This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An early hint of today’s naturallanguageprocessing (NLP), Shoebox could calculate a series of numbers and mathematical commands spoken to it, creating a framework used by the smart speakers and automated customer service agents popular today. In a televised Jeopardy!
Over the past decade, advancements in machine learning, NaturalLanguageProcessing (NLP), and neural networks have transformed the field. Apple introduced Siri in 2011, marking the beginning of AI integration into everyday devices.
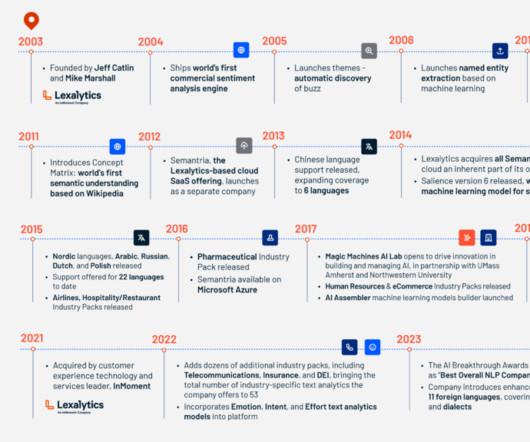
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.
However, the more innovative paper in my view, is a paper with the second-most citations, a 2011 paper titled “ Memory-Based Approximation of the Gaussian Mixture Model Framework for Bandwidth Extension of Narrowband Speech “ In that work, I proposed a new statistical modeling technique that incorporates temporal information in speech.
In other words, traditional machine learning models need human intervention to process new information and perform any new task that falls outside their initial training. For example, Apple made Siri a feature of its iOS in 2011. This early version of Siri was trained to understand a set of highly specific statements and requests.
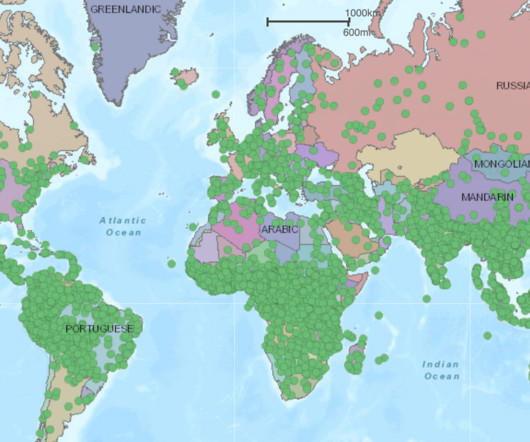
Naturallanguageprocessing (NLP) research predominantly focuses on developing methods that work well for English despite the many positive benefits of working on other languages. Most of the world's languages are spoken in Asia, Africa, the Pacific region and the Americas.
That’s when researchers in information retrieval prototyped what they called question-answering systems, apps that use naturallanguageprocessing ( NLP ) to access text, initially in narrow topics such as baseball. IBM’s Watson became a TV celebrity in 2011 when it handily beat two human champions on the Jeopardy!
As LLMs have grown larger, their performance on a wide range of naturallanguageprocessing tasks has also improved significantly, but the increased size of LLMs has led to significant computational and resource challenges. degree in Computer Science in 2011 from the University of Lille 1. He holds a M.E.
” During this time, researchers made remarkable strides in naturallanguageprocessing, robotics, and expert systems. Notable achievements included the development of ELIZA, an early naturallanguageprocessing program created by Joseph Weizenbaum, which simulated human conversation.
It uses naturallanguageprocessing (NLP) algorithms to understand the context of conversations, meaning it's not just picking up random mentions! Brand24 was founded in 2011 and is based in Wrocław, Poland. They've managed to snag some pretty impressive clients like Intel, H&M, and IKEA!
SA is a very widespread NaturalLanguageProcessing (NLP). Journal of Finance (2011), 66(1):35–65. Proceedings of the 2016 Conference on Empirical Methods in NaturalLanguageProcessing, pages 595–605. I am a researcher, and its ability to do sentiment analysis (SA) interests me. Hamilton, W.
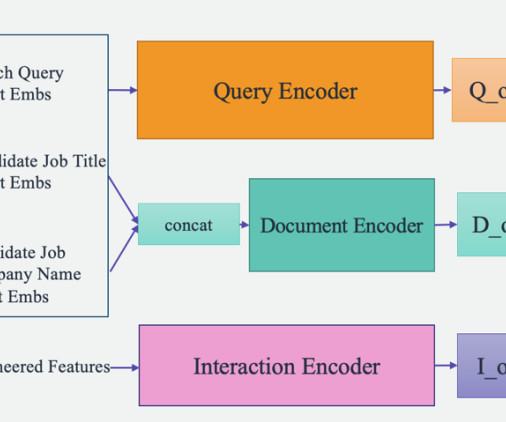
Established in 2011, Talent.com aggregates paid job listings from their clients and public job listings, and has created a unified, easily searchable platform. Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository.
Founded in 2011, Talent.com is one of the world’s largest sources of employment. With over 30 million jobs listed in more than 75 countries, Talent.com serves jobs across many languages, industries, and distribution channels.
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). They’re mostly trained on general domain corpora, making them less effective on domain-specific tasks.
This is the sort of representation that is useful for naturallanguageprocessing. However, a similar thing holds true for the word-topic matrix: if two words have similar meanings, their topic vectors will be similar. Bengio, and P. Haffner (1998) “ Gradient-based learning applied to document recognition ” S.
Sentiment analysis, a branch of naturallanguageprocessing (NLP), has evolved as an effective method for determining the underlying attitudes, emotions, and views represented in textual information. The 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011). abs/2005.03993 Andrew L.
Developing models that work for more languages is important in order to offset the existing language divide and to ensure that speakers of non-English languages are not left behind, among many other reasons. Around 400 languages have more than 1M speakers and around 1,200 languages have more than 100k [1].
And then he picked up again, I think, around 2011, when big data became a thing, then we had lots of faster computation power, and then it just accelerated from that. I took one naturallanguageprocessing class and the professor. So it’s only around 2013, 2011, where AI became a thing in the industry.
The Quora dataset is an example of an important type of NaturalLanguageProcessing problem: text-pair classification. People have been using context windows as features since at least Collobert and Weston (2011) , and likely much before. In updated experiments the Maxout Window Encoding helps as expected.
In ACL 2011. The rise of crowdsourcing. Wired magazine 14.6 Zaidan and Chris Callison-Burch Crowdsourcing translation: professional quality from non-professionals.
Cross-lingual learning in the transfer learning taxonomy ( Ruder, 2019 ) Methods from domain adaptation have also been applied to cross-lingual transfer ( Prettenhofer & Stein, 2011 , Wan et al., For a clearer distinction between domain adaptation and cross-lingual learning, have a look at this section.
Naturallanguages introduce many unexpected ambiguities, which our world-knowledge immediately filters out. ACL 2011 The dynamic oracle training method was first described here: A Dynamic Oracle for Arc-Eager Dependency Parsing. Syntactic Processing Using the Generalized Perceptron and Beam Search.
of the spaCy NaturalLanguageProcessing library includes a huge number of features, improvements and bug fixes. spaCy is an open-source library for industrial-strength naturallanguageprocessing in Python. Version 2.1 Prodigy is a fully scriptable annotation tool that complements spaCy extremely well.
2011 ), many referents have no language-specific terms in some languages, e.g. bowling ball, hamburger, lottery ( Ponti et al., In the tutorial, we focus on two main categories of question answering studied in the literature: open-retrieval question answering (ORQA) and reading comprehension (RC). In COPA ( Roemmele et al.,
NaturalLanguageProcessing (NLP) techniques can be applied to analyze and understand unstructured text data. The integration of AI and ML into data engineering pipelines enables a wide range of applications. For example, predictive analytics models can be trained on historical data to make accurate forecasts. Follow Now ?
Physical damage coverage for vehicles with an ISO symbol of more than 20 for model year 2010 and earlier or ISO symbol 41 for model year 2011 and later. Liability coverage for vehicles with an ISO symbol of more than 25 for vehicles with model year 2010 and earlier or ISO symbol 59 for model year 2011 and later.
This split has steadily grown since 2011, when the percentages were nearly equal. researchers surveyed naturallanguageprocessing researchers, as evidenced by publications, to get a handle on what AI experts think about AI research, HAI reported. Industry, not academia, is drawing new AI Ph.D.’s percent of all AI Ph.D.’s
On completion of an MBA from New York University, Ryan joined The Boston Consulting Group (BCG) in 2011 as a strategy consultant. His professional career began as an engineer, with a focus on mobile network data engineering in Australia, Asia and North America.
They have been proven to be efficient in diverse applications and learning settings such as cybersecurity [1] and fraud detection, remote sensing, predicting best next steps in financial decision-making, medical diagnosis, and even computer vision and naturallanguageprocessing (NLP) tasks. References [1] Raj Kumar, P.
Recent Intersections Between Computer Vision and NaturalLanguageProcessing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and NaturalLanguageProcessing (NLP). Thanks for reading! Online] arXiv: 1710.01288.
Originally, it was trained to answer natural logic questions -- or more precisely, to form the correct question to a given answer, as in the television game show Jeopardy. On February 2011, Watson competed in Jeopardy against former winners of the show, and won!
text generation model on domain-specific datasets, enabling it to generate relevant text and tackle various naturallanguageprocessing (NLP) tasks within a particular domain using few-shot prompting. This fine-tuning process involves providing the model with a dataset specific to the target domain.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content