This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Founded in 2016, Satisfi Labs is a leading conversational AI company. While Yelp is still good and well, in 2016 we aligned on a new vision and I co-founded Satisfi Labs with the same investors. We had a scheduled press release to announce our patent-pending Context-based NLP upgrade for December 6, 2022.
Natural language processing (NLP) research predominantly focuses on developing methods that work well for English despite the many positive benefits of working on other languages. At a higher level, algorithms are biased and discriminate against speakers of non-English languages or simply with different accents. Each feature has 5.93
Are you looking to study or work in the field of NLP? For this series, NLP People will be taking a closer look at the NLP education landscape in different parts of the world, including the best sites for job-seekers and where you can go for the leading NLP-related education programs on offer.
Back in 2016, after a couple of years working as a Product Engineer, I started to entertain the idea of a startup as a technical co-founder. In order to do this, we employ a series of proprietary algorithms to analyze the top-ranking articles to determine how they got there.
Enter Natural Language Processing (NLP) and its transformational power. Consider a scenario where legal practitioners are armed with clever algorithms capable of analyzing, comprehending, and extracting key insights from massive collections of legal papers. This is the promise of NLP: to transform the way we approach legal discovery.
Groq, founded in 2016 by Jonathan Ross, a former Google engineer, has been quietly developing specialized chips designed to accelerate AI workloads, particularly in the realm of language processing. This financial windfall, led by investment giant BlackRock, has catapulted Groq's valuation to an impressive $2.8
The group was first launched in 2016 by Associate Professor of Computer Science, Data Science and Mathematics Joan Bruna , and Associate Professor of Mathematics and Data Science and incoming CDS Interim Director Carlos Fernandez-Granda with the goal of advancing the mathematical and statistical foundations of data science.
There are various techniques of preference alignment, including proximal policy optimization (PPO), direct preference optimization (DPO), odds ratio policy optimization (ORPO), group relative policy optimization (GRPO), and other algorithms, that can be used in this process.
For example, see Face-to-Face Interaction with Pedagogical Agents, Twenty Years Later , a 2016 article that overviews the field and cites a lot of the relevant material. Natural language processing (NLP) , natural language understanding and dialogue management that processes the content of the student's speech and produces the next response.
Introduction In natural language processing, text categorization tasks are common (NLP). Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. Figure 11 Model Architecture The algorithms and models used for the first three classifiers are essentially the same.
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). This is less of a problem in NLP where unsupervised pre-training involves classification over thousands of word types.
See Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , REALM , kNN-LM and RETRO. This retrieval can happen using different algorithms. In the past, she had worked on several NLP-based services such as Comprehend Medical, a medical diagnosis system at Amazon Health AI and Machine Translation system at Meta AI.
2021) 2021 saw many exciting advances in machine learning (ML) and natural language processing (NLP). If CNNs are pre-trained the same way as transformer models, they achieve competitive performance on many NLP tasks [28]. Popularized by GPT-3 [32] , prompting has emerged as a viable alternative input format for NLP models.
ChatGPT released by OpenAI is a versatile Natural Language Processing (NLP) system that comprehends the conversation context to provide relevant responses. Question Answering has been an active research area in NLP for many years so there are several datasets that have been created for evaluating QA systems.
News CommonCrawl is a dataset released by CommonCrawl in 2016. News CommonCrawl SEC Filing Coverage 2016-2022 1993-2022 Size 25.8 billion words The authors go through a few extra preprocessing steps before the data is fed into a training algorithm. His research interests are in NLP, Generative AI, and LLM Agents.
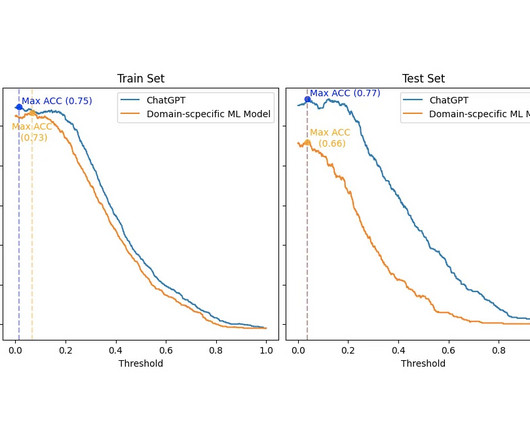
SA is a very widespread Natural Language Processing (NLP). Hence, whether general domain ML models can be as capable as domain-specific models is still an open research question in NLP. Other articles in my line of research (NLP, RL) Lima Paiva, F. It has several applications and thus can be used in several domains (e.g.,
Tay Microsoft unveiled Tay (short for “thinking about you”) in March 2016 on Twitter. Dallas’ Robocop In 2016, police in Dallas were tracking a man alleged to have fatally shot five men. According to Bloomberg , scientists even met in 2017 to discuss the apparently very real dangers behind AI. Is there any danger?
In our pipeline, we used Amazon Bedrock to develop a sentence shortening algorithm for automatic time scaling. Here’s the shortened sentence using the sentence shortening algorithm. She is also the recipient of the Best Paper Award at IEEE NetSoft 2016, IEEE ICC 2011, ONDM 2010, and IEEE GLOBECOM 2005. Cristian Torres is a Sr.
Large language models (LLMs) with billions of parameters are currently at the forefront of natural language processing (NLP). Although LLMs are capable of performing various NLP tasks, they are considered generalists and not specialists. epochs – Specifies at most how many epochs of the original dataset will be iterated.
It is based on GPT and uses machine learning algorithms to generate code suggestions as developers write. 2016) This paper introduced DCGANs, a type of generative model that uses convolutional neural networks to generate images with high fidelity. Microsoft Microsoft launched its Language Understanding Intelligent Service in 2016.
Visual question answering (VQA), an area that intersects the fields of Deep Learning, Natural Language Processing (NLP) and Computer Vision (CV) is garnering a lot of interest in research circles. NLP is a particularly crucial element of the multi-discipline research problem that is VQA. is an object detection task.
Recent Intersections Between Computer Vision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and Natural Language Processing (NLP). Finally, one can use a sentence similarity evaluation metric to evaluate the algorithm.
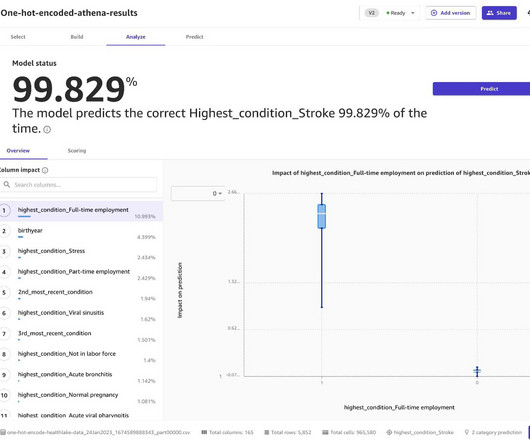
Use natural language processing (NLP) in Amazon HealthLake to extract non-sensitive data from unstructured blobs. We can see that Amazon HeathLake NLP interprets this as containing the condition “stroke” by querying for the condition record that has the same patient ID and displays “stroke.” mg/actuat / salmeterol 0.05
TF Lite is optimized to run various lightweight algorithms on various resource-constrained edge devices, such as smartphones, microcontrollers, and other chips. PyTorch Overview PyTorch was first introduced in 2016. The TensorFlow Lite implementation is specially designed for edge-based machine learning.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Conclusion: BERT as Trend-Setter in NLP and Deep Learning References I. BERT Architecture and Training III.1
On principle, all chatbots work by utilising some form of natural language processing (NLP). Our recently published paper, Transformer-Capsule Model for Intent Detection , demonstrated the results of our long-term research into better NLP. One of the first widely discussed chatbots was the one deployed by SkyScanner in 2016.
Numerous techniques, such as but not limited to rule-based systems, decision trees, genetic algorithms, artificial neural networks, and fuzzy logic systems, can be used to do this. In 2016, Google released an open-source software called AutoML. NLP is a type of AI that can understand human language and convert it into code.
Large language models (LLMs) with billions of parameters are currently at the forefront of natural language processing (NLP). Although LLMs are capable of performing various NLP tasks, they are considered generalists and not specialists. epochs – Specifies at most how many epochs of the original dataset will be iterated.
This would change in 1986 with the publication of “Parallel Distributed Processing” [ 6 ], which included a description of the backpropagation algorithm [ 7 ]. In retrospect, this algorithm seems obvious, and perhaps it was. We were definitely in a Kuhnian pre-paradigmatic period. It would not be the last time that happened.)
Quick bio Lewis Tunstall is a Machine Learning Engineer in the research team at Hugging Face and is the co-author of the bestseller “NLP with Transformers” book. My path to working in AI is somewhat unconventional and began when I was wrapping up a postdoc in theoretical particle physics around 2016.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. al, 2015) is a twist on the word2vec family of algorithms that lets you learn more interesting word vectors. That work is now due for an update. assert doc[3:6].text from_disk("./fashion_brands_patterns.jsonl")
Cross-lingual learning might be useful—but why should we care about applying NLP to other languages in the first place? The NLP Resource Hierarchy In current machine learning, the amount of available training data is the main factor that influences an algorithm's performance. 2016 ; Eger et al.,
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. It features consistent and easy-to-use interfaces to several models, which can extract features to power your NLP pipelines. apple2 = nlp("Apple sold fewer iPhones this quarter.") print(apple1[0].similarity(apple2[0]))
This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously. In summary, the Neuron SDK allows developers to easily parallelize ML algorithms, such as those commonly found in FSI.
Natural Language Processing (NLP) and knowledge representation and reasoning have empowered the machines to perform meaningful web searches. In addition, they possess 64 cores, specialized silicon for camera drivers, additional DSPs, and processors for AI algorithms. Stanford University and panel researchers P. Stone and R.
This advice should be most relevant to people studying machine learning (ML) and natural language processing (NLP) as that is what I did in my PhD. 2016 ), physics ( Cohen et al., Many projects with a large impact in ML and NLP such as AlphaGo or OpenAI Five have been developed by a team. 2014 ), neuroscience ( Wang et al.,
Large language models (LLMs) are yielding remarkable results for many NLP tasks, but training them is challenging due to the demand for a lot of GPU memory and extended training time. 2016 ), only the activations at the boundaries of each partition are saved and shared between workers during training.
By leveraging powerful Machine Learning algorithms, Generative AI models can create novel content such as images, text, audio, and even code. Founded in 2016, Hugging Face has quickly become one of the most popular platforms for developing and deploying NLP models, with over 10,000 models available in its model hub.
On the other hand, it has been so prominent in NLP in the last few years (Figure 1), that it’s no longer reasonable to ignore it in a blog about NLP. As always, this post will probably be too basic for most NLP researchers, but you’re welcome to distribute it to people who are new to the field! Not this post!
Recent Intersections Between Computer Vision and Natural Language Processing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and Natural Language Processing (NLP). Thanks for reading!
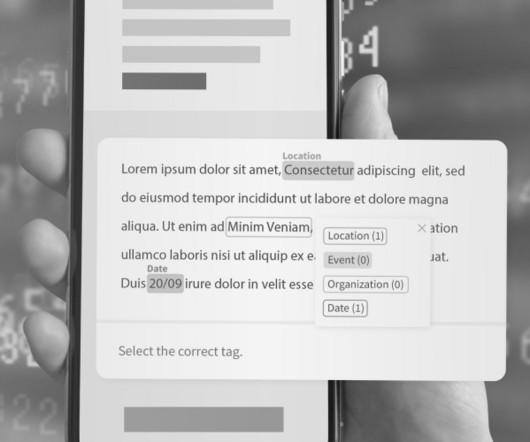
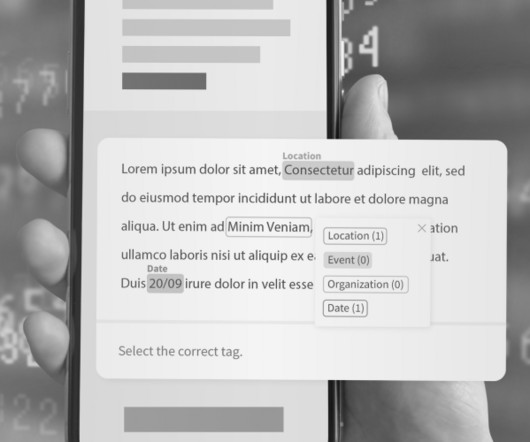
Named Entity Recognition (NER) is a natural language processing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. NER is an essential step in many NLP tasks, such as information extraction and text summarization.
Named Entity Recognition (NER) is a natural language processing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. NER is an essential step in many NLP tasks, such as information extraction and text summarization.
As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems. He retired from EPFL in December 2016.nnIn He focuses on developing scalable machine learning algorithms.
Looking back at the recent past, the 2016 US presidential election result makes us explore what influenced voters' decisions. AI watchdogs employ state-of-the-art technologies, particularly machine learning and deep learning algorithms, to combat the ever-increasing amount of election-related false information.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content