This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Computervision enables computers and systems to extract useful information from digital photos, videos, and other visual inputs and to conduct actions or offer recommendations in response to that information. Human vision has an advantage over computervision because it has been around longer.
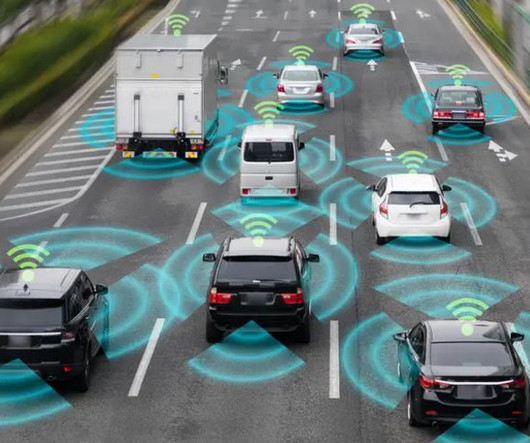
Computervision is a key component of self-driving cars. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision. The eyes of the automobile are computervision models.
Photo by Maud CORREA on Unsplash ComputerVision Using ComputerVision Introduction Crack detection is crucial in monitoring the health of infrastructural buildings. Therefore, Now we conquer this problem of detecting the cracks using image processing methods, deep learning algorithms, and ComputerVision.
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
2015 ; Redmon and Farhad, 2016 ), and others. 2016 ), or a smaller, more compact network for resource-contained devices (e.g., Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? 2015 ), SSD ( Fei-Fei et al.,
Both the images and tabular data discussed in this post were originally made available and published to GitHub by Ahmed and Moustafa (2016). Answers can come in the form of categorical, continuous value, or binary responses. IJCCI 2016-Proceedings of the 8th International Joint Conference on Computational Intelligence, 3, 62–68.
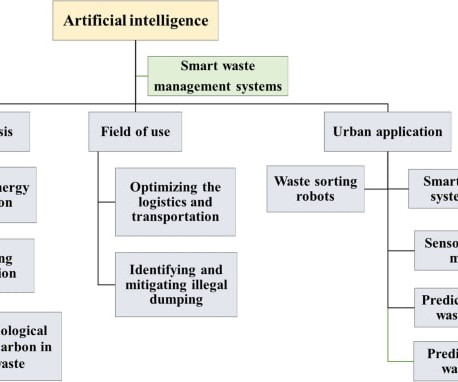
billion tons of municipal solid waste was generated globally in 2016 with experts predicting a steep rise to 3.40 This is where computervision technology can help identify waste, separate it, and ensure its proper disposal. In this article, we will propose computervision as an effective tool for waste management.
And why is OpenCV so popular in the ComputerVision Industry? Hence, the world’s leading companies across industries use OpenCV to develop their computervision systems. What is ComputerVision? Leading organizations use it to build, deploy and scale real-world computervision applications.
2016) introduce an attention mechanism that takes two sentence matrices, and outputs a single vector: Yang et al. 2016) introduce an attention mechanism that takes a single matrix and outputs a single vector. 2016) presented a model that achieved 86.8% 2016) presented a model that achieved 86.8% For example, Bowman et al.
Visual Question Answering (VQA) stands at the intersection of computervision and natural language processing, posing a unique and complex challenge for artificial intelligence. is a significant benchmark dataset in computervision and natural language processing. or Visual Question Answering version 2.0,
YOLOv8 is the newest model in the YOLO algorithm series – the most well-known family of object detection and classification models in the ComputerVision (CV) field. offers the world’s leading end-to-end no-code ComputerVision Platform Viso Suite. Get a demo. For example, you can use yolov8n-cls.pt
2016) This paper introduced DCGANs, a type of generative model that uses convolutional neural networks to generate images with high fidelity. The company is best known for NLP tools, but also enables the use of computervision, audio, and multimodal models. Attention Is All You Need Vaswani et al.
The release of Google Translate’s neural models in 2016 reported large performance improvements: “60% reduction in translation errors on several popular language pairs”. Figure 1: adversarial examples in computervision (left) and natural language processing tasks (right). Open-ended generation is prone to repetition.
This uses advanced computervision techniques, specifically a Vision Transformer model, to analyze and organize photos of properties. Vision Transformers(ViT) ViT is a type of machine learning model that applies the transformer architecture, originally developed for natural language processing, to image recognition tasks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content