This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Two years later, in 2011, I co-founded Crashlytics, a mobile crash reporting tool which was acquired by Twitter in 2013 and then again by Google in 2017. At the second tier, Digits AI leverages custom-trained, proprietary deep-learning models to understand the unique attributes of small-business finance and double-entry accounting.
research scientist with over 16 years of professional experience in the fields of speech/audio processing and machine learning in the context of Automatic Speech Recognition (ASR), with a particular focus and hands-on experience in recent years on deeplearning techniques for streaming end-to-end speech recognition.
In other words, traditional machine learning models need human intervention to process new information and perform any new task that falls outside their initial training. For example, Apple made Siri a feature of its iOS in 2011. This early version of Siri was trained to understand a set of highly specific statements and requests.
Deeplearning — a software model that relies on billions of neurons and trillions of connections — requires immense computational power. By 2011, AI researchers had discovered NVIDIA GPUs and their ability to handle deeplearning’s immense processing needs.
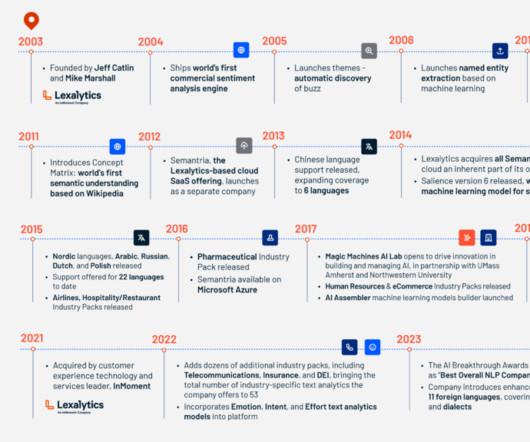
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.
To address customer needs for high performance and scalability in deeplearning, generative AI, and HPC workloads, we are happy to announce the general availability of Amazon Elastic Compute Cloud (Amazon EC2) P5e instances, powered by NVIDIA H200 Tensor Core GPUs. degree in Computer Science in 2011 from the University of Lille 1.
What sets Dr. Ho apart is her pioneering work in applying deeplearning techniques to astrophysics. She led the first effort to accelerate astrophysical simulations with deeplearning. Ho’s contributions have not gone unnoticed.
A current PubMed search using the Mesh keywords “artificial intelligence” and “radiology” yielded 5,369 papers in 2021, more than five times the results found in 2011. Autoencoder deeplearning models are a more traditional alternative to GANs because they are easier to train and produce more diverse outputs.
This post is co-authored by Anatoly Khomenko, Machine Learning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. Founded in 2011, Talent.com is one of the world’s largest sources of employment. It’s designed to significantly speed up deeplearning model training. The model is replicated on every GPU.
jpg': {'class': 111, 'label': 'Ford Ranger SuperCab 2011'}, '00236.jpg': Training with TFRecords vs Raw Input Most deeplearning tutorials, both Pytorch and Tensorflow, typically show you how to prepare your data for model training by using simple DataGenerators which read the raw data.
This post is co-authored by Anatoly Khomenko, Machine Learning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. Established in 2011, Talent.com aggregates paid job listings from their clients and public job listings, and has created a unified, easily searchable platform.
However, this work demonstrated that with sufficient data and computational resources, deeplearning models can learn complex features through a general-purpose algorithm like backpropagation. Further, pre-training on the ImageNet Fall 2011 dataset, followed by fine-tuning, reduced the error to 15.3%. Check out the Paper.
But the machine learning engines driving them have grown significantly, increasing their usefulness and popularity. IBM’s Watson became a TV celebrity in 2011 when it handily beat two human champions on the Jeopardy! Today, LLMs are taking question-answering systems to a whole new level.
Image classification employs AI-based deeplearning models to analyze images and perform object recognition, as well as a human operator. It is one of the largest resources available for training deeplearning models in object recognition tasks. 2011 – A good ILSVRC image classification error rate is 25%.
The advent of big data, coupled with advancements in Machine Learning and deeplearning, has transformed the landscape of AI. Techniques such as neural networks, particularly deeplearning, have enabled significant breakthroughs in image and speech recognition, natural language processing, and autonomous systems.
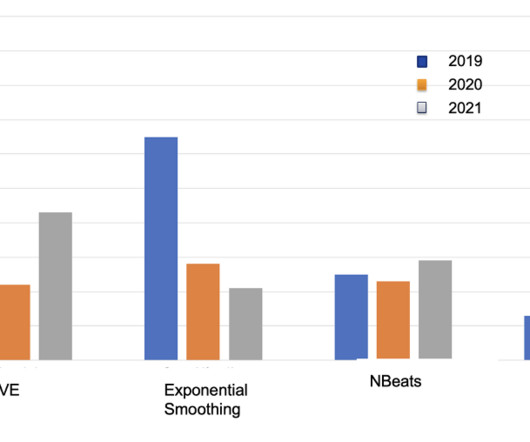
For example, in the 2019 WAPE value, we trained our model using sales data between 2011–2018 and predicted sales values for the next 12 months (2019 sale). We trained three models using data from 2011–2018 and predicted the sales values until 2021. He focuses on machine learning, deeplearning and end-to-end ML solutions.
Our software helps several leading organizations start with computer vision and implement deeplearning models efficiently with minimal overhead for various downstream tasks. On the Caltech-USCD Birds-200-2011 (CUB-200-2011) dataset, the SOTA ZSL model stands at a 72.3 Get a demo here. The CLIP model for ZSL shows 64.3%
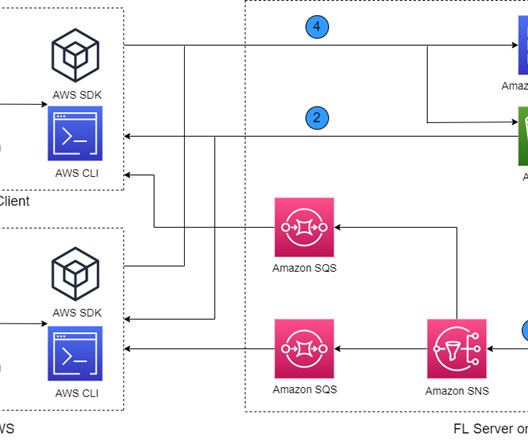
Machine learning (ML), especially deeplearning, requires a large amount of data for improving model performance. Federated learning (FL) is a distributed ML approach that trains ML models on distributed datasets. Her current areas of interest include federated learning, distributed training, and generative AI.
Today’s boom in computer vision (CV) started at the beginning of the 21 st century with the breakthrough of deeplearning models and convolutional neural networks (CNN). We split them into two categories – classical CV approaches, and papers based on deep-learning. Find the SURF paper here. Find the ImageNet paper here.
Our software helps several leading organizations start with computer vision and implement deeplearning models efficiently with minimal overhead for various downstream tasks. VOC2011 PASCAL VOC challenge took a big step forward in 2011 with VOC2011. provides a robust end-to-end computer vision infrastructure – Viso Suite.
The creation of the LSTM-based sentiment analysis model will provide a thorough method for using deeplearning techniques for analyzing human sentiment from textual data, leveraging PyTorch’s flexibility and efficiency. Learning Word Vectors for Sentiment Analysis. abs/2005.03993 Andrew L. Maas, Raymond E. Daly, Peter T.
In this post, I’ll explain how to solve text-pair tasks with deeplearning, using both new and established tips and technologies. The SNLI dataset is over 100x larger than previous similar resources, allowing current deep-learning models to be applied to the problem.
They were not wrong: the results they found about the limitations of perceptrons still apply even to the more sophisticated deep-learning networks of today. And indeed we can see other machine learning topics arising to take their place, like “optimization” in the mid-’00s, with “deeplearning” springing out of nowhere in 2012.
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). He focuses on developing scalable machine learning algorithms.
Artificial Intelligence (AI) Integration: AI techniques, including machine learning and deeplearning, will be combined with computer vision to improve the protection and understanding of cultural assets. Preservation of cultural heritage and natural history through game-based learning. Ahmad, M., & Selviandro, N.
Because machine learning is essential in computer vision, OpenCV contains a complete, general-purpose ML Library focused on statistical pattern recognition and clustering. Since 2011, OpenCV provides functionality for NVIDIA CUDA and Graphic Processing Unit (GPU) hardware acceleration and Open Computing Language (OpenCL).
And then he picked up again, I think, around 2011, when big data became a thing, then we had lots of faster computation power, and then it just accelerated from that. And neural networks now has become deeplearning. So it’s only around 2013, 2011, where AI became a thing in the industry.
When the FRB’s guidance was first introduced in 2011, modelers often employed traditional regression -based models for their business needs. While SR 11-7 is prescriptive in its guidance, one challenge that validators face today is adapting the guidelines to modern ML methods that have proliferated in the past few years.
With most ML use cases moving to deeplearning, models’ opacity has increased significantly. Reference Scikit-learn: Machine Learning in Python , Pedregosa et al., 2825–2830, 2011. Reducing the number of features directly reduces training and inference costs and time. JMLR 12, pp. Menze, B.H.,
It’s widely used in production and research systems for extracting information from text, developing smarter user-facing features, and preprocessing text for deeplearning. In 2011, deeplearning methods were proving successful for NLP, and techniques for pretraining word representations were already in use.
In all cases, academic research was not left in the dust but went on to make contributions that shaped the next era, from KenLM ( Heafield, 2011 ), an efficient LM library that enabled academics to outperform industry MT systems, to the word2vec alternative GloVe ( Pennington et al., 2018 ) and ULMFiT ( Howard & Ruder, 2018 ).
In all cases, academic research was not left in the dust but went on to make contributions that shaped the next era, from KenLM ( Heafield, 2011 ), an efficient LM library that enabled academics to outperform industry MT systems, to the word2vec alternative GloVe ( Pennington et al., 2018 ) and ULMFiT ( Howard & Ruder, 2018 ).
This post is partially based on a keynote I gave at the DeepLearning Indaba 2022. Bender [2] highlighted the need for language independence in 2011. The DeepLearning Indaba 2022 in Tunesia. I've tried to cover as many contributions as possible but undoubtedly missed relevant work. ↩︎ Ruder, S.,
The idea of low-code was introduced in 2011. has been a leader in AI vision software to create custom computer vision and deeplearning applications that process video feeds of numerous cameras in real-time with deployed AI algorithms. Drag-and-drop editor of a low-code/no-code computer vision platform Viso Suite.
The machine learning model So let’s start with the first step of building the machine learning model. We’ll be using our own deeplearning library, Thinc , which is lightweight and offers a functional programming API for composing neural networks. This powerful approach provides a lot of flexibility and transparency.
JPEG-DL Instead, the new work , titled JPEG Inspired DeepLearning , offers a much simpler architecture, which can even be imposed upon existing models. However, freezing parts of a model during training tends to reduce the versatility of the model, as well as its broader resilience to novel data.
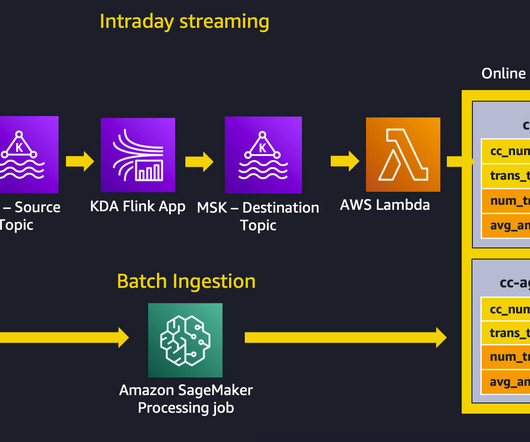
It’s easy to learn Flink if you have ever worked with a database or SQL-like system by remaining ANSI-SQL 2011 compliant. About the Authors Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions.
Much the same way we iterate, link and update concepts through whatever modality of input our brain takes — multi-modal approaches in deeplearning are coming to the fore. While an oversimplification, the generalisability of current deeplearning approaches is impressive.
Many Libraries: Python has many libraries and frameworks (We will be looking some of them below) that provide ready-made solutions for common computer vision tasks, such as image processing, face detection, object recognition, and deeplearning. It is a fork of the Python Imaging Library (PIL), which was discontinued in 2011.
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for data science, machine learning (ML), and computational science. The distribution is versioned using SemVer and will be released on a regular basis moving forward.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content