This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The company specializes in image processing and AI, with extensive expertise in research, implementation, and optimization of algorithms for embedded platforms and the in-car automotive industry. Yehuda Holtzman serves as the CEO of Cipia. Cipia is headquartered in Israel, with global offices in the United States and China.
In the following two decades, IBM continued to advance AI with research into machine learning, algorithms, NLP and image processing. contest viewed by millions in February 2011, Watson competed in two matches against the foremost all-time champions. In a televised Jeopardy!
By leveraging advanced AI algorithms, the app identifies the core concepts behind each question and curates the most relevant content from trusted sources across the web. and released in 2011, Symbolab has become a go-to resource for students seeking to understand complex mathematical concepts and improve their problem-solving skills.
Netflix machine-learning algorithms, for example, leverage rich user data not just to recommend movies, but to decide which new films to make. Generative AI algorithms, like those used to create ChatGPT, train on large language datasets. Facial recognition software deploys neural nets to leverage pixel data from millions of images.
Two years later, in 2011, I co-founded Crashlytics, a mobile crash reporting tool which was acquired by Twitter in 2013 and then again by Google in 2017. Can you discuss the types of machine learning algorithms that are used? We were acquired by Box in 2009.
Apple introduced Siri in 2011, marking the beginning of AI integration into everyday devices. Core ML brought powerful machine learning algorithms to the iOS platform, enabling apps to perform tasks such as image recognition, NLP, and predictive analytics. Ethical considerations regarding data privacy and AI bias are critical.
However, the more innovative paper in my view, is a paper with the second-most citations, a 2011 paper titled “ Memory-Based Approximation of the Gaussian Mixture Model Framework for Bandwidth Extension of Narrowband Speech “ In that work, I proposed a new statistical modeling technique that incorporates temporal information in speech.
A current PubMed search using the Mesh keywords “artificial intelligence” and “radiology” yielded 5,369 papers in 2021, more than five times the results found in 2011.
These models rely on learning algorithms that are developed and maintained by data scientists. For example, Apple made Siri a feature of its iOS in 2011. In other words, traditional machine learning models need human intervention to process new information and perform any new task that falls outside their initial training.
The San Francisco-based company has completed more than 800,000 deliveries in seven countries since its start in 2011. You can pick the right place for your algorithms to run to make sure you’re getting the most out of the hardware and the power that you are putting into the system,” said Frantz.
He graduated in 2011 from IISERs five-year dual science degree program with bachelors and masters degrees, with a concentration in mathematics. The existing algorithms were not efficient. He then earned a masters degree in operations research in 2012 from Columbia.
Why is it that Amazon, which has positioned itself as “the most customer-centric company on the planet,” now lards its search results with advertisements, placing them ahead of the customer-centric results chosen by the company’s organic search algorithms, which prioritize a combination of low price, high customer ratings, and other similar factors?
It uses natural language processing (NLP) algorithms to understand the context of conversations, meaning it's not just picking up random mentions! Brand24 was founded in 2011 and is based in Wrocław, Poland. It's smart enough to figure out if someone's actually talking about your brand or just mentioning something similar.
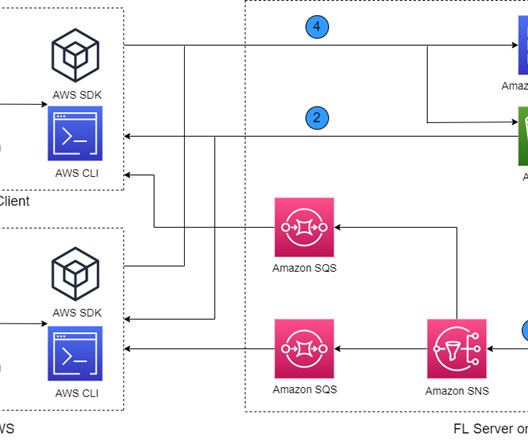
Challenges in FL You can address the following challenges using algorithms running at FL servers and clients in a common FL architecture: Data heterogeneity – FL clients’ local data can vary (i.e., Despite these challenges of FL algorithms, it is critical to build a secure architecture that provides end-to-end FL operations.
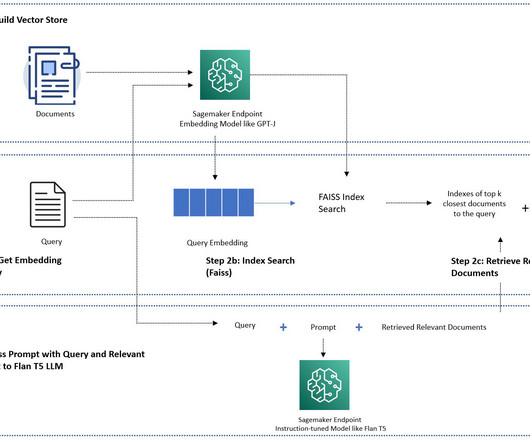
There are a few limitations of using off-the-shelf pre-trained LLMs: They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19). If you have a large dataset, the SageMaker KNN algorithm may provide you with an effective semantic search.
In our pipeline, we used Amazon Bedrock to develop a sentence shortening algorithm for automatic time scaling. Here’s the shortened sentence using the sentence shortening algorithm. She is also the recipient of the Best Paper Award at IEEE NetSoft 2016, IEEE ICC 2011, ONDM 2010, and IEEE GLOBECOM 2005. Cristian Torres is a Sr.
It has been over a decade since the Federal Reserve Board (FRB) and the Office of the Comptroller of the Currency (OCC) published its seminal guidance focused on Model Risk Management ( SR 11-7 & OCC Bulletin 2011-12 , respectively). Conclusion.
Back in 2010, Saad Mahamood (then a PhD student with me) developed an NLG system which summarised data about sick babies in neonatal intensive care for their parents ( Mahamood and Reiter 2011 ); this system was deployed and used in the hospital for a few years, and parents in general were very appreciative.
Customers using dynamic programming (DP) algorithms for applications like genome sequencing or accelerated data analytics can also see further benefit from P5e through support for the DPX instruction set. degree in Computer Science in 2011 from the University of Lille 1. He holds a M.E. degree from the University of Science and a Ph.D.
Turing proposed the concept of a “universal machine,” capable of simulating any algorithmic process. The development of LISP by John McCarthy became the programming language of choice for AI research, enabling the creation of more sophisticated algorithms. Simon, demonstrated the ability to prove mathematical theorems.
This approach allows Apple to effectively remove a number of privacy concerns by eliminating the need for extensive data sharing and having the algorithms operate locally on users’ devices. Siri launched back in 2011 and became the first modern virtual assistant of its kind.
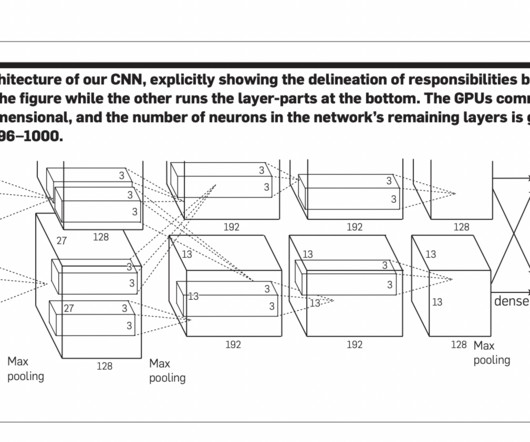
However, this work demonstrated that with sufficient data and computational resources, deep learning models can learn complex features through a general-purpose algorithm like backpropagation. Further, pre-training on the ImageNet Fall 2011 dataset, followed by fine-tuning, reduced the error to 15.3%.
The Need for Image Training Datasets To train the image classification algorithms we need image datasets. These datasets contain multiple images similar to those the algorithm will run in real life. The labels provide the Knowledge the algorithm can learn from. 2011 – A good ILSVRC image classification error rate is 25%.
Founded in 2011, Talent.com is one of the world’s largest sources of employment. The performance of Talent.com’s matching algorithm is paramount to the success of the business and a key contributor to their users’ experience.
At a higher level, algorithms are biased and discriminate against speakers of non-English languages or simply with different accents. A classic example are n-gram language models, which perform significantly worse for languages with elaborate morphology and relatively free word order ( Bender, 2011 ).
We also demonstrate the performance of our state-of-the-art point cloud-based product lifecycle prediction algorithm. For example, in the 2019 WAPE value, we trained our model using sales data between 2011–2018 and predicted sales values for the next 12 months (2019 sale). We next calculated the MAPE for the actual sales values.
Also, you can use N-shot learning models to label data samples with unknown classes and feed the new dataset to supervised learning algorithms for better training. The following algorithms combine the two approaches to solve the FSL problem. The diagram below illustrates the algorithm. Let’s discuss each in more detail.
1. Matrix (1999-2011) “The Matrix” trilogy, directed by the Wachowski siblings, is a groundbreaking science fiction series that explores themes of reality, consciousness, and the power of data and information. 10 Best Data Science Movies you need to Watch!
Some of his early published work on the question, from 2011 and 2012, raises questions about what shape those models will take, and how hard it would be to make developing them go well — all of which will only look more important with a decade of hindsight.
Today, almost all high-performance parsers are using a variant of the algorithm described below (including spaCy). This doesn’t just give us a likely advantage in learnability; it can have deep algorithmic implications. But the parsing algorithm I’ll be explaining deals with projective trees.
This would change in 1986 with the publication of “Parallel Distributed Processing” [ 6 ], which included a description of the backpropagation algorithm [ 7 ]. In retrospect, this algorithm seems obvious, and perhaps it was. We were definitely in a Kuhnian pre-paradigmatic period. It would not be the last time that happened.)
Computer vision algorithms can reconstruct a highly detailed 3D model by photographing objects from different perspectives. But computer vision algorithms can assist us in digitally scanning and preserving these priceless manuscripts. These ground-breaking areas redefine how we connect with and learn from our collective past.
What we are looking for in these algorithms is to output a list of features along with corresponding importance values. Most feature-importance algorithms deal very well with dense and categorical features. We will cover very rudimentary methods, along with quite sophisticated algorithms. The dataset has 10 dense features.
Pascal VOC (which stands for Pattern Analysis, Statistical Modelling, and Computational Learning Visual Object Classes) is an open-source image dataset for a number of visual object recognition algorithms. As a result of Pascal VOC, researchers, and developers were able to compare various algorithms and methods on an entity basis.
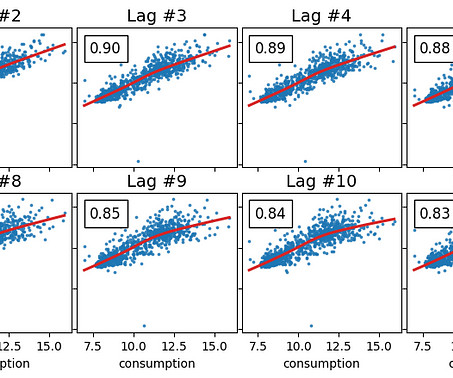
As described in the previous article , we want to forecast the energy consumption from August of 2013 to March of 2014 by training on data from November of 2011 to July of 2013. Experiments Before moving on to the experiments, let’s quickly remember what’s our task.
The OpenCV library contains over 2500 algorithms, extensive documentation, and sample code for real-time computer vision. Since 2011, OpenCV provides functionality for NVIDIA CUDA and Graphic Processing Unit (GPU) hardware acceleration and Open Computing Language (OpenCL). and fleeting them into one or multiple vision algorithms.
The short story is, there are no new killer algorithms. The way that the tokenizer works is novel and a bit neat, and the parser has a new feature set, but otherwise the key algorithms are well known in the recent literature. Dependency Parser The parser uses the algorithm described in my 2014 blog post. 0.2%) difference.
These three are: data collection objective function feedback loops Sample Selection Bias The standard way that machine learning works is to take some samples from a population you care about, run it through a machine learning algorithm, to produce a predictor. Also a highly recommended read.
Outperforming algorithmic trading reinforcement learning systems: A supervised approach to the cryptocurrency market. Journal of Finance (2011), 66(1):35–65. Proceedings of the Second ACM International Conference on AI in Finance (ICAIF ‘21). Felizardo, L. Lima Paiva, F. de Vita Graves, C.; Matsumoto, E. Del-Moral-Hernandez, E.;
When the FRB’s guidance was first introduced in 2011, modelers often employed traditional regression -based models for their business needs. While SR 11-7 is prescriptive in its guidance, one challenge that validators face today is adapting the guidelines to modern ML methods that have proliferated in the past few years.
Cross-lingual learning in the transfer learning taxonomy ( Ruder, 2019 ) Methods from domain adaptation have also been applied to cross-lingual transfer ( Prettenhofer & Stein, 2011 , Wan et al., For a clearer distinction between domain adaptation and cross-lingual learning, have a look at this section. 2018 ; Hartmann et al.,
The idea of low-code was introduced in 2011. Computer vision using the YOLOv7 algorithm – built with Viso Suite What is No Code? has been a leader in AI vision software to create custom computer vision and deep learning applications that process video feeds of numerous cameras in real-time with deployed AI algorithms.
And they may not fit in within your infrastructure, you may have an old infrastructure that can maybe take in basic computer algorithms, not something sophisticated that needs GPUs, and TPUs. So it’s only around 2013, 2011, where AI became a thing in the industry. And neural networks now has become deep learning.
Data mining involves using sophisticated algorithms to identify patterns and relationships in data that might not be immediately apparent. Its ability to efficiently handle iterative algorithms and machine learning tasks made it a popular choice for data scientists and engineers. Follow Now ? Connect with me on LinkedIn for updates.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















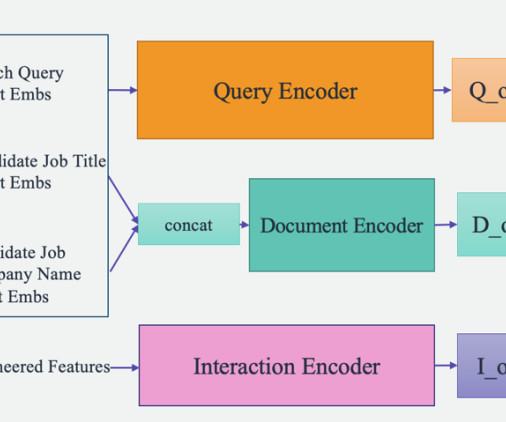
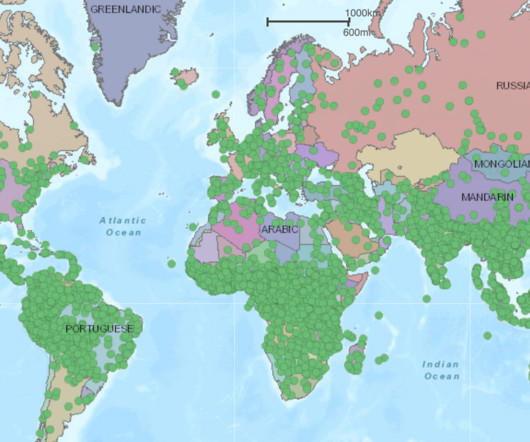
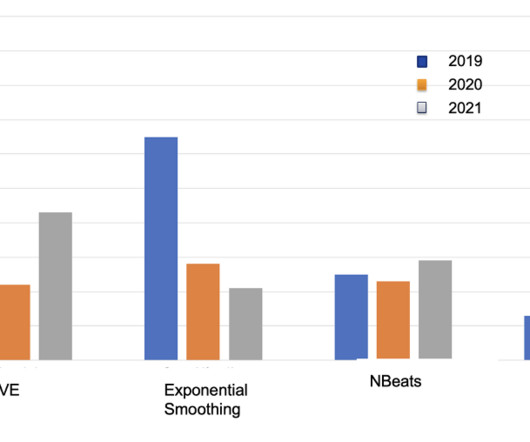






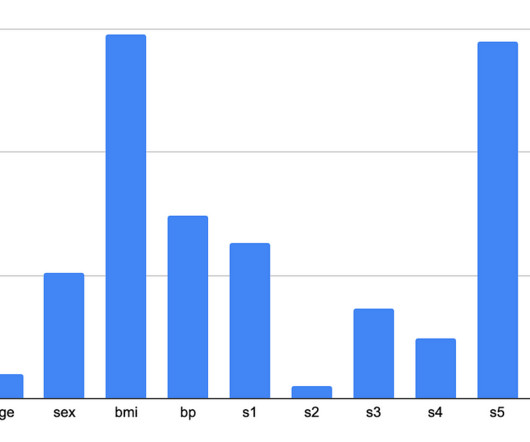












Let's personalize your content