This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. The introduction of word embeddings, most notably Word2Vec, was a pivotal moment in NLP. One-hot encoding is a prime example of this limitation.
In 2013, he co-founded Sequretek with Anand Naik and has played a key role in developing the company into a prominent provider of cybersecurity and cloud security solutions. When we founded the company in 2013, our mission was clear, to make cybersecurity simple and accessible for all, not just the few who could afford it.
Founded in 2013, The Information has built the biggest dedicated newsroom in tech journalism and count many of the world’s most powerful business and tech executives as subscribers. siliconangle.com Sponsor Make Smarter Business Decisions with The Information Looking for a competitive edge in the world of business?
The field of natural language processing (NLP) has grown rapidly in recent years, creating a pressing need for better datasets to train large language models (LLMs). Spanning 8 terabytes of compressed text dataroughly equivalent to 3 trillion wordsFineWeb 2 draws from 96 CommonCrawl snapshots collected between 2013 and April 2024.
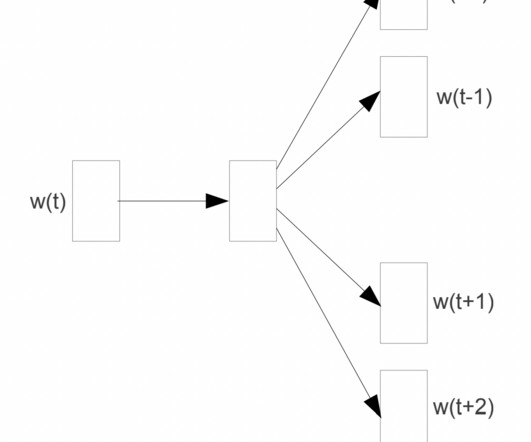
It all started with Word2Vec and N-Grams in 2013 as the most recent in language modelling. Word embedding is a technique in natural language processing (NLP) where words are represented as vectors in a continuous vector space. 2013 Word2Vec is a neural network model that uses n-grams by training on context windows of words.
I had a casual conversation with some software developers who had done some rudimentary experiments with audio and text (not transcription) in 2013. NLP and speech processing algorithms are part of our day-to-day, but we will investigate any creative ways to use AI to help journalists extract information from videos, audios and images.
In the last few years, if you google healthcare or clinical NLP, you would see that the search results are blanketed by a few names like John Snow Labs (JSL), Linguamatics (IQVIA), Oncoustics, BotMD, Inspirata. All of these companies were founded between 2013–2016 in various parts of the world. Originally published on Towards AI.
Along with Craig Thomson (research fellow), Anya Belz (PI) and many collaborators and partners, I am working on a project, ReproHum , which is looking at the replicability of human evaluations in NLP. These papers also were all published in ACL or TACL, which are among the best NLP venues. of Arvan et al 2022 ).
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. In the span of little more than a year, transfer learning in the form of pretrained language models has become ubiquitous in NLP and has contributed to the state of the art on a wide range of tasks. However, transfer learning is not a recent phenomenon in NLP.
By 2013, I began wondering if I could do something bigger. Randy and I both come from finance and algorithmic trading backgrounds, which led us to take the concept of matching requests with answers to build our own NLP for hyper-specific inquiries that would get asked at locations. By 25, I was running my own department.
MarketMuse, founded by Aki Balogh and Jeff Coyle in 2013, is a content marketing and keyword planner tool that utilizes artificial intelligence and machine learning. Conducts real-time research with NLP, semantic analysis, and the best SEO practices to write an entire article. MarketMuse Key Features: Competitive content analysis.
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. The data span a period of 18 years, including ~35 million reviews up to March 2013. But often, these methods fail on more complex tasks.
NLP research has undergone a paradigm shift over the last year. In contrast, NLP researchers today are faced with a constraint that is much harder to overcome: compute. A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models Li et al. Defining a New NLP Playground Saphra et al.
This post was first published in NLP News. NLP research has undergone a paradigm shift over the last year. In contrast, NLP researchers today are faced with a constraint that is much harder to overcome: compute. A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models Li et al.
The selection of areas and methods is heavily influenced by my own interests; the selected topics are biased towards representation and transfer learning and towards natural language processing (NLP). This is less of a problem in NLP where unsupervised pre-training involves classification over thousands of word types.
NLP A Comprehensive Guide to Word2Vec, Doc2Vec, and Top2Vec for Natural Language Processing In recent years, the field of natural language processing (NLP) has seen tremendous growth, and one of the most significant developments has been the advent of word embedding techniques. I hope you find this article to be helpful.
to uncontrolled environments (SFEW, FER-2013, etc.). Comparison of State-of-the-art methods for AI emotion analysis There is a common discrepancy in accuracy when testing in controlled environment databases compared to wild environment databases. For example , a model obtaining 98.9% Get a demo for your organization.
While numerous techniques have been explored, methods harnessing natural language processing (NLP) have demonstrated strong performance. Word2Vec, a widely-adopted NLP algorithm has proven to be an efficient and valuable tool that is now applied across multiple domains, including recommendation systems.
Narrowing the communications gap between humans and machines is one of SAS’s leading projects in their work with NLP. Plotly In the time since it was founded in 2013, Plotly has released a variety of products including Plotly.py, which, along with Plotly.r, became one of “the most downloaded interactive graphing libraries in the world.”
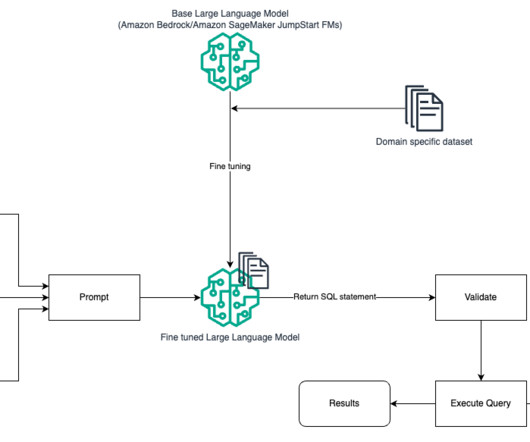
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. In entered the Big Data space in 2013 and continues to explore that area. He also holds an MBA from Colorado State University. Nitin Eusebius is a Sr.
I had the pleasure of writing a mini-bio for Kathy for NAACL 2013 when I got to introduce her as one of the two invited speakers, and learned during that time that she was the first woman chair of computer science at Columbia and also the first woman to get tenure in the entirety of Columbia's School of Engineering and Applied Science.
Embeddings capture the information content in bodies of text, allowing natural language processing (NLP) models to work with language in a numeric form. In entered the Big Data space in 2013 and continues to explore that area. He also holds an MBA from Colorado State University.
Language Disparity in Natural Language Processing This digital divide in natural language processing (NLP) is an active area of research. 2 ] Multilingual models perform worse on several NLP tasks on low resource languages than on high resource languages such as English.[ Common Crawl makes up 60% of GPT-3 training data.[ OpenAI API.
This new experimental tokenizer uses spaCy’s built-in NER component under the hood to segment on the character level, following the idea behind the Elephant tokenizer (Evang et al. If you haven’t already installed transformers , you might want to have a look at our recommended installation steps.
This has caused some fear among the general population; some criticism among other NLP people; and many questions from their relatives ("hey, look at this article I've found - did they just solve NLP? The effect is similar to the effect that pre-trained word embeddings had on NLP in 2013.
I wrote this blog post in 2013, describing an exciting advance in natural language understanding technology. You should probably at least skim that post before reading this one, unless you’re very familiar with NLP research. The derivation for the transition system we’re using, Arc Hybrid, is in Goldberg and Nivre (2013).
P16-1152 : Artem Sokolov; Julia Kreutzer; Christopher Lo; Stefan Riezler Learning Structured Predictors from Bandit Feedback for Interactive NLP This was perhaps my favorite paper of the conference because it's trying to do something new and hard and takes a nice approach. P16-2096 : Dirk Hovy; Shannon L.
You should also read these sources (which mostly focus on panels, not invited speakers, and also mostly focus on gender): Four steps to put an end to all-male panels at conferences , Bronwen Clune, The Guardian, 2013 Stop Agreeing To Be On All-Male Panels Just Stop , Emily Peck, Huffington Post, 2016 How to avoid an all-male panel?
Cross-lingual learning might be useful—but why should we care about applying NLP to other languages in the first place? The NLP Resource Hierarchy In current machine learning, the amount of available training data is the main factor that influences an algorithm's performance. 2015 , Artetxe et al.,
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many natural language processing (NLP) tasks. They are now the foundation of today’s NLP systems. 2013. ↩ Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing.
Following its successful adoption in computer vision and voice recognition, DL will continue to be applied in the domain of natural language processing (NLP). ACM, 2013: 2333–2338. [2] 2] Minghui Qiu and Feng-Lin Li. MeChat: A Sequence to Sequence and Rerank based Chatbot Engine.
2013 ), MCScript ( Modi et al., Among current key applications of NLP, QA has the lowest linguistic global utility, i.e. performance averaged across the world's languages ( Blasi et al., Linguistic and demographic utility of different NLP applications ( Blasi et al., 2018 ), Children's Book Test ( Hill et al.,
2013) GAMI-Net : Generalized Additive Model with Structured Interactions (Yang, Zhang and Sudjianto, 2021) ReLU-DNN : Deep ReLU Networks using Aletheia Unwrapper and Sparsification (Sudjianto, et al. which uses LLMs and various other NLP models that runs locally on your machine for evaluation. 2019; Lou, et al.
Fast-forward a couple of decades: I was (and still am) working at Lexalytics, a text-analytics company that has a comprehensive NLP stack developed over many years. As with ULMFiT and ELMo, these contextual word vectors could be incorporated into any NLP application. I was out of the neural net biz. and BERT. Socher, L.-J.
Natural Language Processing (NLP) techniques can be applied to analyze and understand unstructured text data. The integration of AI and ML into data engineering pipelines enables a wide range of applications. For example, predictive analytics models can be trained on historical data to make accurate forecasts. Zaharia, M., Morgan Kaufmann.
3] Don Norman (2013). 4] Google, Gartner and Motista (2013). Continuous Discovery Habits: Discover Products that Create Customer Value and Business Value. [2] 2] Orbit Media (2022). New Blogging Statistics: What Content Strategies Work in 2022? We asked 1016 Bloggers. [3] The Design of Everyday Things. [4]
The first DARPA funding that Snorkel ever had back in 2012, 2013 was a wonderful project called SIMPLEX. Then, once they have the information, they have to understand and be tuned how to make the right decision for their domain, their company, their objectives. This segues into another topic that I’m always a broken record about.
Recent Intersections Between Computer Vision and Natural Language Processing (Part Two) This is the second instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and Natural Language Processing (NLP). Attention and Memory in Deep Learning and NLP. In: Daniilidis K., Paragios N.
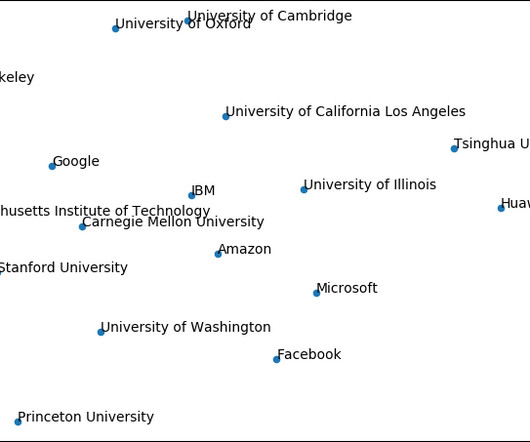
I am sharing here the yearly paper analysis for 2021, containing statistics about ML and NLP publications from the past year. Microsoft, CAS, Amazon, Tencent, Cambridge, Washington and Alibaba stand out as having quite a large proportion of papers at NLP conferences, whereas the other top organizations seem to focus mostly on ML venues.
Recent Intersections Between Computer Vision and Natural Language Processing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and Natural Language Processing (NLP). Thanks for reading!
2] , but gained extreme popularity with word2vec [3] in 2013. Suggested Reading: Deep Learning, NLP, and Representations , from Christopher Olah's blog (more technical and advanced). CoRR, 2013. This approach was first presented in 2003 by Bengio et al. [2] There are also some other variants of word embeddings, like GloVe [4].
Star our repo: ai-distillery And clap your little hearts out for MTank ! References Harris, Z. Distributional structure. Word, 10(2–3), 146–162. Mikolov, T., Sutskever, I., Corrado, G. S., & Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In NIPS (pp. 3111–3119). Bojanowski, P.,
We took the opportunity to review major research trends in the animated NLP space and formulate some implications from the business perspective. The article is backed by a statistical and – guess what – NLP-based analysis of ACL papers from the last 20 years. But what is the substance behind the buzz?
The Facebook AI Research Lab (FAIR) Established in 2013, FAIR has quickly become one of the most influential AI research labs in the world, partially when it comes to open-source technology and models such as Llama 2. Another project, SynthID , helps to identify and watermark AI-generated images.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content