
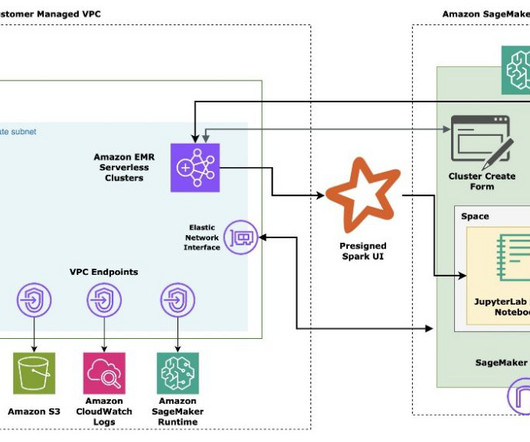
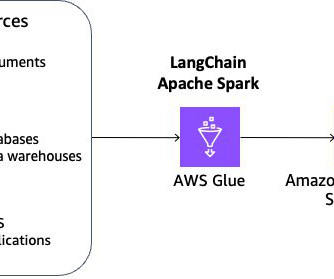
Use LangChain with PySpark to process documents at massive scale with Amazon SageMaker Studio and Amazon EMR Serverless
AWS Machine Learning Blog
SEPTEMBER 3, 2024
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for big data workloads has traditionally been a significant challenge, often requiring specialized expertise.


















Let's personalize your content