This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
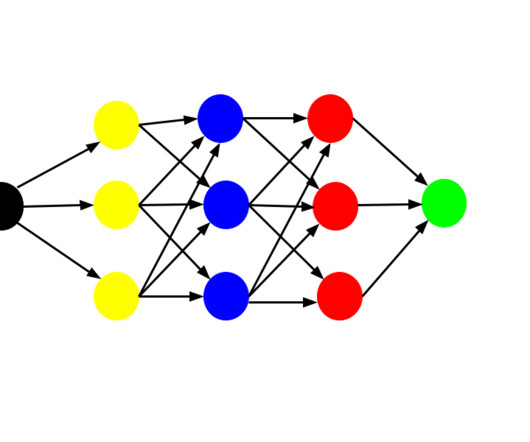
These models mimic the human brain’s neuralnetworks, making them highly effective for image recognition, natural language processing, and predictive analytics. Feedforward NeuralNetworks (FNNs) Feedforward NeuralNetworks (FNNs) are the simplest and most foundational architecture in Deep Learning.
I offer data science mentoring sessions and long-term career mentoring: Generative adversarial networks (GANs) have revolutionized image synthesis since their introduction in 2014.
AI emotion recognition is a very active current field of computervision research that involves facial emotion detection and the automatic assessment of sentiment from visual data and text analysis. provides the end-to-end computervision platform Viso Suite. About us: Viso.ai
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
Today’s boom in computervision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutional neuralnetworks (CNN). In this article, we dive into some of the most significant research papers that triggered the rapid development of computervision.
In the following, we will explore Convolutional NeuralNetworks (CNNs), a key element in computervision and image processing. Whether you’re a beginner or an experienced practitioner, this guide will provide insights into the mechanics of artificial neuralnetworks and their applications.
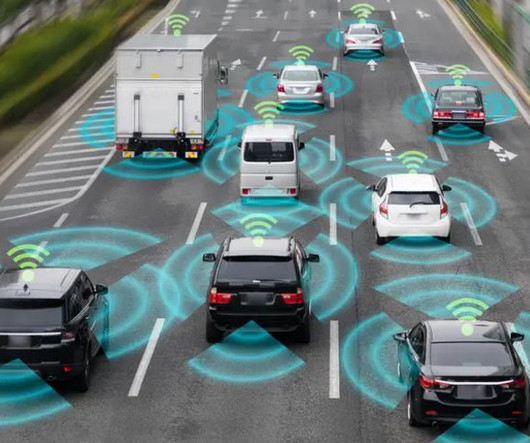
Computervision is a key component of self-driving cars. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision. The eyes of the automobile are computervision models.
In this guide, we’ll talk about Convolutional NeuralNetworks, how to train a CNN, what applications CNNs can be used for, and best practices for using CNNs. What Are Convolutional NeuralNetworks CNN? CNNs are artificial neuralnetworks built to handle data having a grid-like architecture, such as photos or movies.
Computervision (CV) is a rapidly evolving area in artificial intelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. Future trends and challenges Viso Suite is an end-to-end computervision platform.
For example, image classification, image search engines (also known as content-based image retrieval, or CBIR), simultaneous localization and mapping (SLAM), and image segmentation, to name a few, have all been changed since the latest resurgence in neuralnetworks and deep learning. Object detection is no different. 2015 ; He et al.,
This limits the amount of interaction when utilizing the generation pipeline as a creative tool, usually requiring tens to hundreds of expensive neuralnetwork evaluations. on MS-COCO 2014-30k using the same denoiser architecture as Stable Diffusion. DMD obtains a competitive FID of 11.49
Pose estimation is a fundamental task in computervision and artificial intelligence (AI) that involves detecting and tracking the position and orientation of human body parts in images or videos. provides the leading end-to-end ComputerVision Platform Viso Suite. Get a demo for your organization.
I will begin with a discussion of language, computervision, multi-modal models, and generative machine learning models. Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. Let’s get started!
Recent Intersections Between ComputerVision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP).
However, in the realm of unsupervised learning, generative models like Generative Adversarial Networks (GANs) have gained prominence for their ability to produce synthetic yet realistic images. Before the rise of GANs, there were other foundational neuralnetwork architectures for generative modeling. on Lines 6 and 7.
Pascal VOC is a renowned dataset and benchmark suite that has significantly contributed to the advancement of computervision research. It provides standardized image data sets for object class recognition and a common set of tools for accessing the data and evaluating the performance of computervision models.
This article will discuss the following: Neuromorphic Engineering and its core principles History and Development Algorithms Used How Neuromorphic Algorithms differ from Traditional Algorithms Real-world examples Applications and Use Cases About Us: At Viso.ai, we power Viso Suite, the most complete end-to-end computervision platform.
AlphaPose is a multi-person pose estimation model that uses computervision and deep learning techniques to detect and predict human poses from images and videos in real time. About us: Viso Suite provides full-scale features to rapidly build, deploy, and scale enterprise-grade computervision applications.
This book effectively killed off interest in neuralnetworks at that time, and Rosenblatt, who died shortly thereafter in a boating accident, was unable to defend his ideas. (I Around this time a new graduate student, Geoffrey Hinton, decided that he would study the now discredited field of neuralnetworks.
Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computervision and pattern recognition (pp. In Proceedings of the IEEE conference on computervision and pattern recognition (pp. NeuralNetworks, 64, 59–63. Intriguing properties of neuralnetworks.
An image can be represented by the relationships between the activations of features detected by a convolutional neuralnetwork (CNN). Previous methods directly fed the semantic layout as input to the deep neuralnetwork, which then the model processed through stacks of convolution, normalization, and nonlinearity layers.
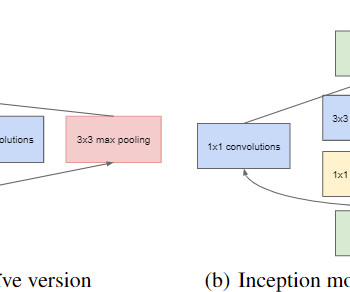
In this blog, we will try to deep dive into the concept of 1x1 convolution operation which appeared in the paper ‘Network in Network’ by Lin et al in (2013) and ‘Going Deeper with Convolutions’ by Szegedy et al (2014) that proposed the GoogLeNet architecture. 21 million ops) gets reduced by a factor of ~11.
The ImageNet dataset, featuring natural images, contains 14,197,122 annotated images organized in 1000 classes and is commonly used as a benchmark for many computervision models⁸. Practitioners first trained a Convolutional NeuralNetwork (CNN) to perform image classification on ImageNet (i.e. February 23, 2014.
StyleGAN is GAN (Generative Adversarial Network), a Deep Learning (DL) model, that has been around for some time, developed by a team of researchers including Ian Goodfellow in 2014. The synthesis network is composed of convolutional layers that progressively refine the image from a low resolution to the final high resolution.
It, of course, includes the work we have done manually in our previous two survey publications: A Year in ComputerVision and Multi-Modal Methods. Conducting exploratory search is difficult in standard IR systems as terminology might differ even in closely related fields (network analyses vs graph neuralnetworks).
Understanding the Basics of GANs Generative Adversarial Networks (GANs) are a class of Machine Learning models introduced by Ian Goodfellow in 2014. At their core, GANs consist of two neuralnetworks —a Generator and a Discriminator—that compete in a game-like scenario. How Generative Adversarial Networks (GANs) Work?
Visual question answering (VQA), an area that intersects the fields of Deep Learning, Natural Language Processing (NLP) and ComputerVision (CV) is garnering a lot of interest in research circles. The first VQA dataset was DAQUAR, released in 2014. This is why VQA problems are widely accepted as “AI-complete” or “AI-hard”.
Recent Intersections Between ComputerVision and Natural Language Processing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). Thanks for reading!
It is a challenging task in computervision, and it has many practical applications, such as video surveillance, human-computer interaction, sports analysis, and medical diagnosis. The VGG model The VGG ( Visual Geometry Group ) model is a deep convolutional neuralnetwork architecture for image recognition tasks.
In this post, we investigate of potential for the AWS Graviton3 processor to accelerate neuralnetwork training for ThirdAI’s unique CPU-based deep learning engine. He has won numerous paper awards, including Best Paper Awards at NIPS 2014 and MLSys 2022, as well as the Most Reproducible Paper Award at SIGMOD 2019.
Over the past decade, the field of computervision has experienced monumental artificial intelligence (AI) breakthroughs. This blog will introduce you to the computervision visionaries behind these achievements. Viso Suite is the end-to-End, No-Code ComputerVision Solution.
The Stanford AI Lab Founded in 1963, the Stanford AI Lab has made significant contributions to various domains, including natural language processing, computervision, and robotics. One of their notable recent projects is a new interpretability method for training neuralnetworks with sparse, discrete, and controllable hidden states.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















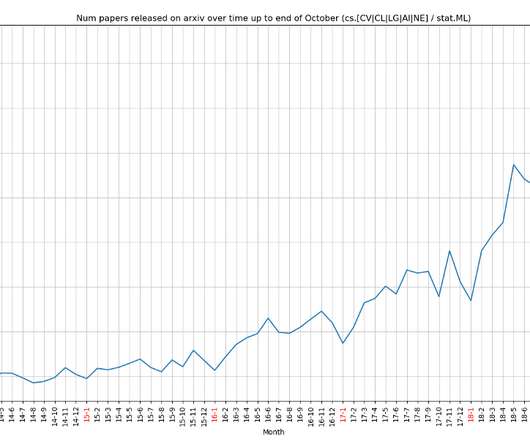












Let's personalize your content