This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Raw images are processed and utilized as input data for a 2-D convolutionalneuralnetwork (CNN) deep learning classifier, demonstrating an impressive 95% overall accuracy against new images. The glucose predictions done by CNN are compared with ISO 15197:2013/2015 gold standard norms.
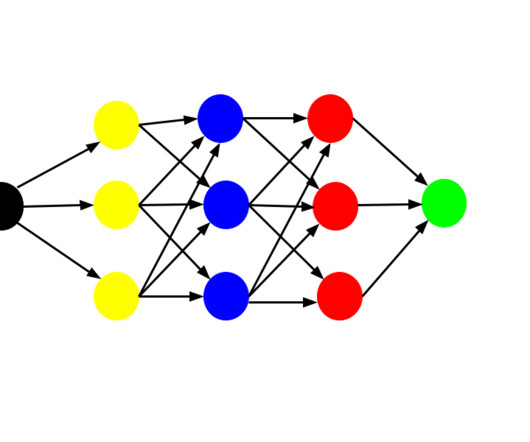
In this guide, we’ll talk about ConvolutionalNeuralNetworks, how to train a CNN, what applications CNNs can be used for, and best practices for using CNNs. What Are ConvolutionalNeuralNetworks CNN? CNNs learn geometric properties on different scales by applying convolutional filters to input data.
Source Anatomy of a CNN Let’s outline the architectural anatomy of a convolutionalneuralnetwork: Convolutional layers Activation layers Pooling layers Dense layers Andrew Jones of Data Science Infinity Convolutional Layer Instead of flattening the input at the input layer, you start by applying a filter.
You’ll typically find IoU and mAP used to evaluate the performance of HOG + Linear SVM detectors ( Dalal and Triggs, 2005 ), ConvolutionalNeuralNetwork methods, such as Faster R-CNN ( Girshick et al., 2015 ), SSD ( Fei-Fei et al., 2015 ; Redmon and Farhad, 2016 ), and others. In this work, Girshick et al.
Hence, rapid development in deep convolutionalneuralnetworks (CNN) and GPU’s enhanced computing power are the main drivers behind the great advancement of computer vision based object detection. Various two-stage detectors include region convolutionalneuralnetwork (RCNN), with evolutions Faster R-CNN or Mask R-CNN.
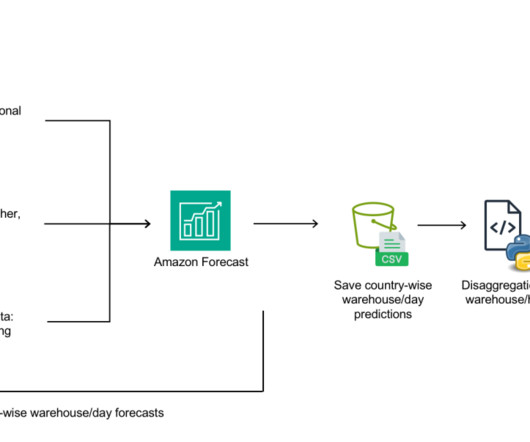
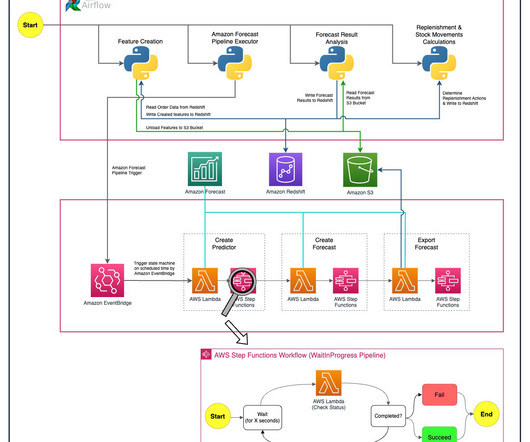
Getir was founded in 2015 and operates in Turkey, the UK, the Netherlands, Germany, and the United States. CNN-QR is a proprietary ML algorithm developed by Amazon for forecasting scalar (one-dimensional) time series using causal ConvolutionalNeuralNetworks (CNNs). Getir is the pioneer of ultrafast grocery delivery.
Like U-Net, TransUnet includes two main sections: Encoder (Vision Transformer): Vision Transformer encodes patches of feature maps that are generated by a convolutionneuralnetwork. Brox, U-Net: ConvolutionalNetworks for Biomedical Image Segmentation (2015) [2] A. References [1] O. Ronneberger, P.
Today’s boom in computer vision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutionalneuralnetworks (CNN). GoogLeNet – Going Deeper with Convolutions (2014) The Google team (Christian Szegedy, Wei Liu, et al.) Find the SURF paper here.
Getir was founded in 2015 and operates in Turkey, the UK, the Netherlands, Germany, France, Spain, Italy, Portugal, and the United States. We ultimately selected the Amazon CNN-QR (ConvolutionalNeuralNetwork – Quantile Regression) algorithm for our forecasting due to its high performance in the backtest process.
However, LLMs such as Anthropic’s Claude 3 Sonnet on Amazon Bedrock can also perform these tasks using zero-shot prompting, which refers to a prompting technique to give a task to the model without providing specific examples or training for that specific task.
The data at our disposal ranges from January 2015 to April 2023, totaling more than 153,000 transactions. The resulting HeteroData object for January 2015 is: It contains the following variables: exp_id: a list of node features per exporting node. Since each trade is logged twice, we focus on exports.
2015 – Microsoft researchers report that their ConvolutionalNeuralNetworks (CNNs) exceed human ability in pure ILSVRC tasks. Object Detection and Instance Segmentation – DeepMAD: Mathematical Architecture Design for Deep ConvolutionalNeuralNetwork, published by Xuan Shen et al.,
In 2015, researchers released the first YOLO model, which rapidly gained popularity for its object detection capabilities. YOLO in 2015 became the first significant model capable of object detection with a single pass of the network. For comparison, one of the best object detection models in 2015 (R-CNN Minus R) achieved a 53.5
It uses a Region Proposal Network (RPN) and ConvolutionalNeuralNetworks (CNNs) to identify and locate objects in complex real-world images. Developed by Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun in 2015, this model builds upon its predecessors, R-CNN and Fast R-CNN. Get a demo.
2015) give the following examples from the corpus: Text Hypothesis Label A man inspects the uniform of a figure in some East Asian country. 2015) Paragraph Vector 57.7 2015) SVM + Bigrams 57.6 2015) SVM + Unigrams 58.9 2015) CNN-word 59.7 2016) model and a convolutionalneuralnetwork (CNN).
Practitioners first trained a ConvolutionalNeuralNetwork (CNN) to perform image classification on ImageNet (i.e. Instance-Aware Semantic Segmentation via Multi-task Network Cascades.” December 14, 2015. April 14, 2015. January 29, 2015. pre-training). fine-tuning). December 10, 2016. June 17, 2019.
However, GoogLeNet demonstrated by using the inception module that depth and width in a neuralnetwork could be increased without exploding computations. GooLeNet – source Historical Context The concept of ConvolutionalNeuralNetworks ( CNNs ) isn’t new.
These new approaches generally; Feed the image into a ConvolutionalNeuralNetwork (CNN) for encoding, and run this encoding into a decoder Recurrent NeuralNetwork (RNN) to generate an output sentence. An example of such an approach is seen in the work of Karpathy and Fei-Fei (2015)[ 78 ].
In 2016 we trained a sense2vec model on the 2015 portion of the Reddit comments corpus, leading to a useful library and one of our most popular demos. Try the new interactive demo to explore similarities and compare them between 2015 and 2019 sense2vec (Trask et. Interestingly, “to ghost” wasn’t very common in 2015.
2015) The research paper by Leon A. Ecker, and Matthias Bethge, titled “A Neural Algorithm of Artistic Style,” made an important mark in the timeline of NST. An image can be represented by the relationships between the activations of features detected by a convolutionalneuralnetwork (CNN).
Nowadays, with the advent of deep learning and convolutionalneuralnetworks, this process can be automated, allowing the model to learn the most relevant features directly from the data. a convolutionalneuralnetwork), which then learns to map the features of each image to its correct label.
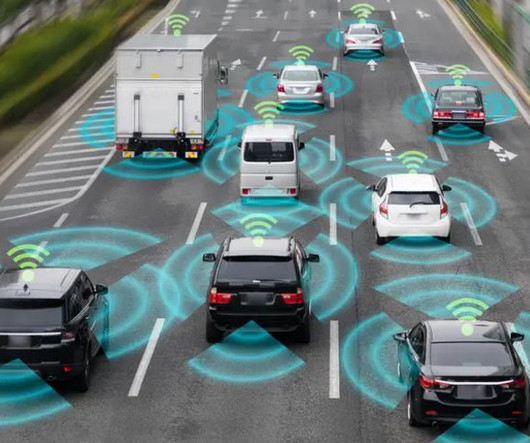
Autonomous Driving applying Semantic Segmentation in autonomous vehicles Semantic segmentation is now more accurate and efficient thanks to deep learning techniques that utilize neuralnetwork models. Levels of Automation in Vehicles – Source Here we present the development timeline of the autonomous vehicles.
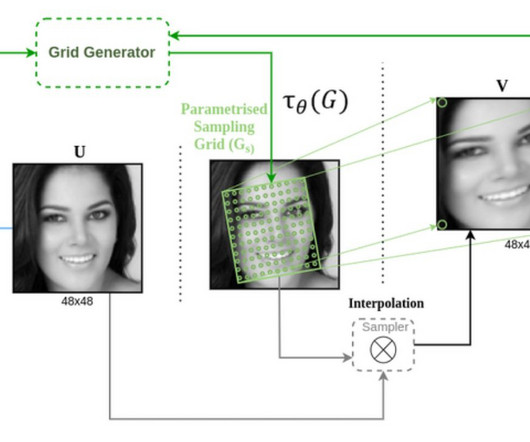
A Spatial Transformer Network (STN) is an effective method to achieve spatial invariance of a computer vision system. first proposed the concept in a 2015 paper by the same name. STNs are used to “teach” neuralnetworks how to perform spatial transformations on input data to improve spatial invariance.
A paper that exemplifies the Classifier Cage Match era is LeCun et al [ 109 ], which pits support vector machines (SVMs), k-nearest neighbor (KNN) classifiers, and convolutionneuralnetworks (CNNs) against each other to recognize images from the NORB database. 90,575 trainable parameters, placing it in the small-feature regime.
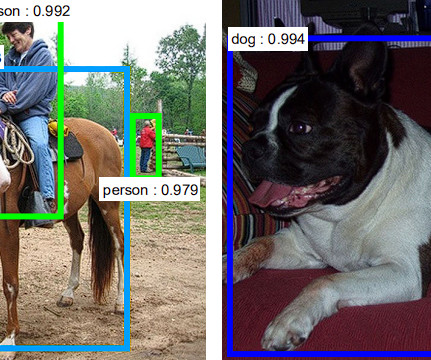
In the field of real-time object identification, YOLOv11 architecture is an advancement over its predecessor, the Region-based ConvolutionalNeuralNetwork (R-CNN). Using an entire image as input, this single-pass approach with a single neuralnetwork predicts bounding boxes and class probabilities. Redmon, et al.
Since its inception in 2015, the YOLO (You Only Look Once) object-detection algorithm has been closely followed by tech enthusiasts, data scientists, ML engineers, and more, gaining a massive following due to its open-source nature and community contributions. Divvala, R. Girshick, and A.
Viso Suite is the end-to-end, No-Code Computer Vision Platform for Businesses – Learn more What is YOLO You Only Look Once (YOLO) is an object-detection algorithm introduced in 2015 in a research paper by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. The essential mechanics of an object detection model – source.
Deep learning and ConvolutionalNeuralNetworks (CNNs) have enabled speech understanding and computer vision on our phones, cars, and homes. In 2015, the RIKEN-SRK Center for Human-Interactive Robot Research introduced Robear, an experimental nursing-care robot. Brooks et al.
Introduced in 2015 by Olaf Ronneberger’s team, U-Net aimed to create a high-performing network that could work with limited training data, addressing the challenge of scarce annotated images in the medical field. U-Net, a deep learning model specifically designed for biomedical image segmentation, exemplifies this.
Today’s boom in CV started with the implementation of deep learning models and convolutionalneuralnetworks (CNN). 2015) published a paper called EdgeFace or Efficient Face Recognition Model. Lightweight computer vision models allow the users to deploy them on mobile and edge devices. Ecabert, et al.
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks Radford et al. 2016) This paper introduced DCGANs, a type of generative model that uses convolutionalneuralnetworks to generate images with high fidelity. Attention Is All You Need Vaswani et al.
One trend that started with our work on Vision Transformers in 2020 is to use the Transformer architecture in computer vision models rather than convolutionalneuralnetworks. Top Computer Vision Computer vision continues to evolve and make rapid progress. Goodfellow, et al. Middle: From M. Lucic, et al. Right: From Imagen.
This module represents a common architectural pattern in convolutionalneuralnetworks, especially in U-Net-like architectures. Line 7 declares a new class, DualConv , that inherits from nn.Module , which is the base class for all neuralnetwork modules in PyTorch.
22] On a high level in the architecture, the frames extracted from a video sequence are processed in small sets within a ConvolutionalNeuralNetwork (CNN), [23] while an LSTM-variant runs on the CNN output sequentially to generate output characters. The Unreasonable Effectiveness of Recurrent NeuralNetworks.
In this particular case, there are a total of eight layers in the convolutionalneuralnetwork that contribute to the training process. This Meshnet model is inspired by multi-scale context aggregation by dilated convolutions, which is a technique that expands the input layer by introducing holes in it. link] [3] F.
link] Hermann et al (2015) created a dataset for testing reading comprehension by extracting summarised bullet points from CNN and Daily Mail. 2015), but using additional constraints and a different optimisation function. Let’s get started. NAACL 2016. The idea is similar to retrofitting by Faruqui et al. IJCNLP 2017.
From the development of sophisticated object detection algorithms to the rise of convolutionalneuralnetworks (CNNs) for image classification to innovations in facial recognition technology, applications of computer vision are transforming entire industries. Thus, positioning him as one of the top AI influencers in the world.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content