This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RNNs and LSTMs came later in 2014. Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space. This facilitates various NLP tasks by providing meaningful word embeddings.
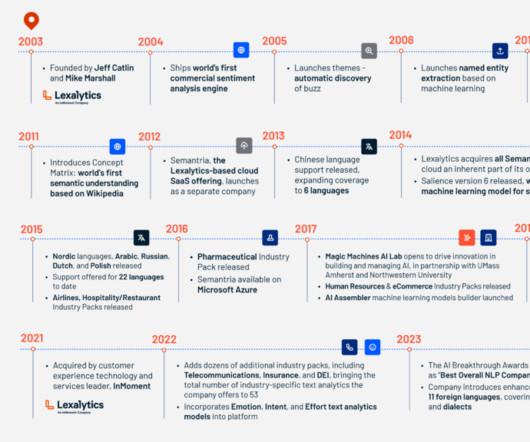
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
Introduction In natural language processing, text categorization tasks are common (NLP). Uysal and Gunal, 2014). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The architecture of BERT is represented in Figure 14.
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. In the span of little more than a year, transfer learning in the form of pretrained language models has become ubiquitous in NLP and has contributed to the state of the art on a wide range of tasks. However, transfer learning is not a recent phenomenon in NLP.
Summary: Deep Learning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Transformer Models Transformer models have revolutionised the field of Deep Learning, particularly in Natural Language Processing (NLP). Why are Transformer Models Important in NLP?
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! If a Natural Language Processing (NLP) system does not have that context, we’d expect it not to get the joke. I’ll be making use of the powerful SpaCy library which makes swapping architectures in NLP pipelines a breeze.
Word embeddings are considered as a type of representation used in natural language processing (NLP) to capture the meaning of words in a numerical form. Word embeddings are used in natural language processing (NLP) as a technique to represent words in a numerical format.
But if you’re working on the same sort of Natural Language Processing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them? In 2014 I started working on spaCy , and here’s an excerpt of how I explained the motivation for the library: Computers don’t understand text.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. Evaluations on CoNLL 2014 and JFLEG show a considerable improvement over previous best results of neural models, making this work comparable to state-of-the art on error correction. NAACL 2019.
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. What are Vector Embeddings? Pinecone Used a picture of phrase vector to explain vector embedding. All we need is the vectors for the words.
Fast-forward a couple of decades: I was (and still am) working at Lexalytics, a text-analytics company that has a comprehensive NLP stack developed over many years. The base model of BERT [ 103 ] had 12 (!) As with ULMFiT and ELMo, these contextual word vectors could be incorporated into any NLP application.
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. At the same time, a wave of NLP startups has started to put this technology to practical use. Data is based on: ml_nlp_paper_data by Marek Rei.
GANs, introduced in 2014 paved the way for GenAI with models like Pix2pix and DiscoGAN. NLP skills have long been essential for dealing with textual data. Tokenization & Transformers These are specific techniques in NLP and popularized by LLMs. Tokenization involves converting text into a format understandable by models.
2020) fine-tune BERT for quality evaluation with a range of sentence similarity signals. 2014 ) fine-tunes only the last layer of the model. There is increasing evidence that large pre-trained language models learn representations that compress NLP tasks well ( Li et al., Sellam et al. Aghajanyan et al. 2020 ; Guo et al.,
Weight decay has been applied to transformer-based NLP models since the beginning. The 2017 DeepMind study on Population-Based Training (PBT) showcased its potential for LLMs by fine-tuning the f irst transformer model on the WMT 2014 English-German machine translation benchmark. validation loss).
We took the opportunity to review major research trends in the animated NLP space and formulate some implications from the business perspective. The article is backed by a statistical and – guess what – NLP-based analysis of ACL papers from the last 20 years. But what is the substance behind the buzz?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content