This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. Deeplearning refers to the use of neural network architectures, characterized by their multi-layer design (i.e. deep” architecture). These can be customized and trained. We’ll be mainly using the “.cats”
Deeplearning algorithms can be applied to solving many challenging problems in image classification. Therefore, Now we conquer this problem of detecting the cracks using image processing methods, deeplearning algorithms, and Computer Vision. 180–194, 2014. A4014004, 2014. Golparvar-Fard, and K.
It was in 2014 when ICML organized the first AutoML workshop that AutoML gained the attention of ML developers. Third, the NLP Preset is capable of combining tabular data with NLP or Natural Language Processing tools including pre-trained deeplearning models and specific feature extractors.
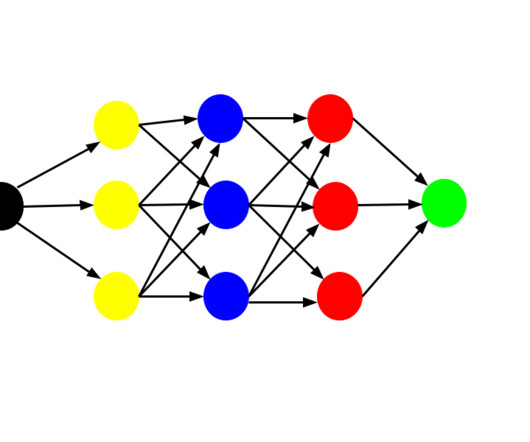
Machine learning (ML) is a subset of AI that provides computer systems the ability to automatically learn and improve from experience without being explicitly programmed. Deeplearning (DL) is a subset of machine learning that uses neural networks which have a structure similar to the human neural system.
Though once the industry standard, accuracy of these classical models had plateaued in recent years, opening the door for new approaches powered by advanced DeepLearning technology that’s also been behind the progress in other fields such as self-driving cars. The data does not need to be force-aligned.
The recent deeplearning algorithms provide robust person detection results. However, deeplearning models such as YOLO that are trained for person detection on a frontal view data set still provide good results when applied for overhead view person counting ( TPR of 95%, FPR up to 0.2% ).
Home Table of Contents Faster R-CNNs Object Detection and DeepLearning Measuring Object Detector Performance From Where Do the Ground-Truth Examples Come? One of the most popular deeplearning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al.
In this story, we talk about how to build a DeepLearning Object Detector from scratch using TensorFlow. The output layer is set to use Softmax Activation Function as usual in DeepLearning classifiers. That time, tensorflow/pytorch and the DeepLearning technology were not ready yet.
Object Detection with DeepLearning for traffic analytics with a video stream Vehicles can recognize the appearance of the cyclist, pedestrian, or car in front of them thanks to class-specific object detection. Levels of Automation in Vehicles – Source Here we present the development timeline of the autonomous vehicles.
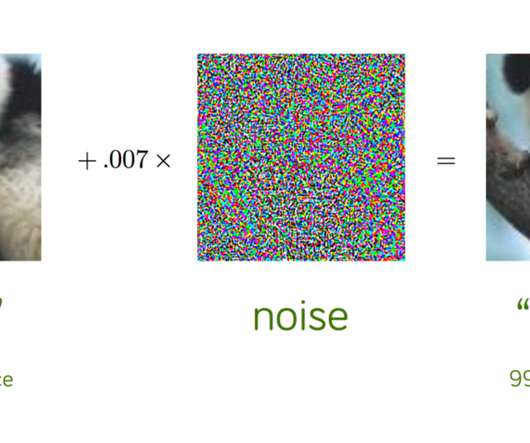
In 2014, a group of researchers at Google and NYU found that it was far too easy to fool ConvNets with an imperceivable, but carefully constructed nudge in the input. Up to this point, machine learning algorithms simply didn’t work well enough for anyone to be surprised when it failed to do the right thing. Kurakin et al, ICLR 2017.
AlexNet was created to categorize photos in the ImageNet dataset, which contains approximately 1 million images divided into 1,000 categories. AlexNet significantly improved performance over previous approaches and helped popularize deeplearning and CNNs. We pay our contributors, and we don’t sell ads.
The most common example is security analytics , where deeplearning models analyze CCTV footage to detect theft, traffic violations, or intrusions in real-time. Image Classification Image classification tasks involve CV models categorizing images into user-defined classes for various applications.
They were admitted to one of 335 units at 208 hospitals located throughout the US between 2014–2015. We used both numerical and categorical features and grouped all records of each patient to flatten them into a single-record time series. patientunitstayid. unitdischargeoffset. unitdischargestatus. Define the model.
Introduction In natural language processing, text categorization tasks are common (NLP). Uysal and Gunal, 2014). Deeplearning models with multilayer processing architecture are now outperforming shallow or standard classification models in terms of performance [5]. Ensemble deeplearning: A review.
Artificial Intelligence (AI) Integration: AI techniques, including machine learning and deeplearning, will be combined with computer vision to improve the protection and understanding of cultural assets. International Journal of Heritage in the Digital Era , 1 (1_suppl), 1–6. We pay our contributors, and we don't sell ads.
VGGNet , introduced by Simonyan and Zisserman in 2014, emphasized the importance of depth in CNN architectures through its 16-19 layer CNN network. Text Processing with CNNs In text processing, CNNs are remarkably efficient, particularly in tasks like sentiment analysis, topic categorization, and language translation.
This post is partially based on a keynote I gave at the DeepLearning Indaba 2022. The DeepLearning Indaba 2022 in Tunesia. 92] categorized the languages of the world into six different categories based on the amount of labeled and unlabeled data available in them. Joshi et al. [92] Collier, N., & Elliott, D.
Human Action Recognition (HAR) is a process of identifying and categorizing human actions from videos or image sequences. The VGG model The VGG ( Visual Geometry Group ) model is a deep convolutional neural network architecture for image recognition tasks. It was introduced in 2014 by a group of researchers (A. Zisserman and K.
Articles Quantization in deeplearning refers to the process of reducing the precision of the numbers used to represent the model's parameters and activations. Typically, deeplearning models use 32-bit floating-point numbers (float32) for computations. million per year in 2014 currency) in Shanghai.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content