This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Computervision enables computers and systems to extract useful information from digital photos, videos, and other visual inputs and to conduct actions or offer recommendations in response to that information. Human vision has an advantage over computervision because it has been around longer.
Save this blog for comprehensive resources for computervision Source: appen Working in computervision and deep learning is fantastic because, after every few months, someone comes up with something crazy that completely changes your perspective on what is feasible. Also, they will show you how huge this domain is.
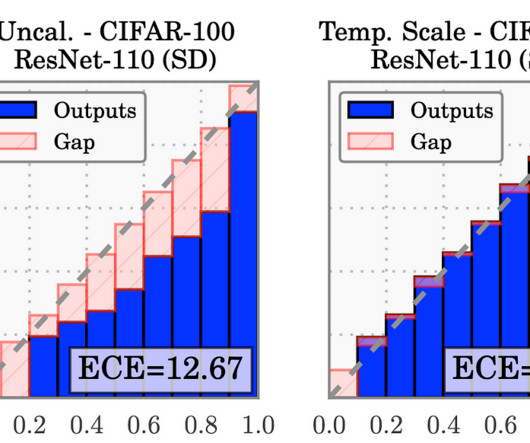
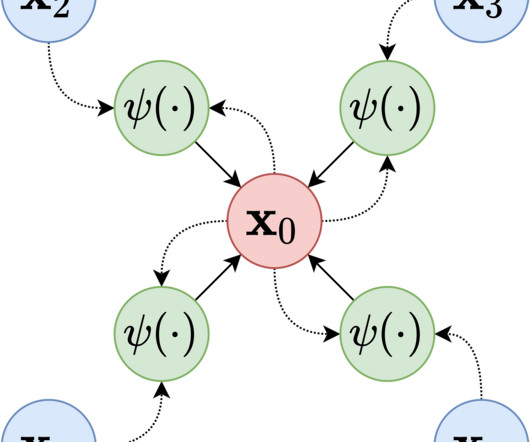
Introduction Deep neuralnetwork classifiers have been shown to be mis-calibrated [1], i.e., their prediction probabilities are not reliable confidence estimates. For example, if a neuralnetwork classifies an image as a “dog” with probability p , p cannot be interpreted as the confidence of the network’s predicted class for the image.
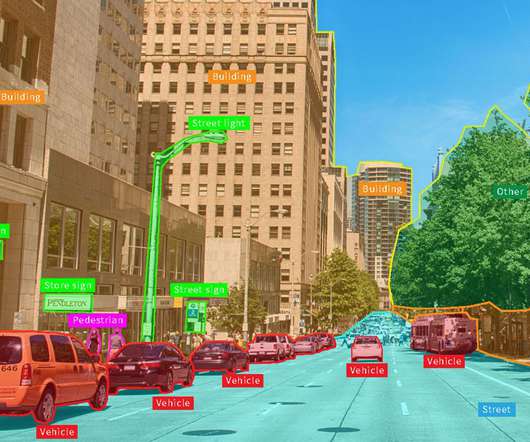
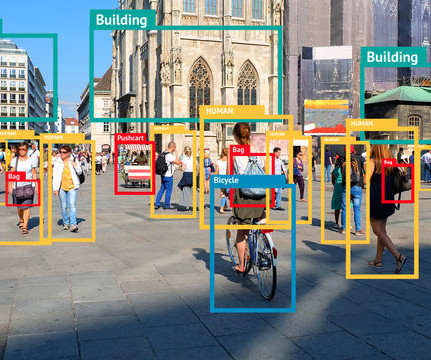
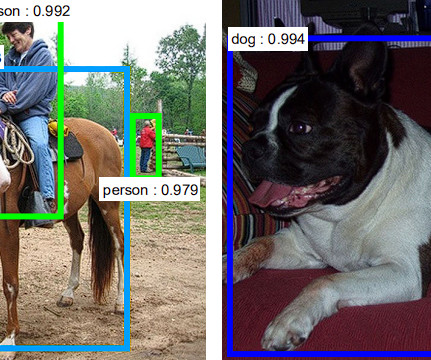
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
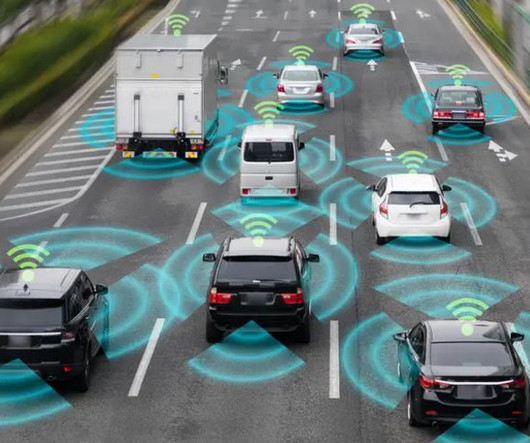
Computervision is a key component of self-driving cars. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision. The eyes of the automobile are computervision models.
Today’s boom in computervision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutional neuralnetworks (CNN). In this article, we dive into some of the most significant research papers that triggered the rapid development of computervision.
Review of Previous YOLO Versions The YOLO (You Only Look Once) family of models has been at the forefront of fast object detection since the original version was published in 2016. The neuralnetwork needs enough depth and width to capture relevant features from the input images.
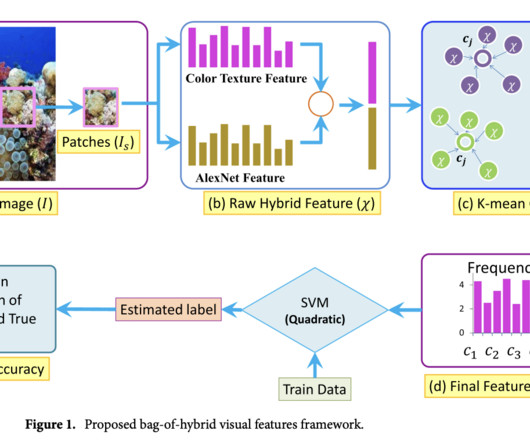
In Australia’s Great Barrier Reef in 2016, bleaching killed 29–50% of the coral. Due to artifacts and ambient noise in the underwater picture, the computervision system finds it challenging to discriminate between the target item in the foreground and the background.
ComputerVision technology has rapidly advanced in recent years and has become an important technology in various industries such as security , healthcare , agriculture , smart city , industrial manufacturing , automotive , and more. provides the leading end-to-end ComputerVision Platform Viso Suite. About us: Viso.ai
For example, image classification, image search engines (also known as content-based image retrieval, or CBIR), simultaneous localization and mapping (SLAM), and image segmentation, to name a few, have all been changed since the latest resurgence in neuralnetworks and deep learning. 2015 ; Redmon and Farhad, 2016 ), and others.
In the following, we will cover the following: Pose Estimation in ComputerVision What is OpenPose? provides the leading ComputerVision Platform, Viso Suite. Global organizations use it to develop, deploy, and scale all computervision applications in one place. How does it work? How to Use OpenPose?
Artificial NeuralNetworks (ANNs) have been demonstrated to be state-of-the-art in many cases of supervised learning, but programming an ANN manually can be a challenging task. These frameworks provide neuralnetwork units, cost functions, and optimizers to assemble and train neuralnetwork models.
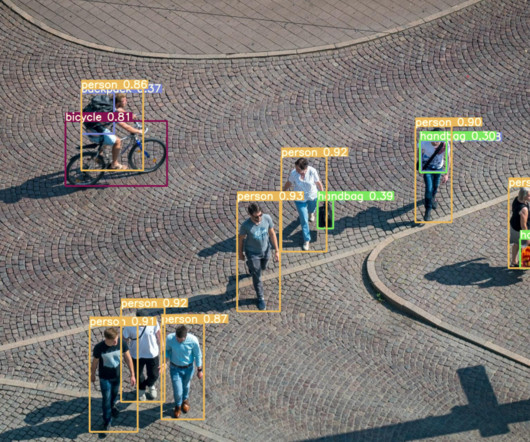
Ever since its launch, the YOLOv7 has been the hottest topic in the ComputerVision developer community, and for the right reasons. What makes YOLOv7 so efficient in performing computervision tasks? Object detection is a branch in computervision that identifies and locates objects in an image, or a video file.
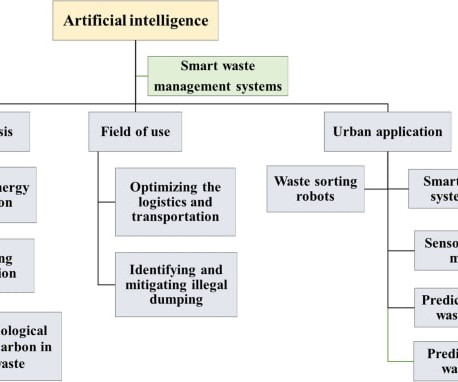
billion tons of municipal solid waste was generated globally in 2016 with experts predicting a steep rise to 3.40 This is where computervision technology can help identify waste, separate it, and ensure its proper disposal. In this article, we will propose computervision as an effective tool for waste management.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
Farhadi, signifying a step forward in the real-time object detection space, outperforming its predecessor – the Region-based Convolutional NeuralNetwork (R-CNN). It is a single-pass algorithm having only one neuralnetwork to predict bounding boxes and class probabilities using a full image as input.
Recent Intersections Between ComputerVision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). The illustration shows how a word is generated at every time step.
In the field of real-time object identification, YOLOv11 architecture is an advancement over its predecessor, the Region-based Convolutional NeuralNetwork (R-CNN). Using an entire image as input, this single-pass approach with a single neuralnetwork predicts bounding boxes and class probabilities.
Over the last six months, a powerful new neuralnetwork playbook has come together for Natural Language Processing. Most neuralnetwork models begin by tokenising the text into words, and embedding the words into vectors. 2016) introduce an attention mechanism that takes a single matrix and outputs a single vector.
After that, this framework has been officially opened to professional communities since 2016. It offers end-to-end functionalities for both artificial intelligence and computervision tasks. Use Cases Frequently Asked Questions (FAQs) About us: Viso Suite is the end-to-end computervision solution for enterprises.
The YOLOv7 algorithm is making big waves in the computervision and machine learning communities. It requires several times cheaper hardware than other neuralnetworks and can be trained much faster on small datasets without any pre-trained weights. The original YOLO object detector was first released in 2016.
Model architectures that qualify as “supervised learning”—from traditional regression models to random forests to most neuralnetworks—require labeled data for training. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks Radford et al. What are some examples of Foundation Models?
This book effectively killed off interest in neuralnetworks at that time, and Rosenblatt, who died shortly thereafter in a boating accident, was unable to defend his ideas. (I Around this time a new graduate student, Geoffrey Hinton, decided that he would study the now discredited field of neuralnetworks.
An image can be represented by the relationships between the activations of features detected by a convolutional neuralnetwork (CNN). Fast Style Transfer (2016) While the previous model produced decent results, it was computationally expensive and slow. A Gram matrix captures the style information of an image in numerical form.
Object detection is a computervision task that uses neuralnetworks to localize and classify objects in images. Multiple machine-learning algorithms are used for object detection, one of which is convolutional neuralnetworks (CNNs). About us : Viso Suite is the complete computervision for enterprises.
YOLOv8 is the newest model in the YOLO algorithm series – the most well-known family of object detection and classification models in the ComputerVision (CV) field. offers the world’s leading end-to-end no-code ComputerVision Platform Viso Suite. Get a demo. The family YOLO model is continuously evolving.
Object detection is one of the crucial tasks in ComputerVision (CV). Computervision researchers introduced YOLO architecture (You Only Look Once) as an object-detection algorithm in 2015. Computervision researchers introduced YOLO architecture (You Only Look Once) as an object-detection algorithm in 2015.
First released in 2016, it quickly gained traction due to its intuitive design and robust capabilities. In industry, it powers applications in computervision, natural language processing, and reinforcement learning. Architecture and Design Keras provides a high-level API that simplifies the creation of neuralnetwork models.
Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computervision and pattern recognition (pp. In Proceedings of the IEEE conference on computervision and pattern recognition (pp. NeuralNetworks, 64, 59–63. Intriguing properties of neuralnetworks.
The ImageNet dataset, featuring natural images, contains 14,197,122 annotated images organized in 1000 classes and is commonly used as a benchmark for many computervision models⁸. Practitioners first trained a Convolutional NeuralNetwork (CNN) to perform image classification on ImageNet (i.e. December 10, 2016.
Visual question answering (VQA), an area that intersects the fields of Deep Learning, Natural Language Processing (NLP) and ComputerVision (CV) is garnering a lot of interest in research circles. Its proposed neural architecture can provide fairly accurate answers to natural language questions about images.
Deep learning and Convolutional NeuralNetworks (CNNs) have enabled speech understanding and computervision on our phones, cars, and homes. Stanford University and panel researchers P. Stone and R. Brooks et al. Brooks et al. Moreover, they can answer any question and communicate naturally.
Object detection is a fundamental task in computervision, and YOLOX plays a fair role in improving it. YOLO in 2015 became the first significant model capable of object detection with a single pass of the network. The previous approaches relied on Region-based Convolutional NeuralNetwork (RCNN) and sliding window techniques.
More recently, contrastive learning gained popularity in self-supervised representation learning in computervision and speech ( van den Oord, 2018 ; Hénaff et al., 2016 ; Webster et al., 8) Image Transformers The Vision Transformer ( Dosovitskiy et al., 2020 ; Wallace et al., 2020 ; Carlini et al.,
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. spaCy’s default token-vector encoding settings are a depth 4 convolutional neuralnetwork with width 96, and hash embeddings with 2000 rows. That work is now due for an update.
In Proceedings of the IEEE International Conference on ComputerVision, pp. Distributionally robust neuralnetworks for group shifts: On the importance of regularization for worst-case generalization. In Association for Computational Linguistics (ACL), pp. Selective classification for deep neuralnetworks.
However, since each token (and the previous hidden state) is fed consecutively into the same neuralnetwork (also referred to as cell), a long chain of operations must be computed during forward pass, which also leads to long gradient computation chains during optimization, also called multi-step backpropagation.
The release of Google Translate’s neural models in 2016 reported large performance improvements: “60% reduction in translation errors on several popular language pairs”. Figure 1: adversarial examples in computervision (left) and natural language processing tasks (right). Open-ended generation is prone to repetition.
In computervision, supervised pre-trained models such as Vision Transformer [2] have been scaled up [3] and self-supervised pre-trained models have started to match their performance [4]. In Advances in Neural Information Processing Systems 29 (NIPS 2016). In Proceedings of NAACL 2021. De Sa, C., Khashabi, D.,
In the News Next DeepMind's Algorithm To Eclipse ChatGPT IN 2016, an AI program called AlphaGo from Google’s DeepMind AI lab made history by defeating a champion player of the board game Go. June 15, 2023 /PRNewswire/ -- Quantum Computing Inc. ("QCi" Powered by pluto.fi
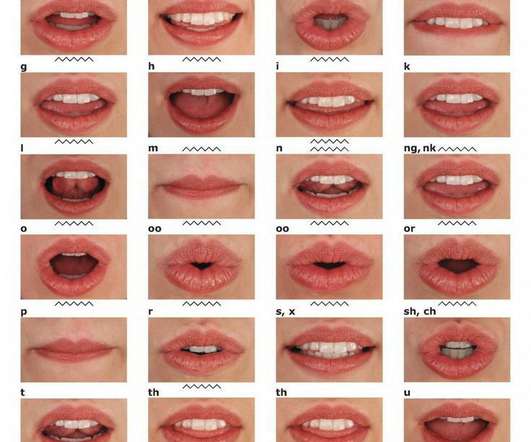
Recent Intersections Between ComputerVision and Natural Language Processing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). 2016) — “ LipNet: End-to-End Sentence-level Lipreading.” [17]
Over the past decade, the field of computervision has experienced monumental artificial intelligence (AI) breakthroughs. This blog will introduce you to the computervision visionaries behind these achievements. Viso Suite is the end-to-End, No-Code ComputerVision Solution.
Jump Right To The Downloads Section Training the YOLOv8 Object Detector for OAK-D Introduction Object detection is one of the most exciting problems in the computervision domain. And, of course, all of this wouldn’t have been possible without the power of Deep NeuralNetworks (DNNs) and the massive computation by NVIDIA GPUs.
This uses advanced computervision techniques, specifically a Vision Transformer model, to analyze and organize photos of properties. Vision Transformers(ViT) ViT is a type of machine learning model that applies the transformer architecture, originally developed for natural language processing, to image recognition tasks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content