This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
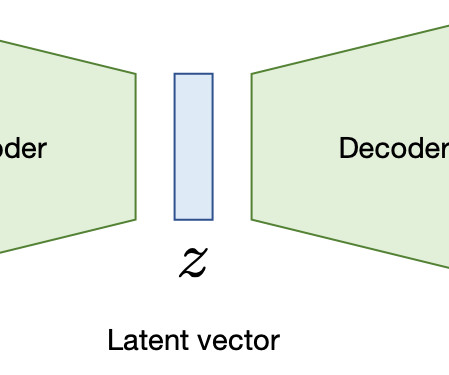
Uysal and Gunal, 2014). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution.
Charting the evolution of SOTA (State-of-the-art) techniques in NLP (Natural Language Processing) over the years, highlighting the key algorithms, influential figures, and groundbreaking papers that have shaped the field. NLP algorithms help computers understand, interpret, and generate natural language.
Why is it that Amazon, which has positioned itself as “the most customer-centric company on the planet,” now lards its search results with advertisements, placing them ahead of the customer-centric results chosen by the company’s organic search algorithms, which prioritize a combination of low price, high customer ratings, and other similar factors?
Use algorithm to determine closeness/similarity of points. A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. This is embedding/vector/vector embedding for this article. What are Vector Embeddings?
This would change in 1986 with the publication of “Parallel Distributed Processing” [ 6 ], which included a description of the backpropagation algorithm [ 7 ]. In retrospect, this algorithm seems obvious, and perhaps it was. We were definitely in a Kuhnian pre-paradigmatic period. It would not be the last time that happened.)
Word embeddings are generated using algorithms that are trained on large corpora of text data. These algorithms learn to assign each word in the corpus a unique vector representation that captures the word’s meaning based on its context in the text. Using Word2Vec annotator for generating word embeddings using the Word2Vec algorithm.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. Evaluations on CoNLL 2014 and JFLEG show a considerable improvement over previous best results of neural models, making this work comparable to state-of-the art on error correction. NAACL 2019.
GANs, introduced in 2014 paved the way for GenAI with models like Pix2pix and DiscoGAN. Prompt Engineering Platforms LLM Platforms: ChatGpt, GPT-4, LLama 2, Stable Diffusion, and BERT ChatGPT OpenAI’s ChatGPT was one of the most popular apps in history, so it’s no surprise that the suite of API models including GPT-3.5
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. RoBERTa: A Robustly Optimized BERT Pretraining Approach.
Large models like GPT-3 (175B parameters) or BERT-Large (340M parameters) can be reduced by 75% or more. Running BERT models on smartphones for on-device natural language processing requires much less energy due to resource constrained in smartphones than server deployments. million per year in 2014 currency) in Shanghai.
As the following chart shows, research activity has been flourishing in the past years: Figure 1: Paper quantity published at the ACL conference by years In the following, we summarize some core trends in terms of data strategies, algorithms, tasks as well as multilingual NLP. They not only need annotated data – they need Big Labeled Data.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content