This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
in Electrical & Computer Engineering from Ben-Gurion University and is an expert in automatic speech recognition. Before becoming Afekas President in 2014, he founded the Afeka Center for Language Processing and led the School of Electrical Engineering. He holds a Ph.D. Communication is also an important skill.
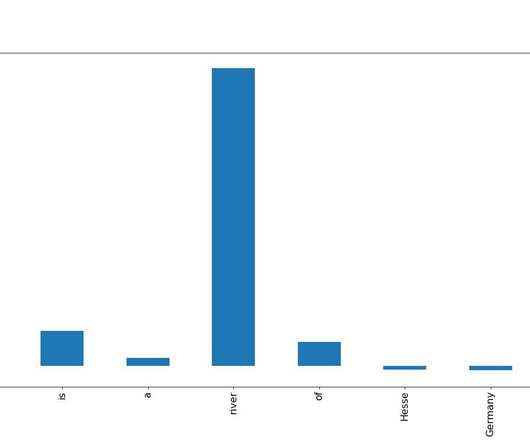
Model explainability refers to the process of relating the prediction of a machine learning (ML) model to the input feature values of an instance in humanly understandable terms. This field is often referred to as explainable artificial intelligence (XAI). In this post, we illustrate the use of Clarify for explaining NLP models.
Computervision (CV) is a rapidly evolving area in artificial intelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. Future trends and challenges Viso Suite is an end-to-end computervision platform.
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. yml file and how it relates to the rest of the huggingface directory?
ComputerVision for Cultural Heritage Preservation: Unlocking the Past with Advanced Imaging Technology Image Source: Technology Innovators Preserving our cultural legacy is critical because it allows us to remain in touch with our past, learn our roots, and appreciate humanity's rich history.
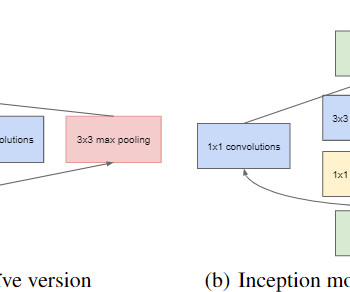
In this blog, we will try to deep dive into the concept of 1x1 convolution operation which appeared in the paper ‘Network in Network’ by Lin et al in (2013) and ‘Going Deeper with Convolutions’ by Szegedy et al (2014) that proposed the GoogLeNet architecture. References: [link] [link] [link] WRITER at MLearning.ai // Control AI Video ?
StyleGAN is GAN (Generative Adversarial Network), a Deep Learning (DL) model, that has been around for some time, developed by a team of researchers including Ian Goodfellow in 2014. Since the development of GANs, the world saw several models introduced every year that got nearer to generating real images.
The original Faster R-CNN paper used VGG (Simonyan and Zisserman, 2014) and ZF (Zeiler and Fergus, 2013) as the base networks. Do you think learning computervision and deep learning has to be time-consuming, overwhelming, and complicated? Or requires a degree in computer science? Join me in computervision mastery.
In recent years, the field of computervision has witnessed significant advancements in the area of image segmentation. We can also get the bounding boxes from smaller models, or in some cases, using standard computervision tools. The following images show the output for “silver car.”
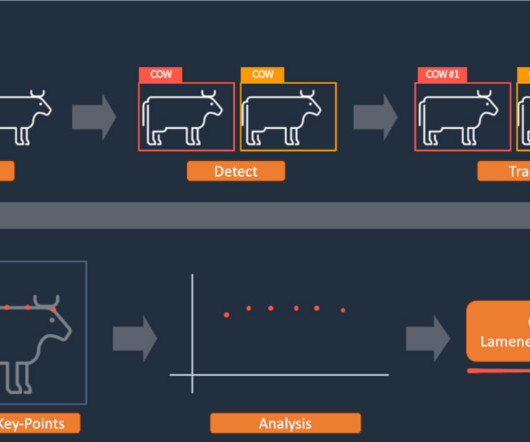
According to a 2014 study, the proportion of severely lame cows in China can be as high as 31 percent. Summary In this article, we briefly explained how the AWS Customer Solutions team innovates quickly based on the customer’s business. He specializes in ComputerVision (CV) and Visual-Language Model (VLM).
Course information: 80 total classes • 105+ hours of on-demand code walkthrough videos • Last updated: September 2023 ★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computervision and deep learning. Or requires a degree in computer science?
Recent Intersections Between ComputerVision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). These ideas also move in step with the explainability of results.
Explaining and harnessing adversarial examples. In Proceedings of the IEEE conference on computervision and pattern recognition (pp. In Proceedings of the IEEE conference on computervision and pattern recognition (pp. Explaining and harnessing adversarial examples. 2012; Otsu, 1979; Long et al.,
Recent Intersections Between ComputerVision and Natural Language Processing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). Thanks for reading!
In the following, we will explore Convolutional Neural Networks (CNNs), a key element in computervision and image processing. Viso Suite enables the use of neural networks for computervision with no code. Le propose architectures that balance accuracy and computational efficiency. Learn more and request a demo.
It is a challenging task in computervision, and it has many practical applications, such as video surveillance, human-computer interaction, sports analysis, and medical diagnosis. It was introduced in 2014 by a group of researchers (A. What is Human action recognition (HAR)? Zisserman and K.
Output from Neural Style Transfer – source Neural Style Transfer Explained Neural Style Transfer follows a simple process that involves: Three images, the image from which the style is copied, the content image, and a starting image that is just random noise. This allowed for user control over the semantics and style of the image.
GoogLeNet: is a highly optimized CNN architecture developed by researchers at Google in 2014. This helps avoid disappearing gradients in very deep networks, allowing ResNet to attain cutting-edge performance on a wide range of computervision applications. We pay our contributors, and we don’t sell ads.
Visual question answering (VQA), an area that intersects the fields of Deep Learning, Natural Language Processing (NLP) and ComputerVision (CV) is garnering a lot of interest in research circles. The first VQA dataset was DAQUAR, released in 2014. This is why VQA problems are widely accepted as “AI-complete” or “AI-hard”.
This blog aims to demystify GANs, explain their workings, and highlight real-world applications shaping our future. Understanding the Basics of GANs Generative Adversarial Networks (GANs) are a class of Machine Learning models introduced by Ian Goodfellow in 2014. Notably, the global Deep Learning market, valued at USD 69.9
In the following, we will explain what Deepfakes are, how to identify them and discuss the impact of AI-generated photos and videos. History and Rise of Deep-Fake Technology The concept emerged from academic research in the early 2010s, focusing on facial recognition and computervision. What are Deepfakes?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content