This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this guide, we’ll talk about ConvolutionalNeuralNetworks, how to train a CNN, what applications CNNs can be used for, and best practices for using CNNs. What Are ConvolutionalNeuralNetworks CNN? CNNs learn geometric properties on different scales by applying convolutional filters to input data.
In the following, we will explore ConvolutionalNeuralNetworks (CNNs), a key element in computer vision and image processing. Whether you’re a beginner or an experienced practitioner, this guide will provide insights into the mechanics of artificial neuralnetworks and their applications. Howard et al.
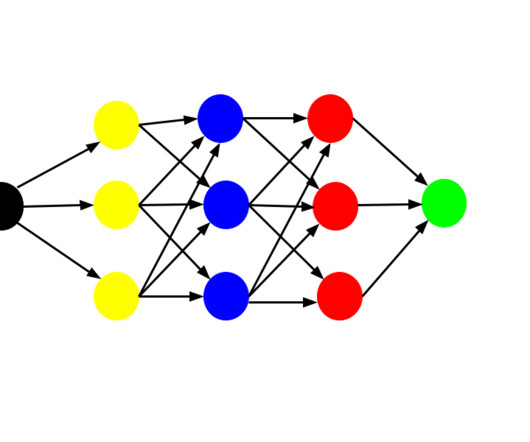
These models mimic the human brain’s neuralnetworks, making them highly effective for image recognition, natural language processing, and predictive analytics. Feedforward NeuralNetworks (FNNs) Feedforward NeuralNetworks (FNNs) are the simplest and most foundational architecture in Deep Learning.
Hence, deep neuralnetwork face recognition and visual Emotion AI analyze facial appearances in images and videos using computer vision technology to analyze an individual’s emotional status. With the rapid development of ConvolutionalNeuralNetworks (CNNs) , deep learning became the new method of choice for emotion analysis tasks.
Hence, rapid development in deep convolutionalneuralnetworks (CNN) and GPU’s enhanced computing power are the main drivers behind the great advancement of computer vision based object detection. Various two-stage detectors include region convolutionalneuralnetwork (RCNN), with evolutions Faster R-CNN or Mask R-CNN.
For example, image classification, image search engines (also known as content-based image retrieval, or CBIR), simultaneous localization and mapping (SLAM), and image segmentation, to name a few, have all been changed since the latest resurgence in neuralnetworks and deep learning. Object detection is no different. 2015 ; He et al.,
Over the years, we evolved that to solving NLP use cases by adopting NeuralNetwork-based algorithms loosely based on the structure and function of a human brain. The birth of Neuralnetworks was initiated with an approach akin to structuring solving problems with algorithms modeled after the human brain.
Deep learning refers to the use of neuralnetwork architectures, characterized by their multi-layer design (i.e. ConvolutionalNeuralNetwork for sentiment analysis A CNN model is a type of neural architecture that is based on learned matrices of numbers (filters) that slide (convolve) over the input data.
Today’s boom in computer vision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutionalneuralnetworks (CNN). The same CNN, with an extra sixth convolutional layer, was used to classify the entire ImageNet Fall 2011 release (15M images, 22K categories).
GoogLeNet, released in 2014, set a new benchmark in object classification and detection through its innovative approach (achieving a top-5 error rate of 6.7%, nearly half the error rate of the previous year’s winner ZFNet with 11.7%) in ImageNet Large Scale Visual Recognition Challenge (ILSVRC). In the original paper, it is set to 0.3.
Today, the most powerful image processing models are based on convolutionalneuralnetworks (CNNs). A popular library that uses neuralnetworks for real-time human pose estimation in 3D, even for multi-person use cases, is named OpenPose. High-Resolution Net (HRNet) is a neuralnetwork for human pose estimation.
Image captioning (circa 2014) Image captioning research has been around for a number of years, but the efficacy of techniques was limited, and they generally weren’t robust enough to handle the real world. However, in 2014 a number of high-profile AI labs began to release new approaches leveraging deep learning to improve performance.
This book effectively killed off interest in neuralnetworks at that time, and Rosenblatt, who died shortly thereafter in a boating accident, was unable to defend his ideas. (I Around this time a new graduate student, Geoffrey Hinton, decided that he would study the now discredited field of neuralnetworks.
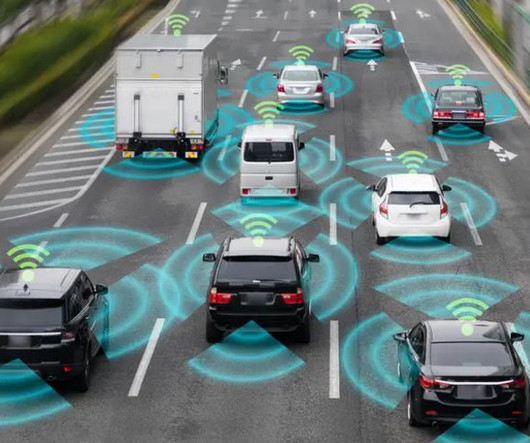
Autonomous Driving applying Semantic Segmentation in autonomous vehicles Semantic segmentation is now more accurate and efficient thanks to deep learning techniques that utilize neuralnetwork models. Levels of Automation in Vehicles – Source Here we present the development timeline of the autonomous vehicles.
However, when deep learning became popular in the 2010s, DeepPose was introduced by researchers at Facebook in 2014, this was an inspirational model that utilized ConvolutionalNeuralNetworks ( CNNs ) to effectively detect human poses directly from images. one for the left elbow, one for the right knee, etc.).
Suguard is an internal project we’ve been developing since 2014, which is when we founded DiabetesLab : our second company focused on creating advanced software that helps people manage an illness using AI. The technology uses convolutionalneuralnetworks to indicate likely issues on a patient’s retina, boasting accuracy levels of 92.3%
An image can be represented by the relationships between the activations of features detected by a convolutionalneuralnetwork (CNN). Previous methods directly fed the semantic layout as input to the deep neuralnetwork, which then the model processed through stacks of convolution, normalization, and nonlinearity layers.
One trend that started with our work on Vision Transformers in 2020 is to use the Transformer architecture in computer vision models rather than convolutionalneuralnetworks. The neuralnetwork perceives an image, and generates a sequence of tokens for each object, which correspond to bounding boxes and class labels.
Practitioners first trained a ConvolutionalNeuralNetwork (CNN) to perform image classification on ImageNet (i.e. OverFeat: Integrated Recognition, Localization and Detection Using ConvolutionalNetworks.” February 23, 2014. pre-training). fine-tuning). January 29, 2015.
State of Computer Vision Tasks in 2024 The field of computer vision today involves advanced AI algorithms and architectures, such as convolutionalneuralnetworks (CNNs) and vision transformers ( ViTs ), to process, analyze, and extract relevant patterns from visual data. Get a demo here.
Deep Learning Approaches ConvolutionalNeuralNetworks (CNNs) : The CNNs including AlexNet , VGGNet , and ResNet helped solve computer vision problems by learning the hierarchal features directly from the Pascal VOC data. These models were able to set benchmark accuracy on the Pascal VOC classification and detection challenges.
StyleGAN is GAN (Generative Adversarial Network), a Deep Learning (DL) model, that has been around for some time, developed by a team of researchers including Ian Goodfellow in 2014. These two networks compete against each other in a zero-sum game.
Images can be embedded using models such as convolutionalneuralnetworks (CNNs) , Examples of CNNs include VGG , and Inception. The Unreasonable Effectiveness Of NeuralNetwork Embeddings An embedding is a low-dimensional vector representation that captures relationships in higher dimensional input data.
The first VQA dataset was DAQUAR, released in 2014. VQA frameworks combine two Deep Learning architectures to deliver the final answer: ConvolutionalNeuralNetworks (CNN) for image recognition and Recurrent NeuralNetwork (RNN) (and its special variant Long Short Term Memory networks or LSTM) for NLP processing.
Next, we embed the images using an Inception-based [ 5 ] neuralnetwork. This solution is based on several ConvolutionalNeuralNetworks that work in a cascade fashion to locate the face with some landmarks in an image. 2022 [link] Going deeper with convolutions , Szegedy et al.
Unsupervised Recurrent NeuralNetwork Grammars Yoon Kim, Alexander Rush, Lei Yu, Adhiguna Kuncoro, Chris Dyer, Gábor Melis. link] Extending recurrent neuralnetwork grammars to the unsupervised setting, discovering constituency parses only from plain text. Harvard, Oxford, DeepMind. NAACL 2019. Turakhia, Andrew Y.
Similar to the advancements seen in Computer Vision, NLP as a field has seen a comparable influx and adoption of deep learning techniques, especially with the development of techniques such as Word Embeddings [6] and Recurrent NeuralNetworks (RNNs) [7]. Neuralnetwork-based approaches are typically characterised by heavy data demands.
The VGG model The VGG ( Visual Geometry Group ) model is a deep convolutionalneuralnetwork architecture for image recognition tasks. It was introduced in 2014 by a group of researchers (A. Zisserman and K. Simonyan) from the University of Oxford.
They present a simple classifier that achieves unexpectedly good results, and a neuralnetwork based on attention that beats all previous results by quite a margin. Neural activity by brain region, from Wehbe et al. Variational Neural Machine Translation Biao Zhang, Deyi Xiong, Jinsong Su, Hong Duan, Min Zhang.
NeuralNetworks are the workhorse of Deep Learning (cf. ConvolutionalNeuralNetworks have seen an increase in the past years, whereas the popularity of the traditional Recurrent NeuralNetwork (RNN) is dropping. White (2014). NeuralNetwork Methods in Natural Language Processing.
From the development of sophisticated object detection algorithms to the rise of convolutionalneuralnetworks (CNNs) for image classification to innovations in facial recognition technology, applications of computer vision are transforming entire industries. Thus, positioning him as one of the top AI influencers in the world.
These techniques involve training neuralnetworks on large datasets of images and videos, enabling them to generate synthetic media that closely mimics real-life appearances and movements. The advent of GANs in 2014 marked a significant milestone, allowing the creation of more sophisticated and hyperrealistic deepfakes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content