

Why BERT is Not GPT
Towards AI
JUNE 12, 2024
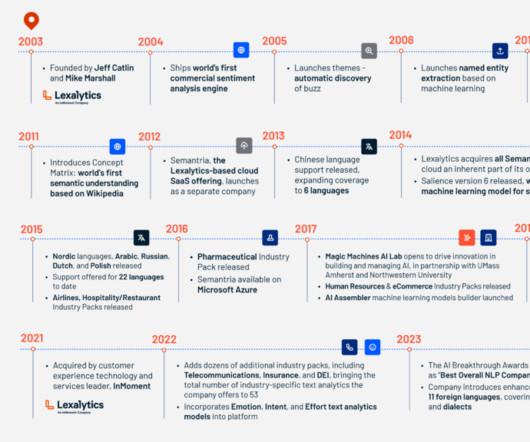
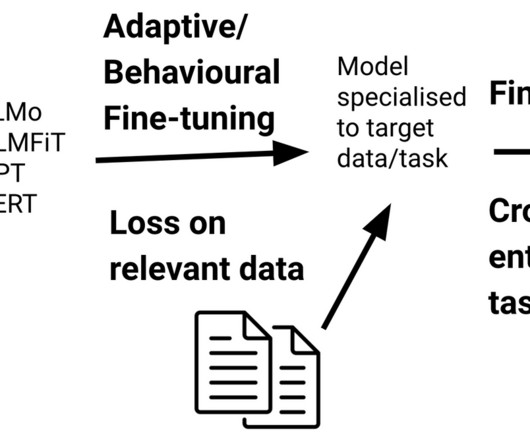
It all started with Word2Vec and N-Grams in 2013 as the most recent in language modelling. RNNs and LSTMs came later in 2014. Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space.

















Let's personalize your content