This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The YOLO Family of Models The first YOLO model was introduced back in 2016 by a team of researchers, marking a significant advancement in object detection technology. Convolution Layer: The concatenated feature descriptor is then passed through a ConvolutionNeuralNetwork.
Hence, rapid development in deep convolutionalneuralnetworks (CNN) and GPU’s enhanced computing power are the main drivers behind the great advancement of computer vision based object detection. Various two-stage detectors include region convolutionalneuralnetwork (RCNN), with evolutions Faster R-CNN or Mask R-CNN.
You’ll typically find IoU and mAP used to evaluate the performance of HOG + Linear SVM detectors ( Dalal and Triggs, 2005 ), ConvolutionalNeuralNetwork methods, such as Faster R-CNN ( Girshick et al., 2015 ; Redmon and Farhad, 2016 ), and others. 2015 ), SSD ( Fei-Fei et al., 2015 ; He et al., MobileNets ).
However, in recent years, human pose estimation accuracy achieved great breakthroughs with ConvolutionalNeuralNetworks (CNNs). The method won the COCO 2016 Keypoints Challenge and is popular for quality and robustness in multi-person settings. Pose Estimation is still a pretty new computer vision technology.
Today’s boom in computer vision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutionalneuralnetworks (CNN). GoogLeNet – Going Deeper with Convolutions (2014) The Google team (Christian Szegedy, Wei Liu, et al.) Find the SURF paper here.
2016) introduce an attention mechanism that takes two sentence matrices, and outputs a single vector: Yang et al. 2016) introduce an attention mechanism that takes a single matrix and outputs a single vector. 2016) presented a model that achieved 86.8% 2016) presented a model that achieved 86.8% 2016) HN-ATT 68.2
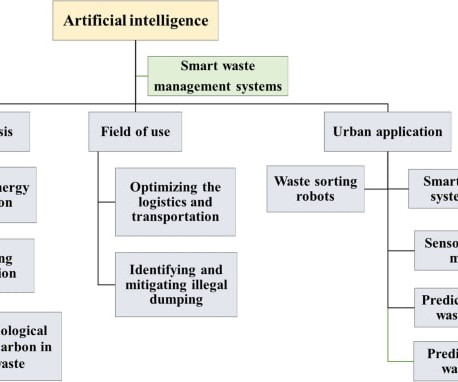
billion tons of municipal solid waste was generated globally in 2016 with experts predicting a steep rise to 3.40 Object Detection : Computer vision algorithms, such as convolutionalneuralnetworks (CNNs), analyze the images to identify and classify waste types (i.e., As per the World Bank, 2.01 billion tons in 2050.
These new approaches generally; Feed the image into a ConvolutionalNeuralNetwork (CNN) for encoding, and run this encoding into a decoder Recurrent NeuralNetwork (RNN) to generate an output sentence. The complete set of generated words is the output sequence (or sentence) of the network.
However, GoogLeNet demonstrated by using the inception module that depth and width in a neuralnetwork could be increased without exploding computations. GooLeNet – source Historical Context The concept of ConvolutionalNeuralNetworks ( CNNs ) isn’t new.
An image can be represented by the relationships between the activations of features detected by a convolutionalneuralnetwork (CNN). Fast Style Transfer (2016) While the previous model produced decent results, it was computationally expensive and slow. Johnson et al. What is Perceptual Loss?
2016) introduced a unified framework to detect both cyclists and pedestrians from images. Autonomous Driving applying Semantic Segmentation in autonomous vehicles Semantic segmentation is now more accurate and efficient thanks to deep learning techniques that utilize neuralnetwork models.
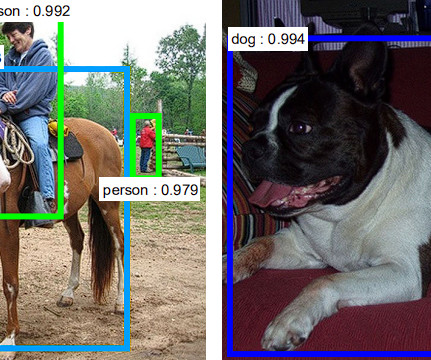
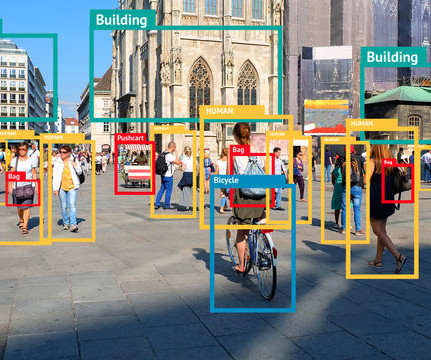
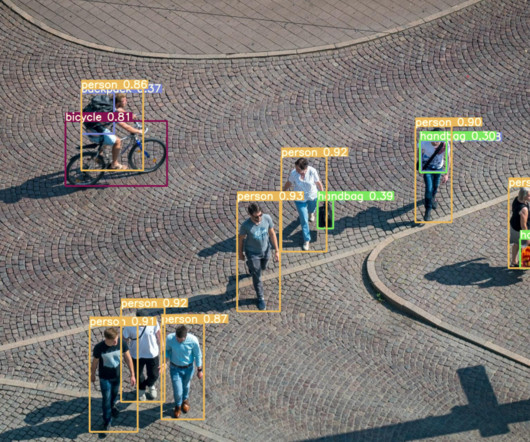
YOLO in 2015 became the first significant model capable of object detection with a single pass of the network. The previous approaches relied on Region-based ConvolutionalNeuralNetwork (RCNN) and sliding window techniques. What is YOLO?
Multiple machine-learning algorithms are used for object detection, one of which is convolutionalneuralnetworks (CNNs). YOLOv1 The Original Before introducing YOLO object detection, researchers used convolutionalneuralnetwork (CNN) based approaches like R-CNN and Fast R-CNN.
Practitioners first trained a ConvolutionalNeuralNetwork (CNN) to perform image classification on ImageNet (i.e. December 10, 2016. The common practice for developing deep learning models for image-related tasks leveraged the “transfer learning” approach with ImageNet. pre-training). fine-tuning). November 21, 2018.
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks Radford et al. 2016) This paper introduced DCGANs, a type of generative model that uses convolutionalneuralnetworks to generate images with high fidelity. Attention Is All You Need Vaswani et al.
Around this time (early 2016), our management team realized that to maintain relevance as a company, we would need to be able to incorporate even more ML into our product. The CNN was a 6-layer neural net with 132 convolution kernels and (don’t laugh!) 90,575 trainable parameters, placing it in the small-feature regime.
This model predicts rainfall for the full satellite area using convolutionalneuralnetworks’ spatial invariance, even if radar data is only available for a smaller area. The first model, sat2rad, is a U-Net-based deep learning model that estimates rainfall in the current satellite frame time step.
YOLO’s architecture was a significant revolution in the real-time object detection space, surpassing its predecessor – the Region-based ConvolutionalNeuralNetwork (R-CNN). The backbone is a pre-trained ConvolutionalNeuralNetwork (CNN) that extracts low, medium, and high-level feature maps from an input image.
Farhadi, signifying a step forward in the real-time object detection space, outperforming its predecessor – the Region-based ConvolutionalNeuralNetwork (R-CNN). It is a single-pass algorithm having only one neuralnetwork to predict bounding boxes and class probabilities using a full image as input. Divvala, R.
Deep learning and ConvolutionalNeuralNetworks (CNNs) have enabled speech understanding and computer vision on our phones, cars, and homes. Stanford University and panel researchers P. Stone and R. Brooks et al. Brooks et al.
In the field of real-time object identification, YOLOv11 architecture is an advancement over its predecessor, the Region-based ConvolutionalNeuralNetwork (R-CNN). Using an entire image as input, this single-pass approach with a single neuralnetwork predicts bounding boxes and class probabilities. Redmon, et al.
This solution is based on several ConvolutionalNeuralNetworks that work in a cascade fashion to locate the face with some landmarks in an image. The first network is called a Proposal Network – it parses the image and selects several bounding boxes that surround an object of interest: a face, in our case.
VQA frameworks combine two Deep Learning architectures to deliver the final answer: ConvolutionalNeuralNetworks (CNN) for image recognition and Recurrent NeuralNetwork (RNN) (and its special variant Long Short Term Memory networks or LSTM) for NLP processing.
One trend that started with our work on Vision Transformers in 2020 is to use the Transformer architecture in computer vision models rather than convolutionalneuralnetworks. Top Computer Vision Computer vision continues to evolve and make rapid progress.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. spaCy’s default token-vector encoding settings are a depth 4 convolutionalneuralnetwork with width 96, and hash embeddings with 2000 rows.
Most algorithms use a convolutionalneuralnetwork (CNN) to extract features from the image to predict the probability of learned classes. The original YOLO object detector was first released in 2016. YOLOv7 applied for computer vision in Aviation – built on Viso Suite What is YOLO in computer vision?
2016 ; Webster et al., While Transformers have achieved large success in NLP, they were—up until recently—less successful in computer vision where convolutionalneuralnetworks (CNNs) still reigned supreme. Pre-trained language models were found to be prone to generating toxic language ( Gehman et al.,
In the News Next DeepMind's Algorithm To Eclipse ChatGPT IN 2016, an AI program called AlphaGo from Google’s DeepMind AI lab made history by defeating a champion player of the board game Go. Powered by pluto.fi June 15, 2023 /PRNewswire/ -- Quantum Computing Inc. ("QCi"
2016) — “ LipNet: End-to-End Sentence-level Lipreading.” [17] 22] On a high level in the architecture, the frames extracted from a video sequence are processed in small sets within a ConvolutionalNeuralNetwork (CNN), [23] while an LSTM-variant runs on the CNN output sequentially to generate output characters.
The only filter that I applied was to exclude papers older than 2016, as the goal is to give an overview of the more recent work. NAACL 2016. Neural activity by brain region, from Wehbe et al. NAACL 2016. The papers are not selected or ordered based on any criteria. I set out to summarise 50 papers. Copenhagen.
From the development of sophisticated object detection algorithms to the rise of convolutionalneuralnetworks (CNNs) for image classification to innovations in facial recognition technology, applications of computer vision are transforming entire industries. Thus, positioning him as one of the top AI influencers in the world.
They have shown impressive performance in various computer vision tasks, often outperforming traditional convolutionalneuralnetworks (CNNs). They have the following advantages: Patch-based approach : The input image is divided into fixed-size patches, which are then linearly embedded. 2019; Lou, et al.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content