This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Further, pre-training on the ImageNet Fall 2011 dataset, followed by fine-tuning, reduced the error to 15.3%. In the ILSVRC-2012 competition, the model reached a top-5 validation error rate of 18.2%, which improved to 16.4% when predictions from five CNNs were averaged. If you like our work, you will love our newsletter.
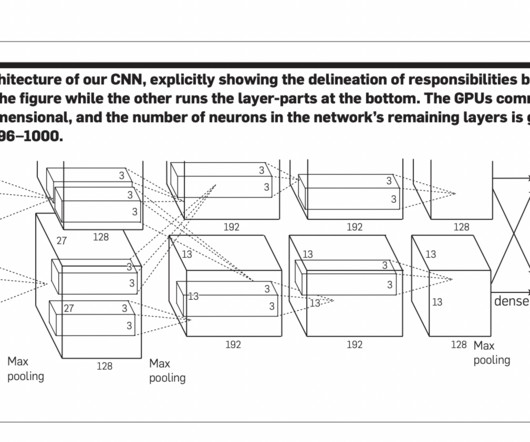
Today’s boom in computer vision (CV) started at the beginning of the 21 st century with the breakthrough of deep learning models and convolutionalneuralnetworks (CNN). They found that removing any convolutional layer (each containing less than 1% of the model’s parameters) resulted in inferior performance.
The traditional machine learning (ML) paradigm involves training models on extensive labeled datasets. Matching Networks: The algorithm computes embeddings using a support set, and one-shot learns by classifying the query data sample based on which support set embedding is closest to the query embedding – source.
Initially, we had been using classic symbolic NLP algorithms, but in recent years we had started to incorporate machine learning (ML) models into more and more parts of our code, including our own implementations of conditional random fields [ 11 ] and a home-grown maximum entropy classifier. Hinton (again!)
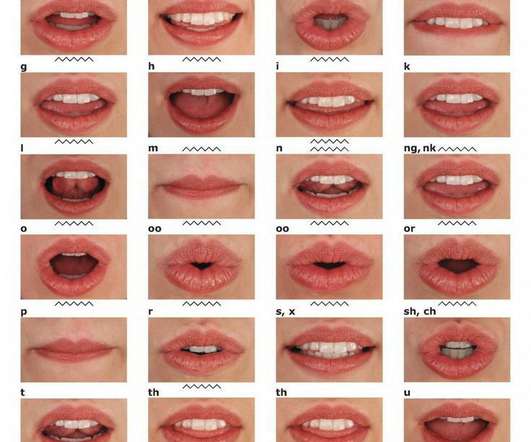
Source : Hassanat (2011) [13] These approaches obtained impressive results (over 70% word accuracy) for tests performed with classifiers trained on the same speaker they were tested on. An Intuitive Explanation of ConvolutionalNeuralNetworks. Source : GIF created by The M Tank, originally from LipNet video. [22]
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content