve Young.
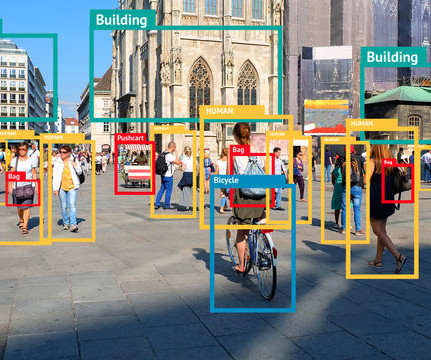
From the development of sophisticated object detection algorithms to the rise of convolutionalneuralnetworks (CNNs) for image classification to innovations in facial recognition technology, applications of computer vision are transforming entire industries. Thus, positioning him as one of the top AI influencers in the world.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content