This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RNNs and LSTMs came later in 2014. Both BERT and GPT are based on the Transformer architecture. It all started with Word2Vec and N-Grams in 2013 as the most recent in language modelling. These were followed by the breakthrough of the Attention Mechanism. This piece compares and contrasts between the two models.
of nodes with text-features MAG 484,511,504 7,520,311,838 4/4 28,679,392 1,313,781,772 240,955,156 We benchmark two main LM-GNN methods in GraphStorm: pre-trained BERT+GNN, a baseline method that is widely adopted, and fine-tuned BERT+GNN, introduced by GraphStorm developers in 2022. Dataset Num. of nodes Num. of edges Num.
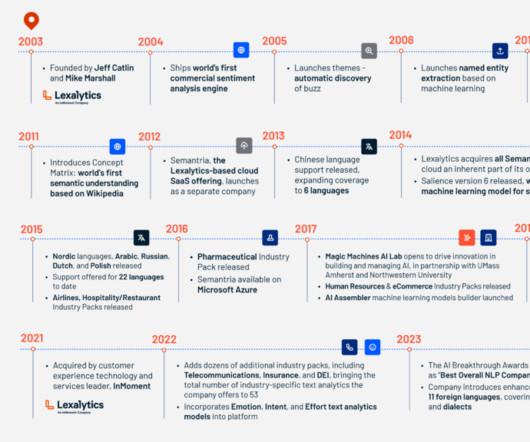
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.
Uysal and Gunal, 2014). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The fourth model which is also used for multi-class classification is built using the famous BERT architecture. The architecture of BERT is represented in Figure 14.
Transformers are the foundation of many state-of-the-art architectures, such as BERT and GPT. Introduced by Ian Goodfellow in 2014, GANs are designed to generate realistic data, such as images, videos, and audio, that mimic real-world datasets. Their unique architecture has revolutionised creative applications in AI.
2014) Significant people : Geoffrey Hinton Yoshua Bengio Ilya Sutskever 5. Popular Examples include the Bidirectional Encoder Representations from Transformers (BERT) model and the Generative Pre-trained Transformer 3 (GPT-3) model. In recent years transformer models have emerged as the SOTA models for NLP.
But in 2013 and 2014, it remained stuck at 83% , and while in the ten years since, it has reached 95% , it had become clear that the easy money that came from acquiring more users was ending. It was certainly obvious to outsiders how disruptive BERT could be to Google Search. The market was maturing. Will History Repeat Itself?
Later approaches then scaled these representations to sentences and documents ( Le and Mikolov, 2014 ; Conneau et al., In contrast, current models like BERT-Large and GPT-2 consist of 24 Transformer blocks and recent models are even deeper. Multilingual BERT in particular has been the subject of much recent attention ( Pires et al.,
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. What are Vector Embeddings? Pinecone Used a picture of phrase vector to explain vector embedding. All we need is the vectors for the words.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! Since 2014, he has been working in data science for government, academia, and the private sector. Editor’s note: Benjamin Batorsky, PhD is a speaker for ODSC East 2023. In English, “well” can refer to a state of being and a device for retrieving water.
The base model of BERT [ 103 ] had 12 (!) If you gave BERT a chunk of input text, it produced word vectors that encoded each word’s context, so that now it was finally possible to disambiguate “bank” (the financial institution) from “bank” (the edge of a river). BERT is just too good not to use.
In 2014 I started working on spaCy , and here’s an excerpt of how I explained the motivation for the library: Computers don’t understand text. In their experiments, OpenAI prompted GPT3 with 32 examples of each task, and found that they were able to achieve similar accuracy to the BERT baselines. The results in Section 3.7,
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. Evaluations on CoNLL 2014 and JFLEG show a considerable improvement over previous best results of neural models, making this work comparable to state-of-the art on error correction. NAACL 2019.
2020) fine-tune BERT for quality evaluation with a range of sentence similarity signals. 2014 ) fine-tunes only the last layer of the model. Text-to-text fine-tuning Another development in transfer learning is a move from masked language models such as BERT ( Devlin et al., Sellam et al. Aghajanyan et al. Mosbach et al.
GANs, introduced in 2014 paved the way for GenAI with models like Pix2pix and DiscoGAN. Prompt Engineering Platforms LLM Platforms: ChatGpt, GPT-4, LLama 2, Stable Diffusion, and BERT ChatGPT OpenAI’s ChatGPT was one of the most popular apps in history, so it’s no surprise that the suite of API models including GPT-3.5
Please check our similar post about “Embeddings with Transformers” for BERT family embeddings. It is developed as an open-source project at Stanford and was launched in 2014. In this post, you will learn how to use word embeddings of Spark NLP. Spark NLP has multiple approaches for generating word embeddings. alias("cols")).select(F.expr("cols['0']").alias("token"),
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. RoBERTa: A Robustly Optimized BERT Pretraining Approach.
In the seminal 2018 paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , the authors state that they trained the model using Adam with [a] learning rate of 1e-4, =0.9, =0.999, L2 weight decay of 0.01, learning rate warm up over the first 10,000 steps, and linear decay of the learning rate.”
Large models like GPT-3 (175B parameters) or BERT-Large (340M parameters) can be reduced by 75% or more. Running BERT models on smartphones for on-device natural language processing requires much less energy due to resource constrained in smartphones than server deployments. million per year in 2014 currency) in Shanghai.
Especially pre-trained word embeddings such as Word2Vec, FastText and BERT allow NLP developers to jump to the next level. White (2014). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Transfer learning is another approach to reusing models across different tasks. References E. Cambria and B.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content