This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Established in 2015, Getir has positioned itself as the trailblazer in the sphere of ultrafast grocery delivery. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages. For this, we selected Amazon S3, known for its scalability and security.
It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary. The more similar the words and meanings captured by BERT, the higher the BERTScore. It uses neural networks like BERT to measure semantic similarity beyond just exact word or phrase matching.
2000–2015 The new millennium gave us low-rise jeans, trucker hats, and bigger advancements in language modeling, word embeddings, and Google Translate. 2015 and beyond — Word2vec, GloVe, and FASTTEXT Word2vec, GloVe, and FASTTEXT focused on word embeddings or word vectorization.
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
TensorFlow was developed by Google Brain for internal use at Google and open-sourced in 2015. Natural Language Question Answering : Use BERT to answer questions based on text passages. TensorFlow is an open-source software library for AI and machine learning with deep neural networks.
launched its meta framework on TensorFlow in 2015. Bert Labs Pvt. Ltd Bert Labs Pvt Ltd is one of the Top AI Startups in India, established in 2017 by Rohit Kochar. As a result, the AI start startup in India has generated a high source of revenue and a customer base over the last nine years. Effectively, Beethoven.ai
That work inspired researchers who created BERT and other large language models , making 2018 a watershed moment for natural language processing, a report on AI said at the end of that year. Google released BERT as open-source software , spawning a family of follow-ons and setting off a race to build ever larger, more powerful LLMs.
Abstraction level Neural Language Model – Source Google Neural Machine Translation (GNMT) In 2015, Google developed the revolutionary Google Neural Machine Translation (GNMT) for machine translation. The models, such as BERT and GPT-3 (improved version of GPT-1 and GPT-2), made NLP tasks better and polished.
The base model of BERT [ 103 ] had 12 (!) If you gave BERT a chunk of input text, it produced word vectors that encoded each word’s context, so that now it was finally possible to disambiguate “bank” (the financial institution) from “bank” (the edge of a river). BERT is just too good not to use.
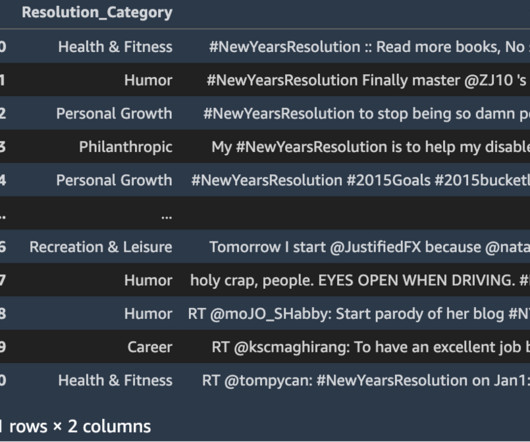
Large language models (LLMs) are transformer-based models trained on a large amount of unlabeled text with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. For this solution, we use the 2015 New Year’s Resolutions dataset to classify resolutions.
The update fixed outstanding bugs on the tracker, gave the docs a huge makeover, improved both speed and accuracy, made installation significantly easier and faster, and added some exciting new features, like ULMFit/BERT/ELMo-style language model pretraining. ✨ Mar 20: A few days later, we upgraded Prodigy to v1.8 to support spaCy v2.1.
Reading Comprehension assumes a gold paragraph is provided Standard approaches for reading comprehension build on pre-trained models such as BERT. Using BERT for reading comprehension involves fine-tuning it to predict a) whether a question is answerable and b) whether each token is the start and end of an answer span.
The student model could be a simple model like logistic regression or a foundation model like BERT. The concept of knowledge distillation for neural networks stretches back to a 2015 paper, and made a serious mark on data science well before the arrival of ChatGPT.
The student model could be a simple model like logistic regression or a foundation model like BERT. The concept of knowledge distillation for neural networks stretches back to a 2015 paper, and made a serious mark on data science well before the arrival of ChatGPT.
BERT shares this common domain across all of the NLP tasks. As you might know, in the NLP domain, BERT has been the starting foundation model. When you do BERT pre-training, you get awesome results on the NLP task. Then, there is no sharing of knowledge or resources. There are other examples from the past.
BERT shares this common domain across all of the NLP tasks. As you might know, in the NLP domain, BERT has been the starting foundation model. When you do BERT pre-training, you get awesome results on the NLP task. Then, there is no sharing of knowledge or resources. There are other examples from the past.
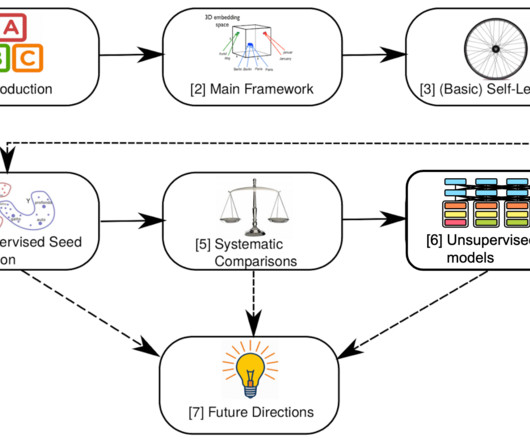
In particular, I cover unsupervised deep multilingual models such as multilingual BERT. 2015 , Artetxe et al., Joint models The most prominent example in this line of work is multilingual BERT (mBERT), a BERT-base model that was jointly trained on the corpora of 104 languages with a shared vocabulary of 110k subword tokens.
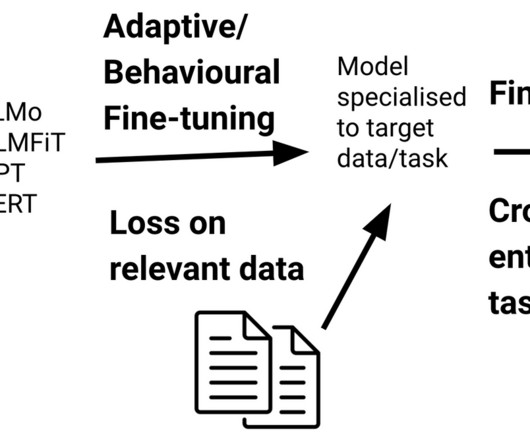
Dai and Le (2015) first showed the benefits of domain-adaptive fine-tuning. 2020) fine-tune BERT for quality evaluation with a range of sentence similarity signals. Text-to-text fine-tuning Another development in transfer learning is a move from masked language models such as BERT ( Devlin et al., Sellam et al. Mosbach et al.
This “making up” event is what we call a hallucination, a term popularized by Andrej Karpathy in 2015 in the context of RNNs and extensively used nowadays for large language models (LLMs). As you might guess, ChatGPT had taken the URL, which included the article’s title, and “made up” an abstract. What are LLM hallucinations?
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. RoBERTa: A Robustly Optimized BERT Pretraining Approach.
The voice remote was launched for Comcast in 2015. Are you using common large-language models like BERT or GPT-3, or full transformer models like T5? JN: Currently our model is an adaptation of the BERT model. And finally, also, AI/ML innovation and educational efforts. The next question we have is from Joe D.:
The voice remote was launched for Comcast in 2015. Are you using common large-language models like BERT or GPT-3, or full transformer models like T5? JN: Currently our model is an adaptation of the BERT model. And finally, also, AI/ML innovation and educational efforts. The next question we have is from Joe D.:
And when we think about these kinds of large self-supervised models—things in language modeling like BERT or GPT, or in computer vision like SimCLR and DINO—we effectively turn all of our unlabeled data into training data that we can use, which creates this massive dataset that would be awesome if we could distill down to some core-set.
And when we think about these kinds of large self-supervised models—things in language modeling like BERT or GPT, or in computer vision like SimCLR and DINO—we effectively turn all of our unlabeled data into training data that we can use, which creates this massive dataset that would be awesome if we could distill down to some core-set.
And when we think about these kinds of large self-supervised models—things in language modeling like BERT or GPT, or in computer vision like SimCLR and DINO—we effectively turn all of our unlabeled data into training data that we can use, which creates this massive dataset that would be awesome if we could distill down to some core-set.
There are many approaches to language modelling, we can for example ask the model to fill in the words in the middle of a sentence (as in the BERT model) or predict which words have been swapped for fake ones (as in the ELECTRA model).
Then, in 2015, Google released TensorFlow, a powerful tool that made advanced machine learning libraries available to the public. The momentum continued in 2017 with the introduction of transformer models like BERT and GPT, which revolutionized natural language processing. This was a game-changer.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content