This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It all started with Word2Vec and N-Grams in 2013 as the most recent in language modelling. RNNs and LSTMs came later in 2014. Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in naturallanguageprocessing (NLP) where words are represented as vectors in a continuous vector space.
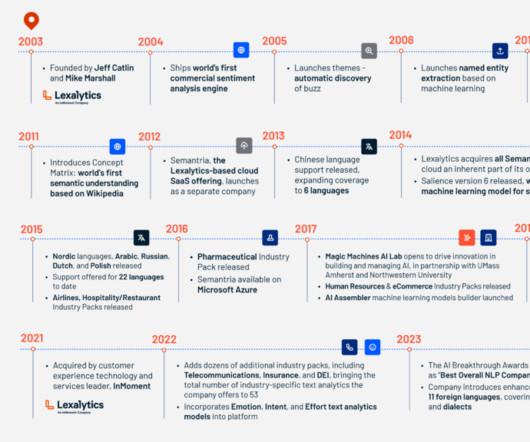
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.
These models mimic the human brain’s neural networks, making them highly effective for image recognition, naturallanguageprocessing, and predictive analytics. Transformer Models Transformer models have revolutionised the field of Deep Learning, particularly in NaturalLanguageProcessing (NLP).
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (NaturalLanguageProcessing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. Evolution of NLP Models To understand the full impact of the above evolutionary process.
Introduction In naturallanguageprocessing, text categorization tasks are common (NLP). Uysal and Gunal, 2014). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The architecture of BERT is represented in Figure 14.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! If a NaturalLanguageProcessing (NLP) system does not have that context, we’d expect it not to get the joke. Since 2014, he has been working in data science for government, academia, and the private sector. It’s all about context!
Later approaches then scaled these representations to sentences and documents ( Le and Mikolov, 2014 ; Conneau et al., LM pretraining Many successful pretraining approaches are based on variants of language modelling (LM). Multilingual BERT in particular has been the subject of much recent attention ( Pires et al.,
This is the sort of representation that is useful for naturallanguageprocessing. ELMo would also be the first of the Muppet-themed language models that would come to include ERNIE [ 120 ], Grover [ 121 ]….and The base model of BERT [ 103 ] had 12 (!) layers of bidirectional Transformers.
A lot of people are building truly new things with Large Language Models (LLMs), like wild interactive fiction experiences that weren’t possible before. But if you’re working on the same sort of NaturalLanguageProcessing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them?
Models that allow interaction via naturallanguage have become ubiquitious. Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. Transfer learning in naturallanguageprocessing.
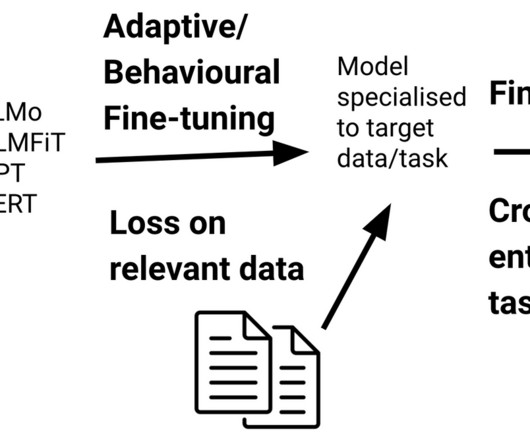
Fine-tuning a pre-trained language model (LM) has become the de facto standard for doing transfer learning in naturallanguageprocessing. 2018 ) while pre-trained language models are favoured over models trained on translation ( McCann et al., 2018 ), naturallanguage inference ( Conneau et al.,
Word embeddings are considered as a type of representation used in naturallanguageprocessing (NLP) to capture the meaning of words in a numerical form. Word embeddings are used in naturallanguageprocessing (NLP) as a technique to represent words in a numerical format. setInputCol('text').setOutputCol('document')
GANs, introduced in 2014 paved the way for GenAI with models like Pix2pix and DiscoGAN. Data Analysis Data analysis is often overlooked, but it’s still an essential skill for interpreting results from AI models and for the iterative process of improving prompt responses.
Below you will find short summaries of a number of different research papers published in the areas of Machine Learning and NaturalLanguageProcessing in the past couple of years (2017-2019). link] A bidirectional transformer architecture for pre-training language representations. NAACL 2019.
Large models like GPT-3 (175B parameters) or BERT-Large (340M parameters) can be reduced by 75% or more. Running BERT models on smartphones for on-device naturallanguageprocessing requires much less energy due to resource constrained in smartphones than server deployments.
Especially pre-trained word embeddings such as Word2Vec, FastText and BERT allow NLP developers to jump to the next level. On the other hand, a new and pretty disruptive mechanism for sequential processing – attention – has been introduced in the sequence-to-sequence (seq2seq) model by Sutskever et al. White (2014). Hazarika, S.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content