This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Up until now, object detection in images using computervision models faced a major roadblock of a few seconds of lag due to processing time. However, the YOLOv8 computervision model's release by Ultralytics has broken through the processing delay. What Makes YOLOv8 Standout?
Computervision enables computers and systems to extract useful information from digital photos, videos, and other visual inputs and to conduct actions or offer recommendations in response to that information. Human vision has an advantage over computervision because it has been around longer.
Yehuda was also a co-founder of the software company ExploreGate, where he served as CEO from 2012 to 2016, as well as co-founder of MobileAccess, where he served as President of the company through its acquisition by Corning Incorporated In 2011. Cipia’s embedded solutions are fully private and secure.
Save this blog for comprehensive resources for computervision Source: appen Working in computervision and deep learning is fantastic because, after every few months, someone comes up with something crazy that completely changes your perspective on what is feasible. Also, they will show you how huge this domain is.
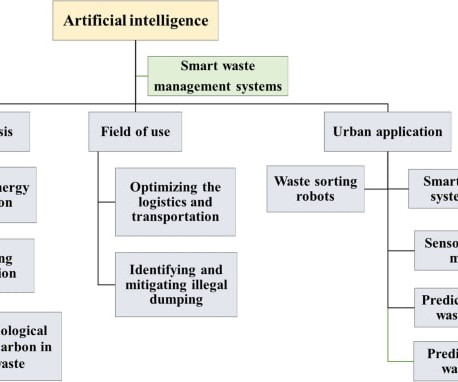
billion tons a year globally by 2050, up from 2 billion in 2016. AI and computer-vision-powered sorting tech and robotic composting When truckloads of waste arrive at composting facilities, the contents need to be sorted, making sure there are no contaminants as that will disrupt the composting process or result in low-quality compost.
Apple prioritizes computervision , natural language processing , voice recognition, and healthcare to enhance its products. Likewise, Microsoft strengthens its cloud and enterprise software through acquisitions in natural language processing , computervision , and cybersecurity.
Amir Hever is the CEO and co-founder of UVeye , a deep learning computervision startup that is setting the global standard for vehicle inspection with fast and accurate anomaly detection to identify issues or threats facing the automotive and security industries. UVeye is Hever’s third venture.
In 2016, as I was beginning my radiology residency, DeepMind's AlphaGo defeated world champion Go player Lee Sedol. AI will further enhance navigation capabilities with locally embedded computervision and path planning models.
The rapid advance of technology and its impact on skilled and unskilled workers has hovered over the American landscape since the 2016 presidential election. has introduced “Maternity Warden,” a computervision monitoring device that monitors close-up dry cows. How Will AI Impact Inequality And Energy?
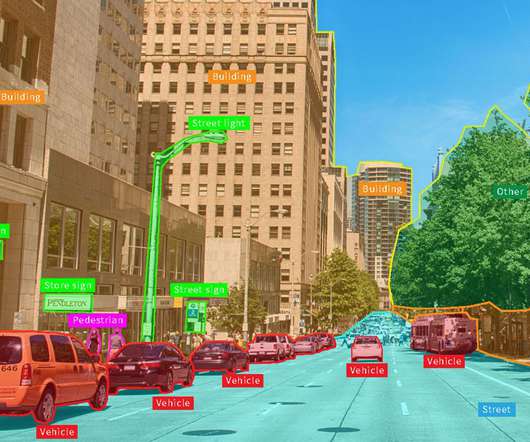
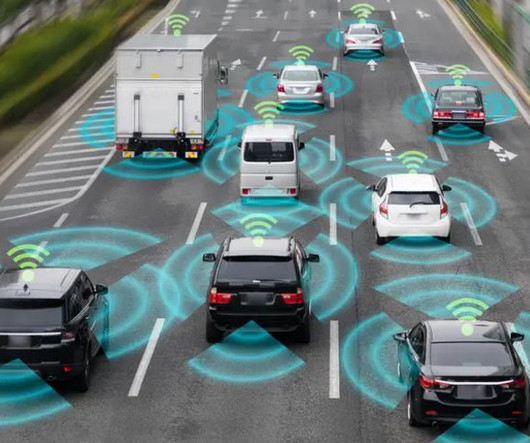
Computervision is a key component of self-driving cars. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision. The eyes of the automobile are computervision models.
ComputerVision technology has rapidly advanced in recent years and has become an important technology in various industries such as security , healthcare , agriculture , smart city , industrial manufacturing , automotive , and more. provides the leading end-to-end ComputerVision Platform Viso Suite. About us: Viso.ai
Today’s boom in computervision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutional neural networks (CNN). In this article, we dive into some of the most significant research papers that triggered the rapid development of computervision.
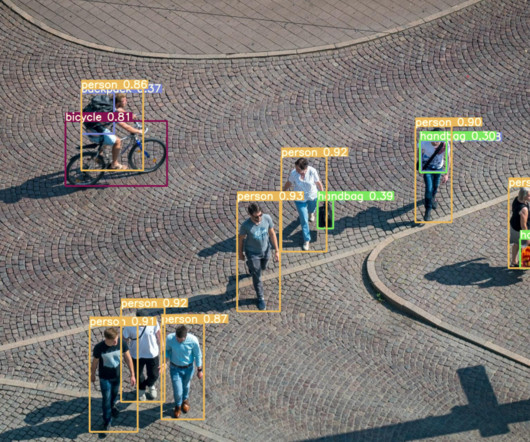
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
Review of Previous YOLO Versions The YOLO (You Only Look Once) family of models has been at the forefront of fast object detection since the original version was published in 2016. The upgrades provide a strong foundation for future innovation in this critical computervision capability.
Photo by Maud CORREA on Unsplash ComputerVision Using ComputerVision Introduction Crack detection is crucial in monitoring the health of infrastructural buildings. Therefore, Now we conquer this problem of detecting the cracks using image processing methods, deep learning algorithms, and ComputerVision.
In the following, we will cover the following: Pose Estimation in ComputerVision What is OpenPose? provides the leading ComputerVision Platform, Viso Suite. Global organizations use it to develop, deploy, and scale all computervision applications in one place. How does it work? How to Use OpenPose?
Ever since its launch, the YOLOv7 has been the hottest topic in the ComputerVision developer community, and for the right reasons. What makes YOLOv7 so efficient in performing computervision tasks? Object detection is a branch in computervision that identifies and locates objects in an image, or a video file.
In Australia’s Great Barrier Reef in 2016, bleaching killed 29–50% of the coral. Due to artifacts and ambient noise in the underwater picture, the computervision system finds it challenging to discriminate between the target item in the foreground and the background.
2015 ; Redmon and Farhad, 2016 ), and others. 2016 ), or a smaller, more compact network for resource-contained devices (e.g., Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? 2015 ), SSD ( Fei-Fei et al.,
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. billion to a projected $574.78 billion in 2017 to a projected $37.68
I received my masters in Civil/Environmental Engineering from Stanford University in 2016. PowerAI uses computervision and machine learning to automate a huge portion of the fault detection process. During this time I took classes specializing in energy engineering, building my interest that started overseas.
Secure Redact uses advanced machine learning and computervision techniques to recognize and redact personally identifiable information (PII) in various image and video contexts, such as faces and license plates. How does Secure Redact leverage AI to automate the redaction of personal and sensitive data in video footage?
billion tons of municipal solid waste was generated globally in 2016 with experts predicting a steep rise to 3.40 This is where computervision technology can help identify waste, separate it, and ensure its proper disposal. In this article, we will propose computervision as an effective tool for waste management.
Both the images and tabular data discussed in this post were originally made available and published to GitHub by Ahmed and Moustafa (2016). Summary This post demonstrated how to use computervision enabled by a foundation model to improve a classic ML use case using the SageMaker platform. References Ahmed, E.
About us : Viso Suite is an End-to-End ComputerVision Infrastructure that provides all the tools required to train, build, deploy, and manage computervision applications at scale. To get started with enterprise-grade computervision infrastructure, book a demo of Viso Suite with our team of experts.
And why is OpenCV so popular in the ComputerVision Industry? Hence, the world’s leading companies across industries use OpenCV to develop their computervision systems. What is ComputerVision? Leading organizations use it to build, deploy and scale real-world computervision applications.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
Nearly 250 years later, in 2016, Amazon executed a similar stunt. However, the real breakthrough in this AI advancement, which integrated technologies such as ComputerVision, Sensor Fusion, and Deep Learning, relied significantly on about 1000 individuals in India.
For enterprise applications using TensorFlow, check out the computervision platform Viso Suite which automates the end-to-end infrastructure around serving a TensorFlow model at scale. PyTorch Overview PyTorch was first introduced in 2016. One of the easiest ways to get started with TensorFlow Serving is with Docker.
Posted by Rodrigo Benenson, Research Scientist, Google Research Open Images is a computervision dataset covering ~9 million images with labels spanning thousands of object categories. Researchers around the world use Open Images to train and evaluate computervision models.
2016) introduce an attention mechanism that takes two sentence matrices, and outputs a single vector: Yang et al. 2016) introduce an attention mechanism that takes a single matrix and outputs a single vector. 2016) presented a model that achieved 86.8% 2016) presented a model that achieved 86.8% For example, Bowman et al.
Recent Intersections Between ComputerVision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). 2016)[ 91 ] You et al. Source : You et al. 2017) [ 96 ].
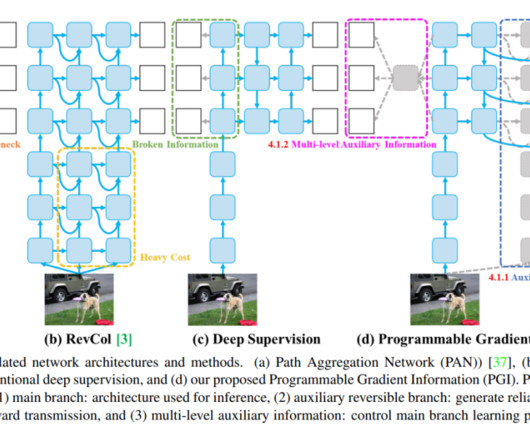
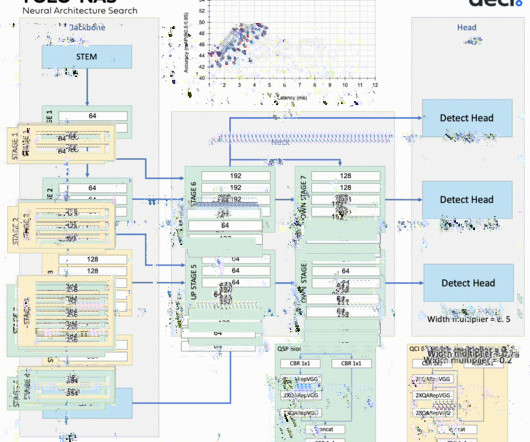
At this time, the only computervision task supported by YOLOv9 is object detection. YOLOv2 Released in 2016, it could detect 9000+ object categories. The model architecture uses a Cross-stage Partial (CSP) Connection block as the backbone for a better gradient flow to reduce computational cost. 65.0% + AF [ 63 ] 43.6
After that, this framework has been officially opened to professional communities since 2016. It offers end-to-end functionalities for both artificial intelligence and computervision tasks. Use Cases Frequently Asked Questions (FAQs) About us: Viso Suite is the end-to-end computervision solution for enterprises.
The YOLOv7 algorithm is making big waves in the computervision and machine learning communities. provides the only end-to-end computervision application platform, Viso Suite. The software infrastructure is used by leading organizations to gather data, train YOLOv7 models, and deliver computervision applications.
Object detection is one of the crucial tasks in ComputerVision (CV). Computervision researchers introduced YOLO architecture (You Only Look Once) as an object-detection algorithm in 2015. About Us: At Viso.ai, we power Viso Suite, the most complete end-to-end computervision platform.
YOLOv8 is the newest model in the YOLO algorithm series – the most well-known family of object detection and classification models in the ComputerVision (CV) field. offers the world’s leading end-to-end no-code ComputerVision Platform Viso Suite. Get a demo.
The first version of YOLO was introduced in 2016 and changed how object detection was performed by treating object detection as a single regression problem. In the subfield of computervision, the competition for cutting-edge object detection is fierce. Ability to detect objects in images quickly and dependably.
The ImageNet dataset, featuring natural images, contains 14,197,122 annotated images organized in 1000 classes and is commonly used as a benchmark for many computervision models⁸. This “transfer learning” approach was so successful that it became the de-facto standard for solving a broad range of computervision problems.
Fast Style Transfer (2016) While the previous model produced decent results, it was computationally expensive and slow. In 2016, Justin Johnson, Alexandre Alahi, and Li Fei-Fei addressed computation limitations by publishing their research paper titled “Perceptual Losses for Real-Time Style Transfer and Super-Resolution.”
Visual Question Answering (VQA) stands at the intersection of computervision and natural language processing, posing a unique and complex challenge for artificial intelligence. is a significant benchmark dataset in computervision and natural language processing. or Visual Question Answering version 2.0,
2016) This paper introduced DCGANs, a type of generative model that uses convolutional neural networks to generate images with high fidelity. The company is best known for NLP tools, but also enables the use of computervision, audio, and multimodal models. Attention Is All You Need Vaswani et al.
In Proceedings of the IEEE conference on computervision and pattern recognition (pp. In Proceedings of the IEEE conference on computervision and pattern recognition (pp. In Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition (pp. 2012; Otsu, 1979; Long et al., 3431–3440).
Rethinking the inception architecture for computervision. Proceedings of the IEEE conference on computervision and pattern recognition. Proceedings of the IEEE international conference on computervision. Eighth JPL Airborne Geoscience Workshop. 4] Szegedy, Christian, et al. When does label smoothing help?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content