This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
research scientist with over 16 years of professional experience in the fields of speech/audio processing and machine learning in the context of Automatic Speech Recognition (ASR), with a particular focus and hands-on experience in recent years on deeplearning techniques for streaming end-to-end speech recognition.
In other words, traditional machine learning models need human intervention to process new information and perform any new task that falls outside their initial training. For example, Apple made Siri a feature of its iOS in 2011. Human intervention was required to expand Siri’s knowledge base and functionality.
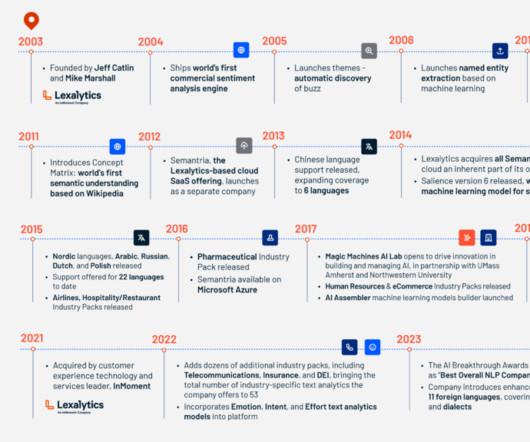
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.
As LLMs have grown larger, their performance on a wide range of naturallanguageprocessing tasks has also improved significantly, but the increased size of LLMs has led to significant computational and resource challenges. degree in Computer Science in 2011 from the University of Lille 1. He holds a M.E.
This post is co-authored by Anatoly Khomenko, Machine Learning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. Founded in 2011, Talent.com is one of the world’s largest sources of employment. It’s designed to significantly speed up deeplearning model training. The model is replicated on every GPU.
This post is co-authored by Anatoly Khomenko, Machine Learning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. Established in 2011, Talent.com aggregates paid job listings from their clients and public job listings, and has created a unified, easily searchable platform.
That’s when researchers in information retrieval prototyped what they called question-answering systems, apps that use naturallanguageprocessing ( NLP ) to access text, initially in narrow topics such as baseball. IBM’s Watson became a TV celebrity in 2011 when it handily beat two human champions on the Jeopardy!
” During this time, researchers made remarkable strides in naturallanguageprocessing, robotics, and expert systems. Notable achievements included the development of ELIZA, an early naturallanguageprocessing program created by Joseph Weizenbaum, which simulated human conversation.
They were not wrong: the results they found about the limitations of perceptrons still apply even to the more sophisticated deep-learning networks of today. And indeed we can see other machine learning topics arising to take their place, like “optimization” in the mid-’00s, with “deeplearning” springing out of nowhere in 2012.
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). He focuses on developing scalable machine learning algorithms.
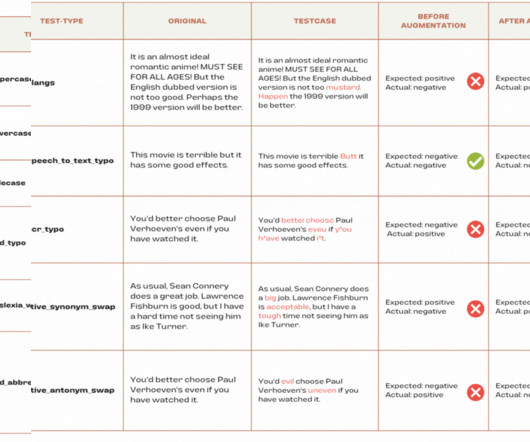
In this post, I’ll explain how to solve text-pair tasks with deeplearning, using both new and established tips and technologies. The Quora dataset is an example of an important type of NaturalLanguageProcessing problem: text-pair classification. This data set is large, real, and relevant — a rare combination.
Sentiment analysis, a branch of naturallanguageprocessing (NLP), has evolved as an effective method for determining the underlying attitudes, emotions, and views represented in textual information. Learning Word Vectors for Sentiment Analysis. abs/2005.03993 Andrew L. Maas, Raymond E. Daly, Peter T.
Developing models that work for more languages is important in order to offset the existing language divide and to ensure that speakers of non-English languages are not left behind, among many other reasons. This post is partially based on a keynote I gave at the DeepLearning Indaba 2022. Kolesnikov, A.,
And then he picked up again, I think, around 2011, when big data became a thing, then we had lots of faster computation power, and then it just accelerated from that. And neural networks now has become deeplearning. I took one naturallanguageprocessing class and the professor. And I was hooked.
of the spaCy NaturalLanguageProcessing library includes a huge number of features, improvements and bug fixes. spaCy is an open-source library for industrial-strength naturallanguageprocessing in Python. Version 2.1 Prodigy is a fully scriptable annotation tool that complements spaCy extremely well.
Recent Intersections Between Computer Vision and NaturalLanguageProcessing (Part One) This is the first instalment of our latest publication series looking at some of the intersections between Computer Vision (CV) and NaturalLanguageProcessing (NLP). Thanks for reading!
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content