This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
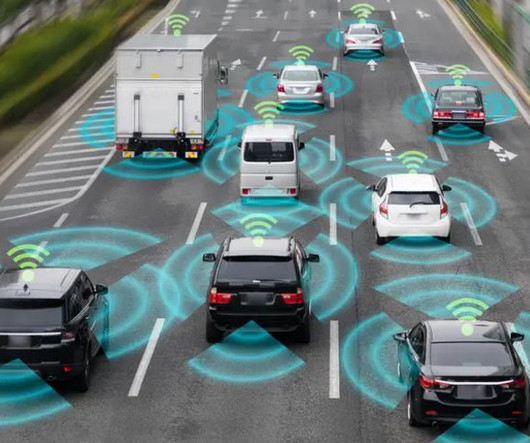
The company specializes in image processing and AI, with extensive expertise in research, implementation, and optimization of algorithms for embedded platforms and the in-car automotive industry. Those are just a few of the dozens of features enabled by computervision AI that would enhance the driving experience.
Computervision enables computers and systems to extract useful information from digital photos, videos, and other visual inputs and to conduct actions or offer recommendations in response to that information. Human vision has an advantage over computervision because it has been around longer.
Amir Hever is the CEO and co-founder of UVeye , a deep learning computervision startup that is setting the global standard for vehicle inspection with fast and accurate anomaly detection to identify issues or threats facing the automotive and security industries. UVeye is Hever’s third venture. We completely changed the game.
In 2016, as I was beginning my radiology residency, DeepMind's AlphaGo defeated world champion Go player Lee Sedol. AI algorithms can serve as a constant teacher and assistant, decreasing the cognitive load and leveling up all providers to provide world-class care. What role does AI play in improving patient outcomes?
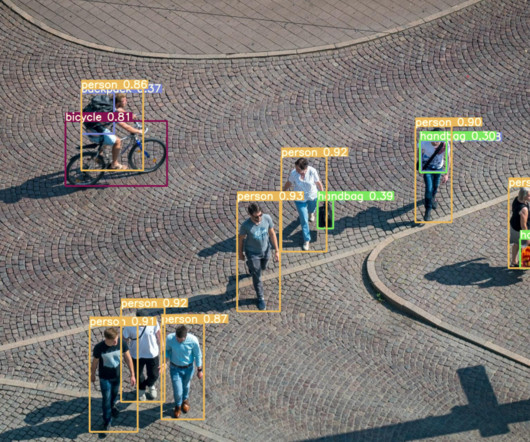
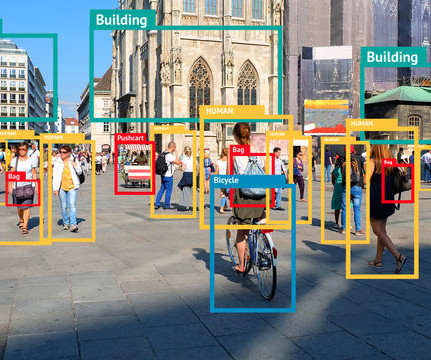
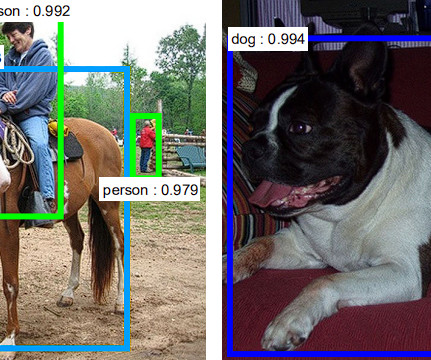
Ever since its launch, the YOLOv7 has been the hottest topic in the ComputerVision developer community, and for the right reasons. What makes YOLOv7 so efficient in performing computervision tasks? Object detection is a branch in computervision that identifies and locates objects in an image, or a video file.
Hedwig in Regensburg have developed an algorithm that provides an automatic and reliable method of detecting a certain heart defect in newborns. The rapid advance of technology and its impact on skilled and unskilled workers has hovered over the American landscape since the 2016 presidential election.
Computervision is a key component of self-driving cars. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision. The eyes of the automobile are computervision models.
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
ComputerVision technology has rapidly advanced in recent years and has become an important technology in various industries such as security , healthcare , agriculture , smart city , industrial manufacturing , automotive , and more. provides the leading end-to-end ComputerVision Platform Viso Suite. About us: Viso.ai
Object detection has seen rapid advancement in recent years thanks to deep learning algorithms like YOLO (You Only Look Once). Review of Previous YOLO Versions The YOLO (You Only Look Once) family of models has been at the forefront of fast object detection since the original version was published in 2016.
Photo by Maud CORREA on Unsplash ComputerVision Using ComputerVision Introduction Crack detection is crucial in monitoring the health of infrastructural buildings. Basically crack is a visible entity and so image-based crack detection algorithms can be adapted for inspection. 1030–1033, 2016. Adhikari, O.
In the following, we will cover the following: Pose Estimation in ComputerVision What is OpenPose? provides the leading ComputerVision Platform, Viso Suite. Global organizations use it to develop, deploy, and scale all computervision applications in one place. How does it work? How to Use OpenPose?
One of the most popular deep learning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al. Since then, the R-CNN algorithm has gone through numerous iterations, improving the algorithm with each new publication and outperforming traditional object detection algorithms (e.g.,
The YOLOv7 algorithm is making big waves in the computervision and machine learning communities. In this article, we will provide the basics of how YOLOv7 works and what makes it the best object detector algorithm available today. provides the only end-to-end computervision application platform, Viso Suite.
I received my masters in Civil/Environmental Engineering from Stanford University in 2016. We use three main different types of algorithms: image clustering, segmentation, and anomaly detection. PowerAI uses computervision and machine learning to automate a huge portion of the fault detection process.
Secure Redact uses advanced machine learning and computervision techniques to recognize and redact personally identifiable information (PII) in various image and video contexts, such as faces and license plates. Pimloc’s AI models accurately detect and redact PII even under challenging conditions.
billion tons of municipal solid waste was generated globally in 2016 with experts predicting a steep rise to 3.40 This is where computervision technology can help identify waste, separate it, and ensure its proper disposal. In this article, we will propose computervision as an effective tool for waste management.
And why is OpenCV so popular in the ComputerVision Industry? Hence, the world’s leading companies across industries use OpenCV to develop their computervision systems. What is ComputerVision? Leading organizations use it to build, deploy and scale real-world computervision applications.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
TF Lite is optimized to run various lightweight algorithms on various resource-constrained edge devices, such as smartphones, microcontrollers, and other chips. PyTorch Overview PyTorch was first introduced in 2016. The TensorFlow Lite implementation is specially designed for edge-based machine learning.
YOLO (You Only Look Once) is a state-of-the-art (SOTA) object-detection algorithm introduced as a research paper by J. About us : Viso Suite is an End-to-End ComputerVision Infrastructure that provides all the tools required to train, build, deploy, and manage computervision applications at scale. Redmon, et al.
After that, this framework has been officially opened to professional communities since 2016. It offers end-to-end functionalities for both artificial intelligence and computervision tasks. Use Cases Frequently Asked Questions (FAQs) About us: Viso Suite is the end-to-end computervision solution for enterprises.
Recent Intersections Between ComputerVision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). The illustration shows how a word is generated at every time step.
Since its inception in 2015, the YOLO (You Only Look Once) object-detection algorithm has been closely followed by tech enthusiasts, data scientists, ML engineers, and more, gaining a massive following due to its open-source nature and community contributions. YOLOv2 Released in 2016, it could detect 9000+ object categories.
Visual Question Answering (VQA) stands at the intersection of computervision and natural language processing, posing a unique and complex challenge for artificial intelligence. is a significant benchmark dataset in computervision and natural language processing. or Visual Question Answering version 2.0,
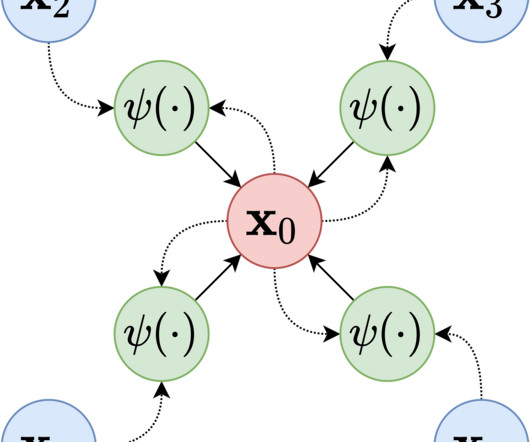
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al.,
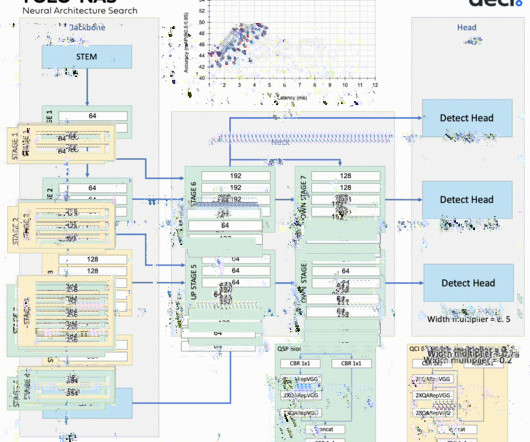
YOLOv8 is the newest model in the YOLO algorithm series – the most well-known family of object detection and classification models in the ComputerVision (CV) field. offers the world’s leading end-to-end no-code ComputerVision Platform Viso Suite. Get a demo. The family YOLO model is continuously evolving.
Object detection is one of the crucial tasks in ComputerVision (CV). Computervision researchers introduced YOLO architecture (You Only Look Once) as an object-detection algorithm in 2015. About Us: At Viso.ai, we power Viso Suite, the most complete end-to-end computervision platform.
Background and History of Neural Style Transfer NST is an example of an image styling problem that has been in development for decades, with image analogies and texture synthesis algorithms paving foundational work for NST. Fast Style Transfer (2016) While the previous model produced decent results, it was computationally expensive and slow.
The first version of YOLO was introduced in 2016 and changed how object detection was performed by treating object detection as a single regression problem. In the subfield of computervision, the competition for cutting-edge object detection is fierce. Ability to detect objects in images quickly and dependably.
YOLO (You Only Look Once) is a family of real-time object detection machine-learning algorithms. Object detection is a computervision task that uses neural networks to localize and classify objects in images. About us : Viso Suite is the complete computervision for enterprises.
It is based on GPT and uses machine learning algorithms to generate code suggestions as developers write. 2016) This paper introduced DCGANs, a type of generative model that uses convolutional neural networks to generate images with high fidelity. Microsoft Microsoft launched its Language Understanding Intelligent Service in 2016.
Deep learning and Convolutional Neural Networks (CNNs) have enabled speech understanding and computervision on our phones, cars, and homes. These offer larger power than the super-computers of 10 years ago. Low-cost 3D sensors, driven by gaming platforms, have enabled the development of 3D perception algorithms.
Visual question answering (VQA), an area that intersects the fields of Deep Learning, Natural Language Processing (NLP) and ComputerVision (CV) is garnering a lot of interest in research circles. A VQA system takes free-form, text-based questions about an input image and presents answers in a natural language format.
This would change in 1986 with the publication of “Parallel Distributed Processing” [ 6 ], which included a description of the backpropagation algorithm [ 7 ]. In retrospect, this algorithm seems obvious, and perhaps it was. We were definitely in a Kuhnian pre-paradigmatic period. It would not be the last time that happened.)
More recently, contrastive learning gained popularity in self-supervised representation learning in computervision and speech ( van den Oord, 2018 ; Hénaff et al., 2016 ; Webster et al., 8) Image Transformers The Vision Transformer ( Dosovitskiy et al., 2020 ; Wallace et al., 2020 ; Carlini et al.,
First released in 2016, it quickly gained traction due to its intuitive design and robust capabilities. In industry, it powers applications in computervision, natural language processing, and reinforcement learning. Further Read: Learn Top 10 Deep Learning Algorithms in Machine Learning.
Object detection is a fundamental task in computervision, and YOLOX plays a fair role in improving it. This was done by using a region proposal algorithm to generate potential bounding boxes (regions) in the image. YOLOX brings with it an anchor-free design, and decoupled head architecture to the YOLO family.
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. al, 2015) is a twist on the word2vec family of algorithms that lets you learn more interesting word vectors. That work is now due for an update. assert doc[3:6].text
These publications either present small improvements of BERT, such as ALBERT and RoBERTa, or apply the principles behind BERT in other application areas, such as BEiT and ClipBERT in computervision. In addition, it is known that Google has integrated BERT into its search algorithm to better understand search queries [17].
In computervision, supervised pre-trained models such as Vision Transformer [2] have been scaled up [3] and self-supervised pre-trained models have started to match their performance [4]. In mathematics, ML was shown to be able to guide the intuition of mathematicians in order to discover new connections and algorithms [77].
In the News Next DeepMind's Algorithm To Eclipse ChatGPT IN 2016, an AI program called AlphaGo from Google’s DeepMind AI lab made history by defeating a champion player of the board game Go. Powered by pluto.fi Try Pluto for free today] pluto.fi global investment arm, bringing the total capital raised to $165 million.
What intrigued me was the possibility that advancements in algorithms and compute power would lead to consumer-ready results. DeepAI began as a website in 2016, offering the first AI text to image generator. We have since discontinued our computervision product and shifted our focus entirely on AI Generation tools.
Recent Intersections Between ComputerVision and Natural Language Processing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). 2016) — “ LipNet: End-to-End Sentence-level Lipreading.” [17]
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content