This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: DeepLearning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Introduction DeepLearning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. With a projected market growth from USD 6.4
Pose estimation is a fundamental task in computervision and artificial intelligence (AI) that involves detecting and tracking the position and orientation of human body parts in images or videos. provides the leading end-to-end ComputerVision Platform Viso Suite. Get a demo for your organization.
Apple prioritizes computervision , natural language processing , voice recognition, and healthcare to enhance its products. Google focuses on expanding AI in search, advertising, cloud, healthcare, and education, with a particular emphasis on deeplearning.
Founded in 2014, AI2 is the research institute created by the late philanthropist Paul G. Allen School of Computer Science & Engineering at University of Washington, Farhadi’s research impact has been globally recognized with several best paper awards at CVPR, NeruIPS, AAAI, NSF Career Award, and the Sloan Fellowship.
In computervision, there is an area called domain adaptation or style transfer which generates a new image by mixing up specific attributes from different images. However, generative models is not a new term and it has come a long way since Generative Adversarial Network (GAN) was published in 2014 [1].
Photo by Maud CORREA on Unsplash ComputerVision Using ComputerVision Introduction Crack detection is crucial in monitoring the health of infrastructural buildings. Deeplearning algorithms can be applied to solving many challenging problems in image classification. 180–194, 2014. A4014004, 2014.
AI emotion recognition is a very active current field of computervision research that involves facial emotion detection and the automatic assessment of sentiment from visual data and text analysis. provides the end-to-end computervision platform Viso Suite. About us: Viso.ai
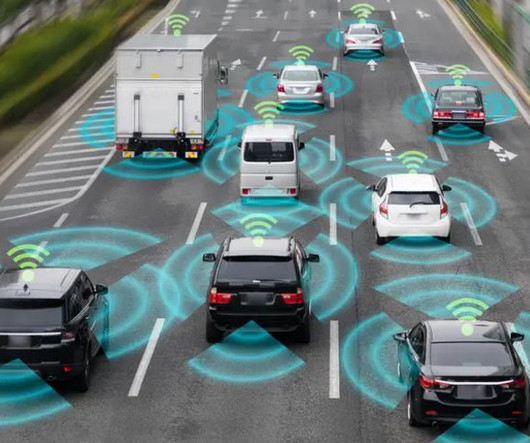
Computervision is a key component of self-driving cars. In this article, we’ll elaborate on how computervision enhances these cars. To accomplish this, they require two key components: machine learning and computervision. The eyes of the automobile are computervision models.
This article will provide an introduction to object detection and provide an overview of the state-of-the-art computervision object detection algorithms. Object detection is a key field in artificial intelligence, allowing computer systems to “see” their environments by detecting objects in visual images or videos.
Today’s boom in computervision (CV) started at the beginning of the 21 st century with the breakthrough of deeplearning models and convolutional neural networks (CNN). In this article, we dive into some of the most significant research papers that triggered the rapid development of computervision.
Computervision (CV) is a rapidly evolving area in artificial intelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. Future trends and challenges Viso Suite is an end-to-end computervision platform.
Home Table of Contents Faster R-CNNs Object Detection and DeepLearning Measuring Object Detector Performance From Where Do the Ground-Truth Examples Come? One of the most popular deeplearning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al.
ComputerVision for Cultural Heritage Preservation: Unlocking the Past with Advanced Imaging Technology Image Source: Technology Innovators Preserving our cultural legacy is critical because it allows us to remain in touch with our past, learn our roots, and appreciate humanity's rich history.
Summary: Generative Adversarial Network (GANs) in DeepLearning generate realistic synthetic data through a competitive framework between two networks: the Generator and the Discriminator. In answering the question, “What is a Generative Adversarial Network (GAN) in DeepLearning?”
Recent advances, however, have utilized deeplearning to analyze large climate datasets and uncover complex patterns. Previous D&A studies have varied in methodology, with approaches including PCA analysis, regression, and machine learning models to identify climate fingerprints and assess warming trends.
You can use state-of-the-art model architecturessuch as language models, computervision models, and morewithout having to build them from scratch. yml file from the AWS DeepLearning Containers GitHub repository, illustrating how the model synthesizes information across an entire repository. billion to a projected $574.78
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deeplearning has achieved remarkable success in supervised tasks, especially in image recognition. Do you think learningcomputervision and deeplearning has to be time-consuming, overwhelming, and complicated?
Visual question answering (VQA), an area that intersects the fields of DeepLearning, Natural Language Processing (NLP) and ComputerVision (CV) is garnering a lot of interest in research circles. For visual question answering in DeepLearning using NLP, public datasets play a crucial role.
Pascal VOC is a renowned dataset and benchmark suite that has significantly contributed to the advancement of computervision research. It provides standardized image data sets for object class recognition and a common set of tools for accessing the data and evaluating the performance of computervision models.
In recent years, the field of computervision has witnessed significant advancements in the area of image segmentation. We can also get the bounding boxes from smaller models, or in some cases, using standard computervision tools. His core interests include deeplearning and serverless technologies.
Automated algorithms for image segmentation have been developed based on various techniques, including clustering, thresholding, and machine learning (Arbeláez et al., Adversarial attacks pose a serious threat to the security of machine learning systems, as they can be used to manipulate the behavior of these systems in malicious ways.
AlphaPose is a multi-person pose estimation model that uses computervision and deeplearning techniques to detect and predict human poses from images and videos in real time. About us: Viso Suite provides full-scale features to rapidly build, deploy, and scale enterprise-grade computervision applications.
Recent Intersections Between ComputerVision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP).
The ImageNet dataset, featuring natural images, contains 14,197,122 annotated images organized in 1000 classes and is commonly used as a benchmark for many computervision models⁸. The common practice for developing deeplearning models for image-related tasks leveraged the “transfer learning” approach with ImageNet.
Apart from supporting explanations for tabular data, Clarify also supports explainability for both computervision (CV) and natural language processing (NLP) using the same SHAP algorithm. It is constructed by selecting 14 non-overlapping classes from DBpedia 2014.
Image analogies patch-based texture in-filling for artistic rendering – source The field of Neural style transfer took a completely new turn with DeepLearning. With deeplearning, the results were impressively good. Here is the journey of NST. Gatys et al. 2015) The research paper by Leon A.
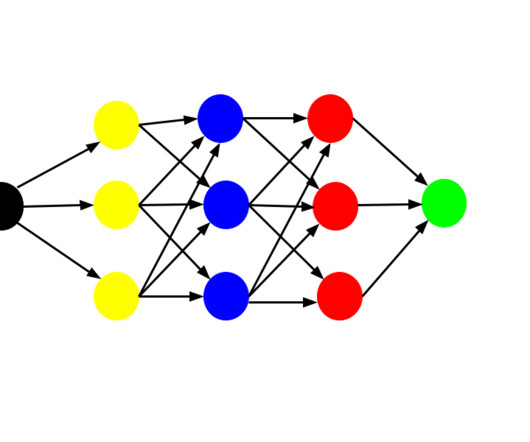
In the following, we will explore Convolutional Neural Networks (CNNs), a key element in computervision and image processing. Our products provide capabilities to train deep neural network models and use them in a no-code environment. Learn more and request a demo.
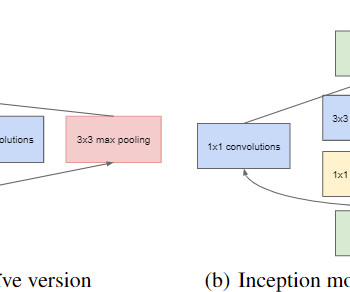
In this blog, we will try to deep dive into the concept of 1x1 convolution operation which appeared in the paper ‘Network in Network’ by Lin et al in (2013) and ‘Going Deeper with Convolutions’ by Szegedy et al (2014) that proposed the GoogLeNet architecture.
AlexNet significantly improved performance over previous approaches and helped popularize deeplearning and CNNs. GoogLeNet: is a highly optimized CNN architecture developed by researchers at Google in 2014. VGG-16: does the Visual Geometry Group develop an intense CNN architecture at the University of Oxford?
StyleGAN is GAN (Generative Adversarial Network), a DeepLearning (DL) model, that has been around for some time, developed by a team of researchers including Ian Goodfellow in 2014. Before StyleGAN, NVIDIA did come up with the predecessor- ProGAN, however, this model could not fine-control the features of images generated.
Built in 2014 along the Ankhor Canal, it’s fondly known as the “Snow Mosque” due to its pristine white marble construction. To learn how to use Keras Core with different backends, read our blog post on Keras Core. The keras and keras_cv imports are for using Keras and its computervision extensions, respectively.
Likewise, sound and text have no meaning to a computer. Things become more complex when we apply this information to DeepLearning (DL) models, where each data type presents unique challenges for capturing its inherent characteristics. 2014; Bojanowski et al., Sometimes, this can be easier and much faster. Mikolov, T.,
They were not wrong: the results they found about the limitations of perceptrons still apply even to the more sophisticated deep-learning networks of today. For example, Dean Pomerleau used them to create a system that learned to drive a car [ 12 ]. (I The graph below shows the trend of publications in machine learning.
Tasks such as “I’d like to book a one-way flight from New York to Paris for tomorrow” can be solved by the intention commitment + slot filing matching or deep reinforcement learning (DRL) model. Chitchatting, such as “I’m in a bad mood”, pulls up a method that marries the retrieval model with deeplearning (DL).
Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care. Improve the quality and time to market for deeplearning models in diagnostic medical imaging.
This article will discuss the following: Neuromorphic Engineering and its core principles History and Development Algorithms Used How Neuromorphic Algorithms differ from Traditional Algorithms Real-world examples Applications and Use Cases About Us: At Viso.ai, we power Viso Suite, the most complete end-to-end computervision platform.
This post is partially based on a keynote I gave at the DeepLearning Indaba 2022. The DeepLearning Indaba 2022 in Tunesia. In Proceedings of the IEEE International Conference on ComputerVision (Vol. A framework for self-supervised learning of speech representations. In Proceedings of ICLR 2021.
Recent Intersections Between ComputerVision and Natural Language Processing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between ComputerVision (CV) and Natural Language Processing (NLP). Thanks for reading!
It is a challenging task in computervision, and it has many practical applications, such as video surveillance, human-computer interaction, sports analysis, and medical diagnosis. The VGG model The VGG ( Visual Geometry Group ) model is a deep convolutional neural network architecture for image recognition tasks.
If the embedding vectors work as expected, computervision papers should be closer together in this space, and reinforcement learning (RL) papers close to other RL papers. Note : The “Charts and Additional Insights” page, one chart being “Top topics from 2014 onwards”. 2014, January). Simple, like with like.
Large-scale deeplearning has recently produced revolutionary advances in a vast array of fields. is a startup dedicated to the mission of democratizing artificial intelligence technologies through algorithmic and software innovations that fundamentally change the economics of deeplearning. Founded in 2021, ThirdAI Corp.
Over the past decade, the field of computervision has experienced monumental artificial intelligence (AI) breakthroughs. This blog will introduce you to the computervision visionaries behind these achievements. Viso Suite is the end-to-End, No-Code ComputerVision Solution.
The Stanford AI Lab Founded in 1963, the Stanford AI Lab has made significant contributions to various domains, including natural language processing, computervision, and robotics. Their research encompasses a broad spectrum of AI disciplines, including AI theory, reinforcement learning, and robotics. But that’s not all.
From generative modeling to automated product tagging, cloud computing, predictive analytics, and deeplearning, the speakers present a diverse range of expertise. Matei Zaharia is co-founder and Chief Technologist at Databricks as well as an Associate Professor of Computer Science at Stanford.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















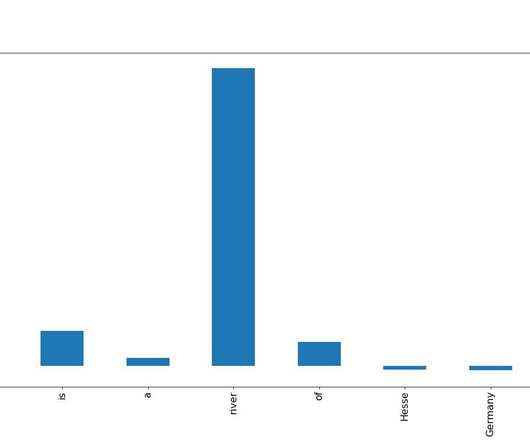





















Let's personalize your content