
Build high-performance ML models using PyTorch 2.0 on AWS – Part 1
AWS Machine Learning Blog
JUNE 6, 2023
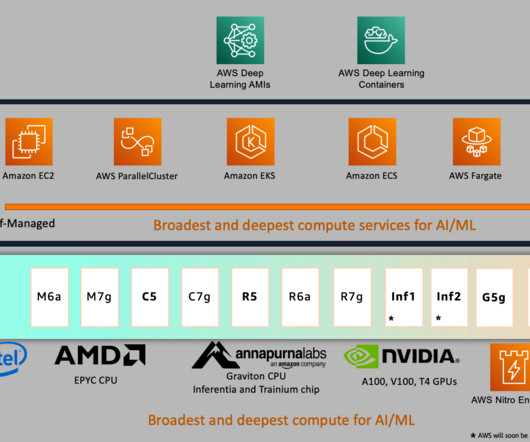
This post further walks through a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) model for sentiment analysis using AWS Deep Learning AMIs (AWS DLAMI) and AWS Deep Learning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge) torch.compile + bf16 + fused AdamW.








Let's personalize your content