This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Sentiment analysis to categorize mentions as positive, negative, or neutral. It uses natural language processing (NLP) algorithms to understand the context of conversations, meaning it's not just picking up random mentions! Brand24 was founded in 2011 and is based in Wrocław, Poland. Easy reporting functionality.
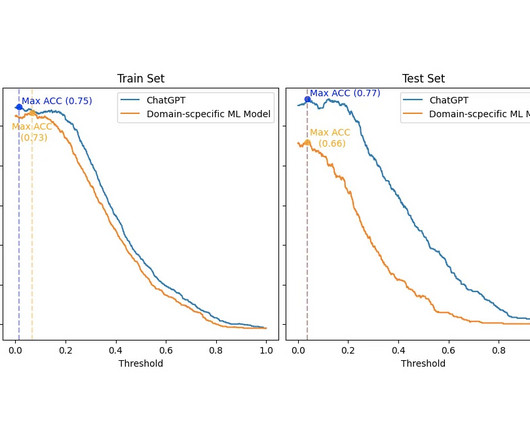
So, to make a viable comparison, I had to: Categorize the dataset scores into Positive , Neutral , or Negative labels. This evaluation assesses how the accuracy (y-axis) changes regarding the threshold (x-axis) for categorizing the numeric Gold-Standard dataset for both models. First, I must be honest. Then, I made a confusion matrix.
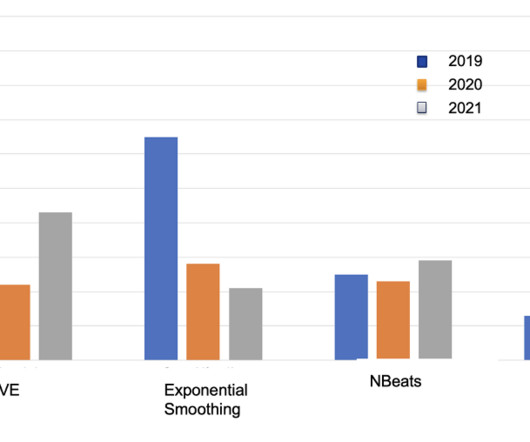
We also demonstrate the performance of our state-of-the-art point cloud-based product lifecycle prediction algorithm. These features include product fabrication techniques and other related categorical information related to the products. We trained three models using data from 2011–2018 and predicted the sales values until 2021.
It is a technique used in computer vision to identify and categorize the main content (objects) in a photo or video. The Need for Image Training Datasets To train the image classification algorithms we need image datasets. These datasets contain multiple images similar to those the algorithm will run in real life.
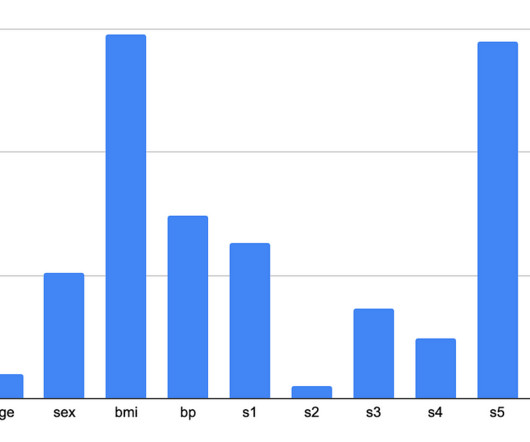
What we are looking for in these algorithms is to output a list of features along with corresponding importance values. Next, there are categorical features, usually represented as small one-hot vectors. fall under categorical features. Most feature-importance algorithms deal very well with dense and categorical features.
Also, you can use N-shot learning models to label data samples with unknown classes and feed the new dataset to supervised learning algorithms for better training. The AI community categorizes N-shot approaches into few, one, and zero-shot learning. The following algorithms combine the two approaches to solve the FSL problem.
Computer vision algorithms can reconstruct a highly detailed 3D model by photographing objects from different perspectives. But computer vision algorithms can assist us in digitally scanning and preserving these priceless manuscripts. These ground-breaking areas redefine how we connect with and learn from our collective past.
The OpenCV library contains over 2500 algorithms, extensive documentation, and sample code for real-time computer vision. Since 2011, OpenCV provides functionality for NVIDIA CUDA and Graphic Processing Unit (GPU) hardware acceleration and Open Computing Language (OpenCL). and fleeting them into one or multiple vision algorithms.
Data mining involves using sophisticated algorithms to identify patterns and relationships in data that might not be immediately apparent. These techniques can be applied to a wide range of data types, including numerical data, categorical data, text data, and more. Follow Now ? Connect with me on LinkedIn for updates. Zaharia, M.,
Bender [2] highlighted the need for language independence in 2011. 92] categorized the languages of the world into six different categories based on the amount of labeled and unlabeled data available in them. Around 400 languages have more than 1M speakers and around 1,200 languages have more than 100k [1]. Joshi et al. [92]
In 2011, deep learning methods were proving successful for NLP, and techniques for pretraining word representations were already in use. This is exactly what algorithms like word2vec, GloVe and FastText set out to solve. It helps most for text categorization and parsing, but is less effective for named entity recognition.
Ensemble learning refers to the use of multiple learning models and algorithms to gain more accurate predictions than any single, individual learning algorithm. We tend to categorize ensembles by the techniques used to train them, their composition, and the way they merge the different predictions into a single inference.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content