This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The release of Google Translate’s neural models in 2016 reported large performance improvements: “60% reduction in translation errors on several popular language pairs”. Figure 1: adversarial examples in computer vision (left) and naturallanguageprocessing tasks (right).
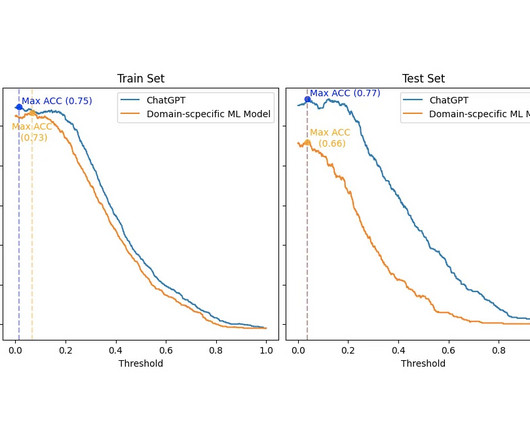
SA is a very widespread NaturalLanguageProcessing (NLP). So, to make a viable comparison, I had to: Categorize the dataset scores into Positive , Neutral , or Negative labels. Interestingly, ChatGPT tended to categorize most of these neutral sentences as positive. finance, entertainment, psychology).
ChatGPT released by OpenAI is a versatile NaturalLanguageProcessing (NLP) system that comprehends the conversation context to provide relevant responses. Although little is known about construction of this model, it has become popular due to its quality in solving naturallanguage tasks.
Over the last six months, a powerful new neural network playbook has come together for NaturalLanguageProcessing. A four-step strategy for deep learning with text Embedded word representations, also known as “word vectors”, are now one of the most widely used naturallanguageprocessing technologies.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately? However, in this sea of complexity, NLP offers a ray of hope.
This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Devlin et al.
Visual Question Answering (VQA) stands at the intersection of computer vision and naturallanguageprocessing, posing a unique and complex challenge for artificial intelligence. is a significant benchmark dataset in computer vision and naturallanguageprocessing. or Visual Question Answering version 2.0,
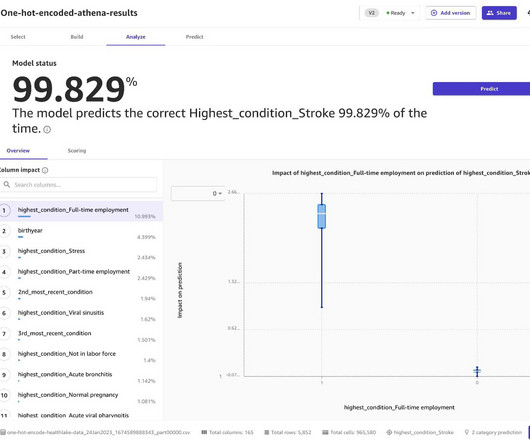
Use naturallanguageprocessing (NLP) in Amazon HealthLake to extract non-sensitive data from unstructured blobs. Perform one-hot encoding To unlock the full potential of the data, we use a technique called one-hot encoding to convert categorical columns, like the condition column, into numerical data.
Introduction In naturallanguageprocessing, text categorization tasks are common (NLP). We use categorical crossentropy for loss along with sigmoid as an activation function for our model Figure 14 Figure 15 shows how we tracked convergence for the neural network. Uysal and Gunal, 2014). Manning C. and Schutze H.,
Transformers and transfer-learning NaturalLanguageProcessing (NLP) systems face a problem known as the “knowledge acquisition bottleneck”. We provide an example component for text categorization. We have updated our library and this blog post accordingly. Modern transfer learning techniques are bearing this out.
The Quora dataset is an example of an important type of NaturalLanguageProcessing problem: text-pair classification. We want to learn a single categorical label for the pair of questions, so we want to get a single vector for the pair of sentences. This gives us two 2d arrays — one per sentence.
Parallel computing Parallel computing refers to carrying out multiple processes simultaneously, and can be categorized according to the granularity at which parallelism is supported by the hardware. Review of the technology In this section, we review different components of the technology.
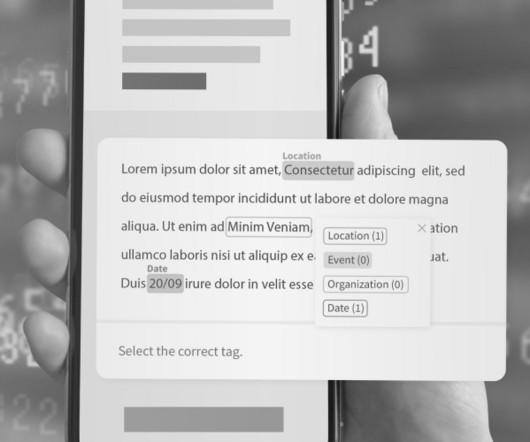
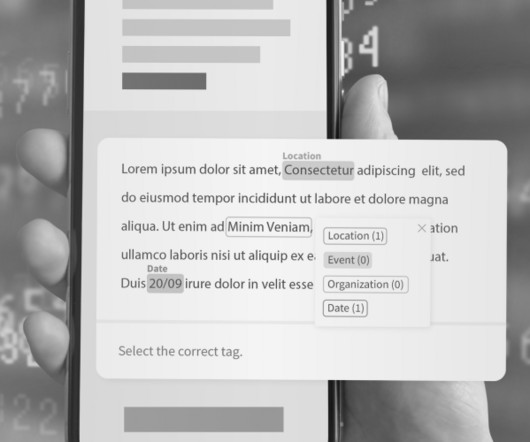
Named Entity Recognition (NER) is a naturallanguageprocessing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. What is Named Entity Recognition (NER)?
Named Entity Recognition (NER) is a naturallanguageprocessing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. What is Named Entity Recognition (NER)?
Large language models or LLMs are AI systems that use transformers to understand and create human-like text. Hugging Face , started in 2016, aims to make NLP models accessible to everyone. It is based in New York and was founded in 2016." " question = "Where is Hugging Face based?"
Vision Transformers(ViT) ViT is a type of machine learning model that applies the transformer architecture, originally developed for naturallanguageprocessing, to image recognition tasks. and 8B base and chat models, supporting both English and Chinese languages. or amenities. 2019; Lou, et al.
It's a Bird, It's a Plane, It's Superman (not antonyms) Many people would categorize a pair of words as opposites if they represent two mutually exclusive options/entities in the world, like male and female. CogALex 2016. black and white , and tuna and salmon. Enrico Santus, Qin Lu, Alessandro Lenci, Chu-Ren Huang. PACLIC 2014. [6]
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content